
Net2Net 知識遷移 加速神經網路的訓練
什麼是Net2Net?
Net2Net(Net to Net) 是利用知識遷移來解決大型網路的訓練速度慢的問題,例如先訓練一個小的網路,然後Net2Net,訓練一個更大的網路,訓練更大的網路時可以利用在小網路中已經訓練好的權重,使得再訓練大型的網路速度就變的非常快,利用小網路的權重的這個過程就是知識遷移的過程。
真實場景下的機器學習系統,最終都會變成終身學習系統(Lifelong learning system),不斷的有新資料,通過新的資料改善模型,剛開始資料量小,我們使用小的網路,可以防止過擬合併加快訓練速度,但是隨著資料量的增大,小網路就不足以完成複雜的問題了,這個時候我們就需要在小網路上進行擴充套件變成一個大網路了。
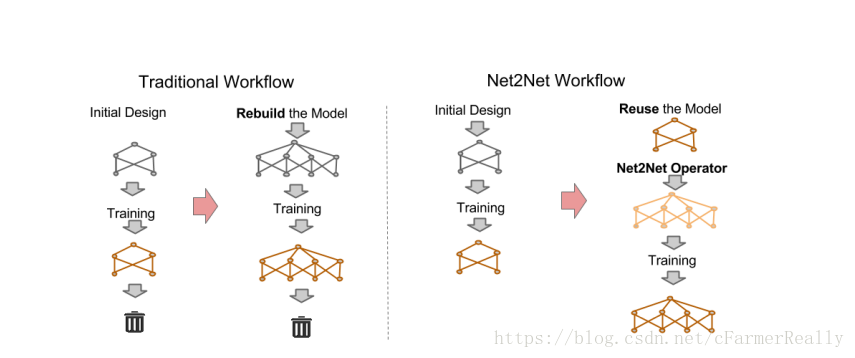
那麼如何操作才能使得網路的拓撲結構改變後還能利用舊網路的權重呢?
改變拓撲結構但是不改變網路的效果,對於同樣的輸入有同樣的輸出。
如何進行Net2Net?
我們定義兩個操作 Net2WiderNet 和 Net2DeeperNet
Net2WiderNet
Net2WiderNet 操作使得某一層更寬,例如讓全連線層有更多的單元,讓卷積層有更多的channel。
我們希望能夠使得這層更寬並且變化後的結構對於同樣的輸入會得到相同的輸出。
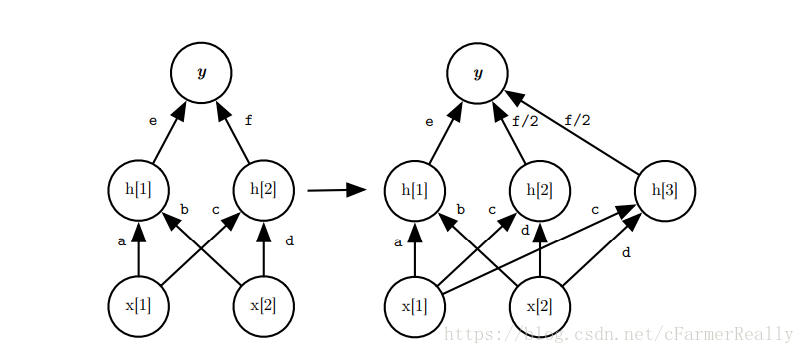
如上圖,對於一個全連線層來說,如果我們新增了一個節點,那麼我們隨機從已有節點中選擇一個節點copy它的輸入權重,使得這個節點的值和已有選擇的節點的值相同,對於輸出的節點來說,需要把前一層的節點的值求和啟用,這時我們發現我們選擇的那個節點的值擴大了兩倍,於是我們可以把他們各自都除以2,這樣我們就實現了全連線層的恆等替換。
對於一個卷積層來說,道理也類似,如果我想增加一個channel,我可以隨機選一個channel然後copy它的權重(filter),對於輸出時要再進行卷積的filter而言,我們把filter中這兩層的channel的權重除以2就可以,這樣也在channel增加的情況實現了恆等替換。
Net2DeeperNet
Net2DeeperNet操作使得我們可以增加一層,例如在一個全連線層後面再加一個全連線層,在一個卷積層後面再加一個卷積層。
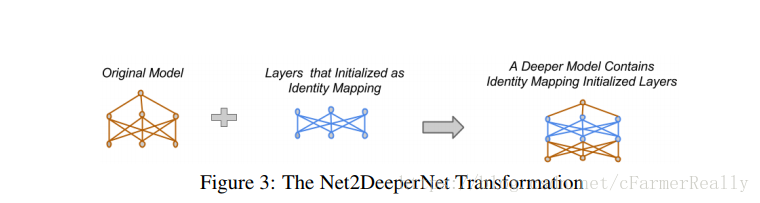
對於一個全連線層來說,我們利用一個單位矩陣做權值,新增一個和上一個全連線層維度完全相同的全連線層,把前一個全連線層的值copy過來,實現恆等對映,此時再結合Net2WiderNet,就可以使這一層再變寬。但是我們可能很難實現把這個層變瘦。
對於一個卷積層來說,我們利用一個只有中間位置是1,其它位置全是0的filter,就很輕鬆的實現了恆等對映。
總結
綜上,我們通過定義兩個操作,實現了從小網路到大網路的轉換,但是我們這個不是一個可以泛化的方法,有一定的侷限性,因為不是所有的情況都有事先恆等對映的方法。
但是對於全連線層和卷積層等來說,我們可以利用如上的方法大大加速大網路的訓練,尤其是在結合終身機器學習系統或者神經網路架構搜尋的方向上。