
前向神經網路和 BP 演算法詳解 --- 之 DNN
阿新 • • 發佈:2019-01-01
前向神經網路和 BP 演算法詳解
一、神經網路的概念詳解
1.1、人工神經網路的基礎單元 — > 感知機
1.1.1、感知機模型講解
- 首先我們需要明確一點就是,針對於擁有核函式的 SVM 或者多隱層 + 啟用函式的多層神經網路,或者其他可以處理非線性可分的模型來說,感知機我們常稱為神經元,但也可以看成是兩層的神經網路( 即只有輸入層和輸出層,沒有隱層 ),雖然它只能處理線性可分問題,但它依然是我們學習神經網路和深度學習的基石。

- 圖中對應的符號含義如下:
- 輸入(x1 ,…,xn)
- 偏移b 和 突觸權重(w1 ,…,wn),注意,我們下面推到是使用 代替 wi 進行公式推導。
- 組合函式c(·)
- 啟用函式a(·)
- 輸出y
- 用數學的語言來說,如果我們有m個樣本,每個樣本對應於n維特徵和一個二元類別輸出,如下:
- 我們的目的便是找一個超平面,即: 讓把每個類別的樣本特徵帶入該方程時,要麼大於 0 ,要麼小於 0,從而使得樣本分居在超平面兩側,從而到達線性可分。一般如果樣本線性可分,則這樣的超平面會有多個解,不唯一。
- 為了簡化模型,我們增加一個 x0 = 1,使得超平面方程簡寫為 進一步可寫向量形式為 其中 和 X 均為 n * 1 的向量,為內積,下面我們都用它表示超平面。
- 故感知機的模型可以定義為 ,其中sign 為啟用函式,它是符號函式,也稱為階躍函式。
- 在多層神經網路中,我們可能用到其他的啟用函式,如下:
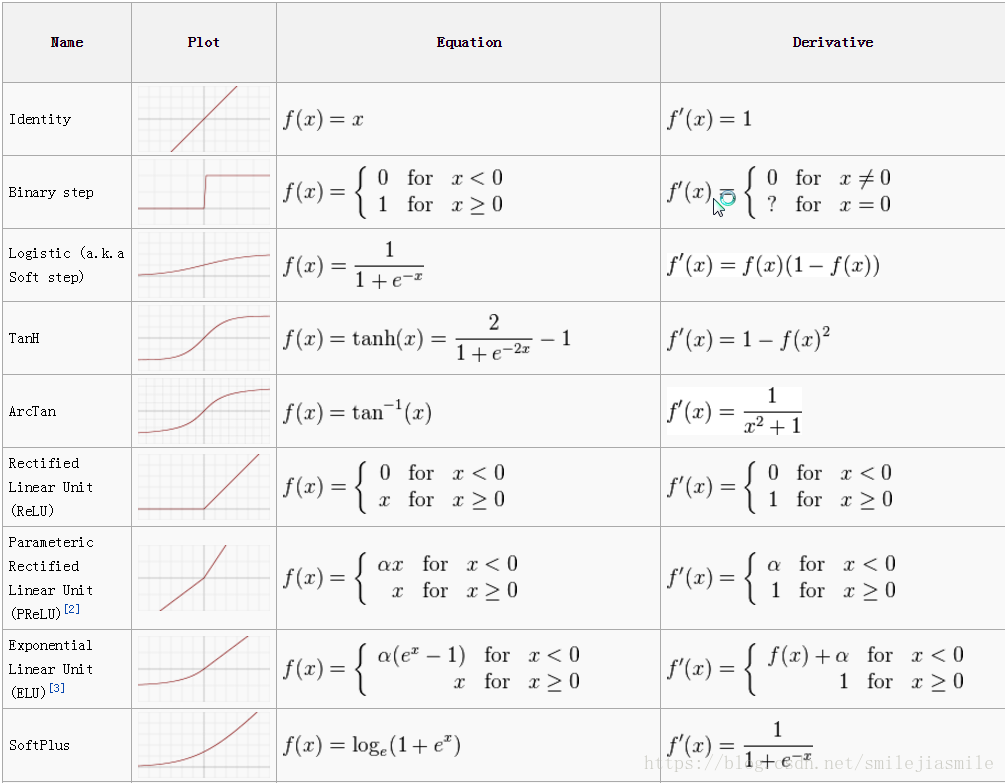
1.1.2 感知機模型損失函式
- 根據上面的分析,我們將 的樣本類別輸出值取為1 ,而小於 0 的樣本類別取為 -1,這樣定義它的好處便是方便我們定義損失函式。因為有了上面的約定,正確分類的樣本滿足: ,而錯誤的分類樣本滿足 。於是損失函式的優化方法便是期望使誤分類的所有樣本,到超平面的距離之和最小(即想讓誤分類樣本逐漸消失)。
- 由於,所以對於每一個誤分類的樣本 i,到超平面的距離為:
- 其中, 為 L2範數。(若此處距離公式不理解,可自行查閱點到直線的距離,或者學習相關的機器學習相關章節)
- 接著,我們假設所有誤分類的點的集合為M,則所有誤分類的樣本到超平面的距離之和為: