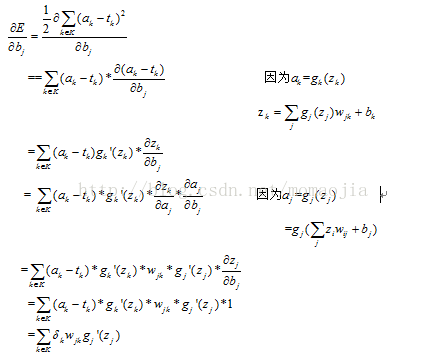神經網路及反向傳播(bp)演算法詳解
神經元和感知器的本質一樣神經元和感知器本質上是一樣的,只不過感知器的時候,它的啟用函式是階躍函式;而當我們說神經元時,啟用函式往往選擇為sigmoid函式或tanh函式。如下圖所示:
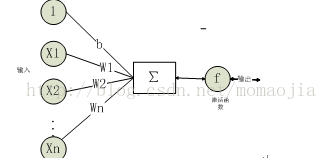
輸入節點
每一個輸入節點對應一個權值,輸入節點可以是任意數。
權重 W1,W2...Wn
偏置項 b
啟用函式
啟用函式在神經網路中尤為重要,通過啟用函式加入非線性因素,解決線性模型所不能解決的問題。計算啟用函式的梯度,反向傳播的誤差訊號以此來更新優化引數。
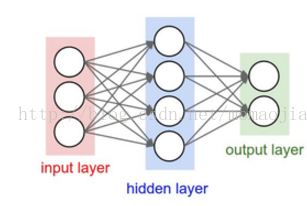
常見的普通神經網路,是一個全連線層。下圖為一個普通的全連線網路,層與層之間完全連線,同一個層內神經元之間無連線。當我們說N層神經網路時,通常除去輸入層,因此單層神經網路就是沒有隱層的神經網路(輸入到輸出)。下圖為一個2層的神經網路,隱藏層由4個神經元組成,輸出由2個神經元組成。
計算一個神經元的方法:
對輸入求加權和:
神經網路的學習也稱為訓練,主要使用有指導的學習,根據給定的訓練樣本,調整引數以使得網路接近已知樣本的類標記。神經網路的訓練主要包括兩個部分:正向傳播和反向傳播兩個過程。正向傳播得到損失值,反向傳播得到梯度。最後通過梯度值完成權值更新。所謂梯度其實就是一個偏導數向量,但是我們經常說的仍是‘x的梯度’而不是‘x的偏導數’。下面首先通過一個例子來說明神經網路訓練的過程。網路結構圖如下:
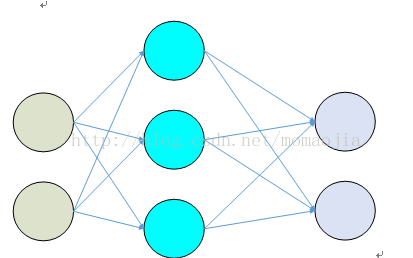
假設神經網路的輸入層次依次為i,j,k,第一層的輸出,即隱藏層的輸入,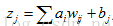
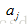
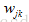 相乘,並加入偏置
相乘,並加入偏置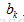 ,最終整個網路的輸出值為
,最終整個網路的輸出值為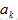 。這個輸出值將與期望的目標值
。這個輸出值將與期望的目標值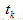 比較,得到一個誤差,神經網路訓練的目的,就是找到引數w,b使得誤差最小。其中上述
比較,得到一個誤差,神經網路訓練的目的,就是找到引數w,b使得誤差最小。其中上述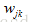 表示第j層到第k層的權重。我們取誤差平方和作為目標函式,定義如下:
表示第j層到第k層的權重。我們取誤差平方和作為目標函式,定義如下:
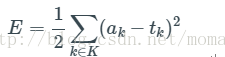
尋找這個引數的方法採用梯度下降法,即計算所有引數的梯度(偏導數)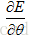
假設神經網路的結構圖如下:
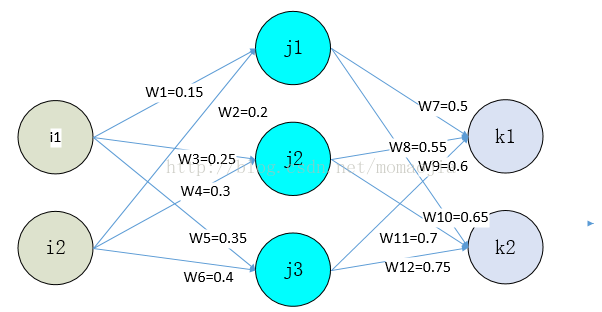
輸入資料:i1=0.05, i2=0.1
輸出資料:k1=0.01, k2=0.99
偏置 bj=1,所對應的初始權重為0.45
bk=1,所對應的初始權重為0.85
