
深度學習系列之SSD(Single Shot MultiBox Detector) 個人總結
- Introduction
SSD模型在保證精度的前提下,速度還特別快,可以做到real time。其中原因在於ssd消除了object proposal這個環節。Faster R-CNN是先利用RPN產生object proposal,然後對proposal進行分類和迴歸,所以速度沒有ssd快。
ssd進行檢測的方法是利用卷積後的多個不同尺度的feature map,每個feature map使用固定尺度(不同feature map使用的尺度不同)但不同aspect ratio的anchor。利用這些anchor來進行分類和迴歸,且這裡的分類並不是faster r-cnn的二分類,而是最終的分類
*另有一個備註:文章中的default box可以理解為faster r-cnn中的anchor
- SSD
2.1 model
(1) 利用多尺度feature map進行檢測,這裡的多尺度不是人為縮放的,而是取自不同卷積層的feature map。如圖,後面的每個feature map都直接連上了分類器。
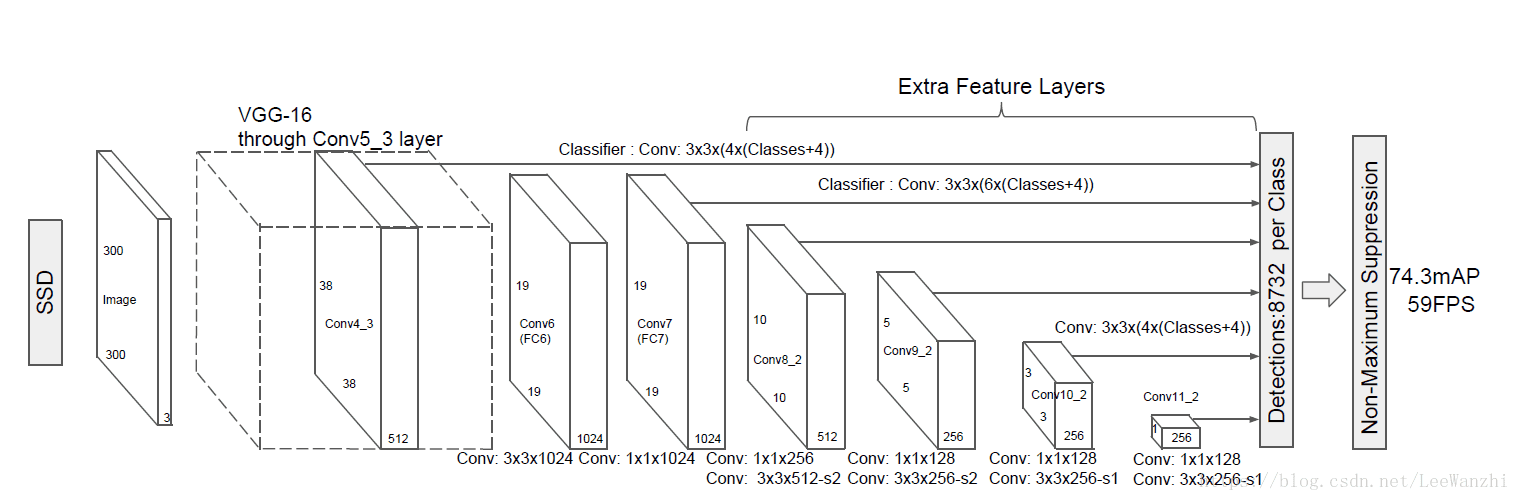
