
SSD:(Single Shot MultiBox Detector)
這兩天把SSD論文讀了一下,SSD也是一個端到端的目標檢測模型,SSD在檢測的準確率和速度上相對於YOLO有了很大的提高,並且在檢測小目標上也有不俗的效果。
特點
1. 使用多尺度特徵圖進行預測
大多數目標檢測演算法都是使用最後一層特徵圖進行目標位置和類別的確定,但是這樣有個缺點就是高層次的特徵圖對小物體的特徵資訊丟失嚴重,導致對小目標檢測效果不好,這也時YOLO對小目標檢測不好的原因之一。所以,SSD不僅使用高層的特徵圖進行預測,還是用了低層的特徵圖進行預測。高層的特徵圖主要負責大目標,底層的特徵圖負責小目標。
SSD網路結構如圖1所示:可以看到新增加的特徵圖大小逐漸減小,而且每個特徵圖的每個卷積核是相互獨立的。

2. 使用卷積進行預測;
SSD直接在特徵圖上使用卷積進行目標位置和類別的預測。對於一個形狀為的特徵圖來說,只需要的小卷積核進行分類和位置的計算。
卷積核在特徵圖的每一個位置上都會產生個輸出值,其中c是類別的個數,加1是因為背景算一個類別,4是位置資訊;位置資訊包含,前兩個表示框的中心點座標,後兩個表示框的長和寬,但是這裡的預測值是相對於先驗框的轉換值。
假設先驗框的位置用表示,邊界框的位置用表示,則該邊界框的預測值用表示。轉換關係為:
從邊界框的真實值到轉換值的過程常稱為編碼;從轉換值到真實值是解碼的過程;解碼關係:
3. 先驗框和寬高比
SSD的先驗框和FasterRCNN的anchor box相似,不同的是在不同的特徵圖上應用不同大小的預設框,這樣做的目的是有效的離散化輸出框的形狀,以滿足真實目標形狀多變的情況。
對於一個大小為的特徵圖來說,特徵圖的每個單元需要個先驗框,則該特徵圖需要個卷積核。
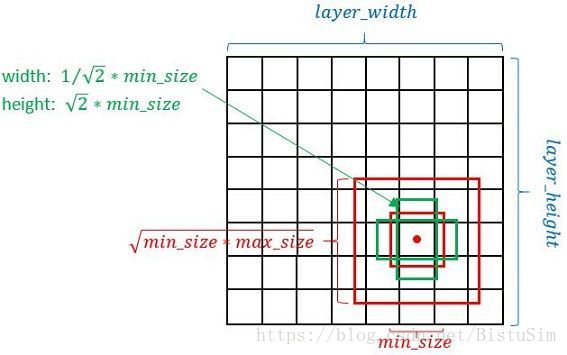
訓練過程
1. 網路結構
SSD使用VGG16網路結構,並且在ILSVRC CLS-LOC訓練集上進行預訓練,但是將fc6和fc7換成了卷積層,從網路結構圖中可以看到conv_6的卷積核大小為,conv_7的卷積核大小為。並且將pool5的核大小由stride=2,改為stride=1,,同時在預訓練過程中使用多孔卷積(atrous algorithm),以增加感受野的大小。除此之外,移除了所有的drop_out。至於超引數的設定,詳見論文。
2. 先驗框的匹配策略
在訓練之前,需要確定圖片中GT Box(ground truth)與哪個先驗框匹配,與之匹配的先驗框所對應的邊界框負責去計算和GTBox的位置損失,邊界框(說白了就是預測框)以先驗框為基準,降低了訓練難度;在YOLO中,由於沒有先驗框,單元框直接預測K個邊界框去擬合真實框,並選擇與真實框IOU最大的邊界框進行預測,使得YOLO模型在訓練中需要自擬合不同物體的多種形狀,提高了訓練的難度。
先驗框的大小隨著不同的位置(此位置我理解的是不同的特徵圖)、長寬比和尺度而不斷變化。
匹配的策略:首先選擇與GT Box具有最大IOU的先驗框作為正樣本;其次,若某個先驗框的的IOU>0.5,也認為是正樣本。這樣使得網路可以對多個先驗框進行預測,可以預測目標的多種形狀。
當先驗框個數很多時,正負樣本之間的數量可能非常不平衡,SSD使用Hard Negative Mining方法將一些負樣本改為正樣本,使正負樣本比例在1:3左右。
Hard Negative Mining方法:首先計算所有先驗框的loss,然後從負樣本中對分類loss降序排列,因為負樣本不計算位置Loss;選擇前m個負樣本,使得正負樣本比例在1:3;將m個負樣本設為正樣本,即計算它的位置Loss,然後進行反向傳播。(這塊我有點疑問,負樣本轉為正樣本後,位置Loss怎麼計算,因為此時沒有對應的GT Box,回去看看原始碼再說)
3.先驗框尺度和長寬比的選擇
為了處理不同物體大小的尺度問題,一些方法是用不同的尺寸的影象進行訓練,然後將結果結合起來。但是SSD將不同層的特徵圖整合起來以達到同樣的效果。
假設使用m個特徵圖進行預測,則每個特徵圖先驗框的尺度大小為:
可以看到隨著特徵圖大小的減小,先驗框尺度線性增加,m是指特徵圖的個數,表示比例的最小值和最大值。SSD中,在實際計算中,先求尺度增長的步長,[],[]代表結果向下取整。[]=17,,即。將這些比例除以100,然後再乘以圖片大小,可以得到各個特徵圖的尺度為,,根據SSD的caffe原始碼,conv4_3比較特殊。所以,SSD中每個特徵圖的先驗框實際尺度是30,60,111, 162,213,264。
對於長寬比的設定,,然後可以計算出相應的長和寬,,。除此之外,還會設定一個尺度為且