啟用函式: sigmoid函式
初始權重為上述所標識的
一. 前向傳播
1 .輸入層到隱藏層:
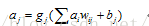
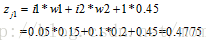
神經元j1的輸出值為:
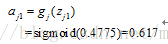
同理,可以計算
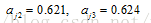
2.隱藏層到輸出層:
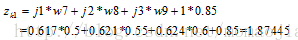 神經元k1的輸出值為:
神經元k1的輸出值為:
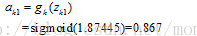 同理,可以計算
同理,可以計算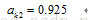 至此,我們得到神經網路輸出值為【0.867,0.925】與實際值【0.01,0.99】相差甚遠
分別計算k1,k2的誤差,總誤差為兩者之和:
至此,我們得到神經網路輸出值為【0.867,0.925】與實際值【0.01,0.99】相差甚遠
分別計算k1,k2的誤差,總誤差為兩者之和:
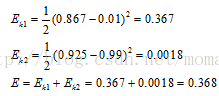 接下來進行反向傳播,通過求梯度,更新權值。
接下來進行反向傳播,通過求梯度,更新權值。
二. 反向傳播
1. 計算權重矩陣的梯度
求權重的梯度,要分為輸出層和隱藏層兩種情況。根據上圖的兩層神經網路,下面寫出了具體的推導過程(下列所有標識都是矩陣形式)。
1.1 輸出層的權重矩陣
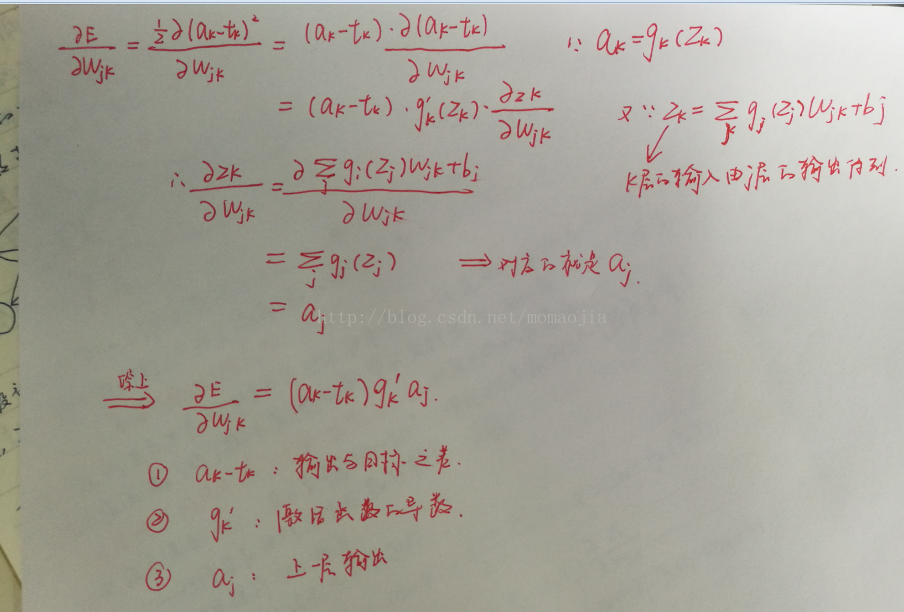
如果定義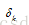
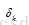
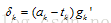
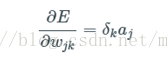 所以輸出權重的更新公式為:
所以輸出權重的更新公式為: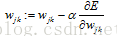 其中a為學習率。
其中a為學習率。
1.2 隱藏層的權重矩陣
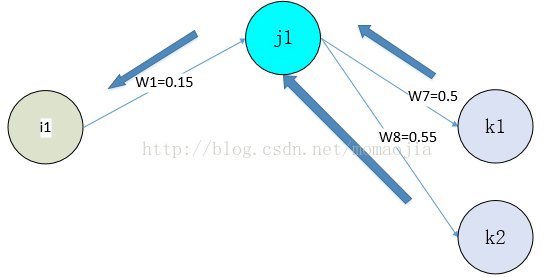 因為隱藏層與輸出之間不是直接關聯,所以計算過程也就更加複雜。上圖為部分反向傳播的過程,對於神經元j1而言,其反向傳播主要來自k1和k2,所以
因為隱藏層與輸出之間不是直接關聯,所以計算過程也就更加複雜。上圖為部分反向傳播的過程,對於神經元j1而言,其反向傳播主要來自k1和k2,所以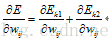 (這是輸出為兩個節點的情況),所以一般而言,隱藏層的梯度為:
(這是輸出為兩個節點的情況),所以一般而言,隱藏層的梯度為:
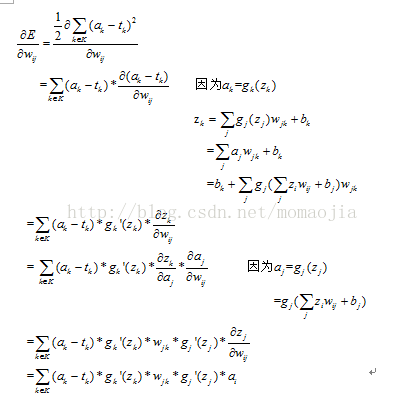 又因為:
又因為:
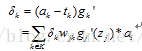
2. 計算偏置b的梯度
2.1 輸出層偏置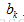 的梯度
的梯度
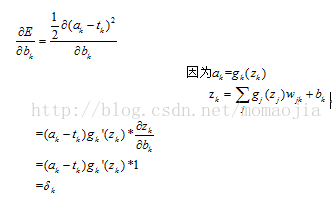
2.2 隱藏層偏置的梯度