(2) 在feature map的每個位置,有k個anchor(本文是6個)。每個anchor產生C類分數+4個位置偏移量。**這些值是有3x3的不同的小卷積核產生的。**一個卷積和產生一個值。所以每個位置需要(C+4)*k個卷積核。
(3) 對於一張m x n的feature map,需要(C+4)k個卷積核,產生(C+4)k
這種方法可以有效覆蓋image上不同尺度的物體,如圖:
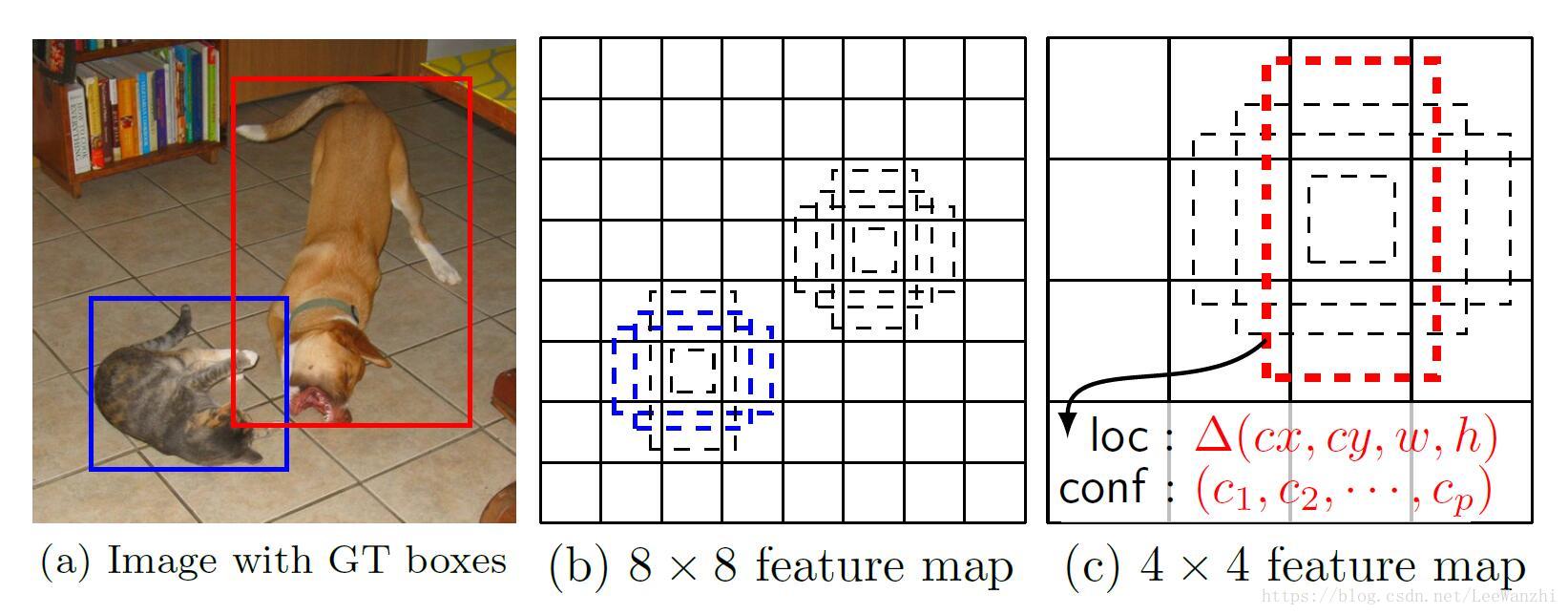
2.2 Training
匹配策略:匹配與GT的IoU(文中的jaccard index傑卡德係數也即IoU)大於0.5的anchor。
loss function:= 置信損失(softmax loss) + 位置損失(smooth L1)
具體公式就不寫了。
另外,我們前面提到,feature map上的每個位置都會產生k個anchor。本文采用的是6個。
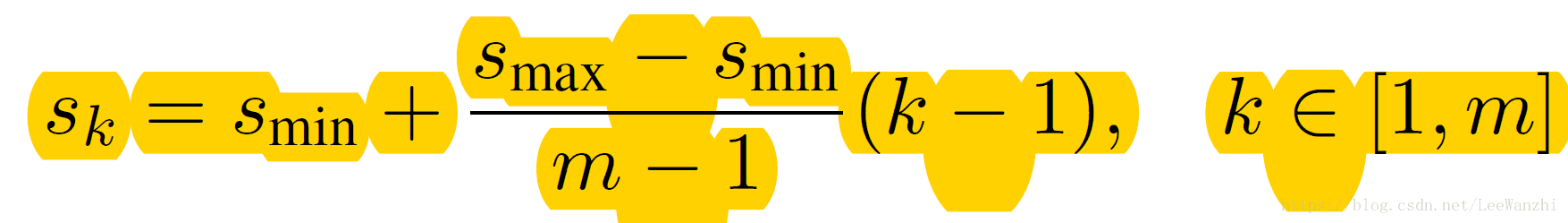
m表示feature map的數量。k是feature map的索引。Smin是最小的scale,Smax是最大的scale。 Sk表示當前feature map採用的scale。
尺度解決了,還有aspect ratio,ar={1,2,3,1/2,1/3}。
anchor的寬Wk = Sk * sqrt(ar),
anchor的高Hk = Sk / sqrt(ar).
對於ar=1時,另外增加一個尺度Sk(extra) = sqrt(Sk * S(k+1))
如此一來,每個位置,產生6個anchor。
hard negtive mining:將false postive存起來(也就是得分高的負樣本存起來),用作訓練時用的負樣本。因為false postive的loss值很大,這樣才能使權重得到較好的更新。如果負樣本中全是易區分的負樣本,則網路學不到有用的東西,權重也無法得到較好的更新。
- 評價
ssd很6,但對於小物體的檢測比較渣。
因為ssd對影象進行了縮放(300x300;512x512),小物體本身就小,一縮放更小,再一卷積池化,資訊幾乎快丟失了。
而faster R-CNN雖然也對影象進行了resize,但只是將最短邊縮放到了600,資訊比ssd豐富。所以faster r-cnn對小物體檢測比ssd好。
文中提到的改進:
(1)將300x300改成512x512,並且證明確實得到了改善。
(2)random crop,對影象進行隨機切割。
(3)對anchor使用更小的尺度和其他不同的寬高比。我覺得可以把尺度降低。
相關推薦
深度學習系列之SSD(Single Shot MultiBox Detector) 個人總結
Introduction SSD模型在保證精度的前提下,速度還特別快,可以做到real time。其中原因在於ssd消除了object proposal這個環節。Faster R-CNN是先利用RPN產生object proposal,然後對proposa
目標檢測之SSD(single shot multibox detector)的pytorch程式碼閱讀總結
confidence:文章中說 根據highest confidence loss,選擇3倍於正樣本數目的負樣本,正樣本根據重合度已經選擇出來了,選擇負樣本先計算這個confidence loss,首先求取預測confidence的log_sum_exp值,再減去其中對應groundtruth的confide
SSD: Single Shot MultiBox Detector 深度學習筆記之SSD物體檢測模型
演算法概述 本文提出的SSD演算法是一種直接預測目標類別和bounding box的多目標檢測演算法。 與faster rcnn相比,該演算法沒有生成 proposal 的過程,這就極大提高了檢
深度學習【50】物體檢測:SSD: Single Shot MultiBox Detector論文翻譯
SSD在眾多的物體檢測方法中算是比較重要的。之前學習過,但是沒過多久就忘了,因此決定將該論文翻譯一下,以加深印象。 Abstract 我們提出了用單個深度神經網路進行物體檢測的方法,稱為SSD。在每個特徵圖中的每個位置,SSD將bbox(bounding
【深度學習:目標檢測】RCNN學習筆記(10):SSD:Single Shot MultiBox Detector
之前一直想總結下SSD,奈何時間緣故一直沒有整理,在我的認知當中,SSD是對Faster RCNN RPN這一獨特步驟的延伸與整合。總而言之,在思考於RPN進行2-class分類的時候,能否借鑑YOLO並簡化faster rcnn在21分類同時整合faster rcnn中anchor boxes實現m
SSD(Single Shot MultiBox Detector):create_list.sh io.cpp:187 Could not open or find file
今天在為SSD訓練自己的資料時執行caff/data/VOC0712/create_list.sh時報了好多這個錯誤: E0412 16:28:31.653440 5008 io.cpp:187] Could not open or find file
SSD(Single Shot MultiBox Detector)的solver引數 test_initialization的說明塈解決訓練時一直停在Iteration 0的問題
前陣子訓練過一次SSD模型,訓練後發現數據集有問題,修改了資料集後,今天準備再做一次SSD訓練時,如下執行訓練程式碼: python ./examples/ssd/ssd_pascal.py 到了開始迭代時,一直停在Iteration 0,進行不下去。
《SSD: Single Shot MultiBox Detector》論文筆記
1. 論文思想 SSD從網路中直接預測目標的類別與不同長寬比例的邊界框。在這篇論文中提出的方法(SSD)並沒有為邊界框假設重取樣畫素或是特徵,但是卻達到了使用這種方案檢測模型的精度。在VOC 2007的測試集上跑到了mAP74.3% 59 FPS(在後來改進資料增廣的方法,在VOC
SSD: Single Shot MultiBox Detector翻譯(包括正式版和預印版)(對原文作部分理解性修改)
預印版表7 表7:Pascal VOC2007 test上的結果。SSD300是唯一的可以實現超過70%mAP的實時檢測方法。通過使用大輸入影象,在保持接近實時速度的同時,SSD512在精度上優於所有方法。 4、相關工作 目前有兩種已建立的用於影象中物件檢測的方法,一種基於
SSD( Single Shot MultiBox Detector)關鍵原始碼解析
SSD(SSD: Single Shot MultiBox Detector)是採用單個深度神經網路模型實現目標檢測和識別的方法。如圖0-1所示,該方法是綜合了Faster R-CNN的anchor box和YOLO單個神經網路檢測思路(YOLOv2也採用了類似的思路,詳見YOLO升級版:YOLOv2和YO
SSD:(Single Shot MultiBox Detector)
這兩天把SSD論文讀了一下,SSD也是一個端到端的目標檢測模型,SSD在檢測的準確率和速度上相對於YOLO有了很大的提高,並且在檢測小目標上也有不俗的效果。 特點 1. 使用多尺度特徵圖進行預測 大多數目標檢測演算法都是使用最後一層特徵圖進行目標位置和類
[論文閱讀]SSD Single Shot Multibox Detector
SSD Single Shot Multibox Detector Code: https://github.com/balancap/SSD-Tensorflow SSD 是ECCV 2016的文章,文章主要提出了一種新的framework來完成object detec
SSD:Single Shot MultiBox Detector 論文筆記
資料增廣(Data augmentation)對於結果的提升非常明顯 Fast R-CNN 與 Faster R-CNN 使用原始影象,以及 0.5 的概率對原始影象進行水平翻轉(horizontal flip),進行訓練。如上面寫的,本文還使用了額外的 sampling 策略,YOLO 中還使用了 亮度
論文筆記 | SSD: Single Shot MultiBox Detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg Wei Liu Abstract
SSD: Single Shot MultiBox Detector in TensorFlow(翻譯)
一、環境配置 基本環境:Windows 10 + GTX950M 1、安裝Anaconda3() 注意:必須下載Anaconda3,因為Anaconda3對應Python3.x,而Windows下Tensorflow只支援Pyt
基於 SSD: Single Shot MultiBox Detector 的人體上下半身檢測
基於 SSD 的人體上下半身檢測 這裡主要是通過將訓練資料轉換成 Pascal VOC 資料集格式來實現 SSD 檢測人體上下半身. 由於沒有對人體上下半身進行標註的資料集, 這裡利用 MPII Human Pose Dataset 來將 Pose 資料轉
論文閱讀:SSD: Single Shot MultiBox Detector
Preface 有幾點更新: 1. 看到一篇 blog 對檢測做了一個總結、收集,強烈推薦: Object Detection 2. 還有,今天在微博上看到 VOC2012 的榜單又被重新整理了,微博原地址為:這裡,如下圖: 3. 目前 voc
SSD: Single Shot MultiBox Detector 檢測單張圖片
前言 博主也算是剛開始研究SSD專案,之前寫了一篇SSD:Single Shot MultiBox Detector的安裝配置和執行,這次是簡單介紹下如何用SSD檢測單張圖片,其實過程也比較簡單,下面正式開始。 準備工作 當然,首先你要把SSD按照教程
論文閱讀筆記:SSD: Single Shot MultiBox Detector
1 介紹當前目標檢測系統都是下列方法的變體:假定邊界框(hypothesizebounding boxes),對每個方框進行重取樣畫素或者特徵,應用一個高質量的分類器。這種流程在檢測基準(detectionbenchmarks)上盛行,因為選擇性搜尋在PASCAL VOC,COCO和ILSVRC檢測上的效果最
SSD: Single Shot MultiBox Detector 訓練KITTI資料集(1)
前言 之前介紹了SSD的基本用法和檢測單張圖片的方法,那麼本篇部落格將詳細記錄如何使用SSD檢測框架訓練KITTI資料集。SSD專案中自帶了用於訓練PASCAL VOC資料集的指令碼,基本不用做修改就可以輕鬆完成訓練;但是想要訓練其他資料集比如KITTI,則