
幾大分佈:正態分佈、卡方分佈、t分佈、F分佈整理
一、正態分佈
正態分佈(Normal distribution)又名高斯分佈(Gaussiandistribution),若隨機變數X服從一個數學期望為μ、方差為σ^2的高斯分佈,記為N(μ,σ^2)。其概率密度函式為正態分佈的期望值μ決定了其位置,其標準差σ決定了分佈的幅度。我們通常所說的標準正態分佈是μ = 0,σ = 1的正態分佈。
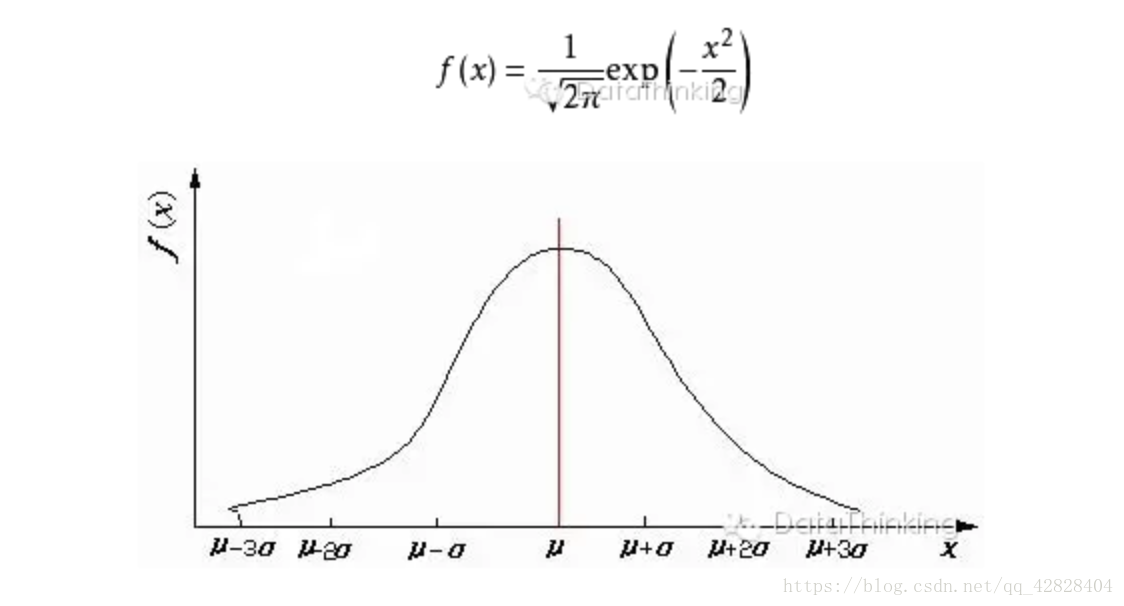
二、卡方分佈

三、t分佈
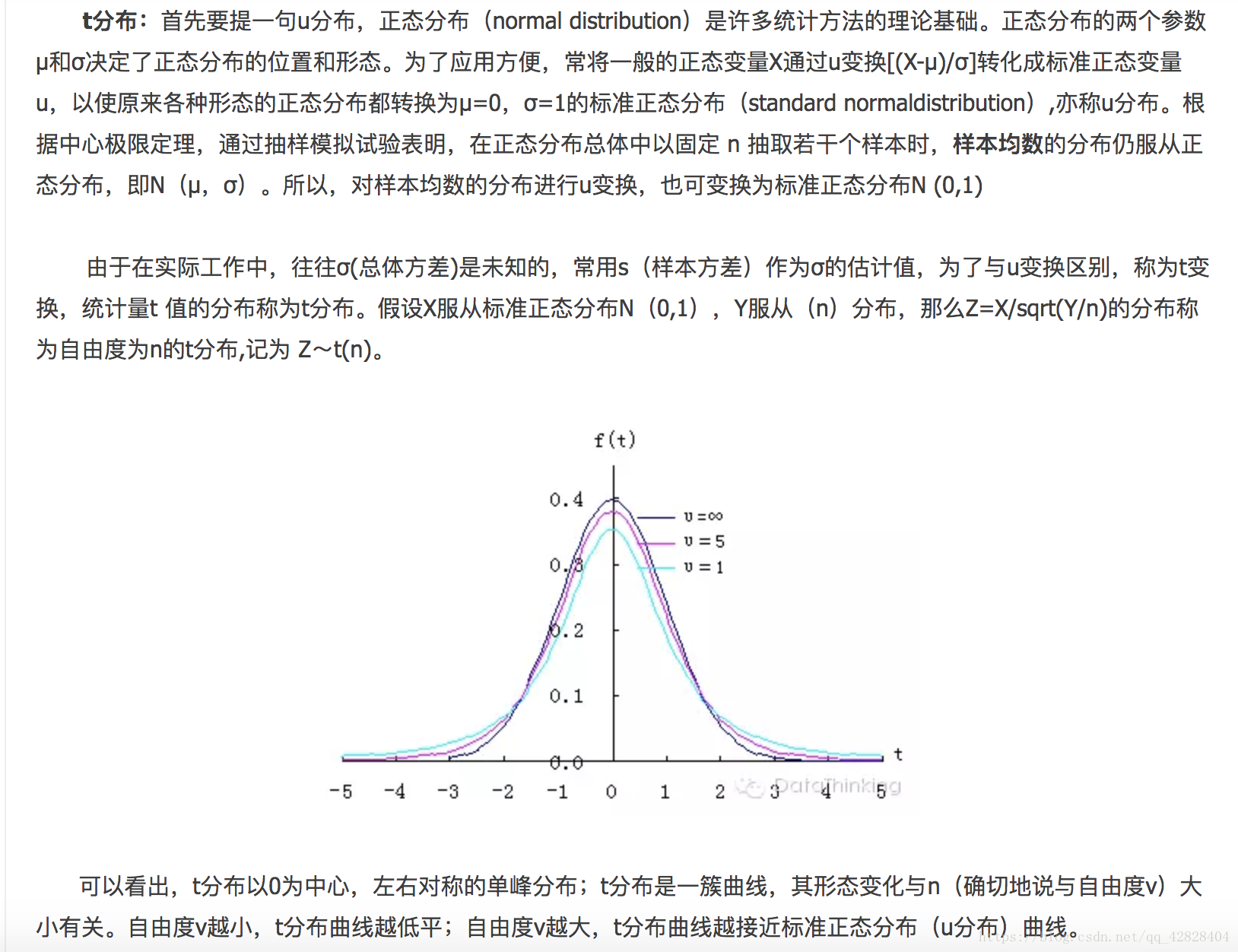
四、F分佈
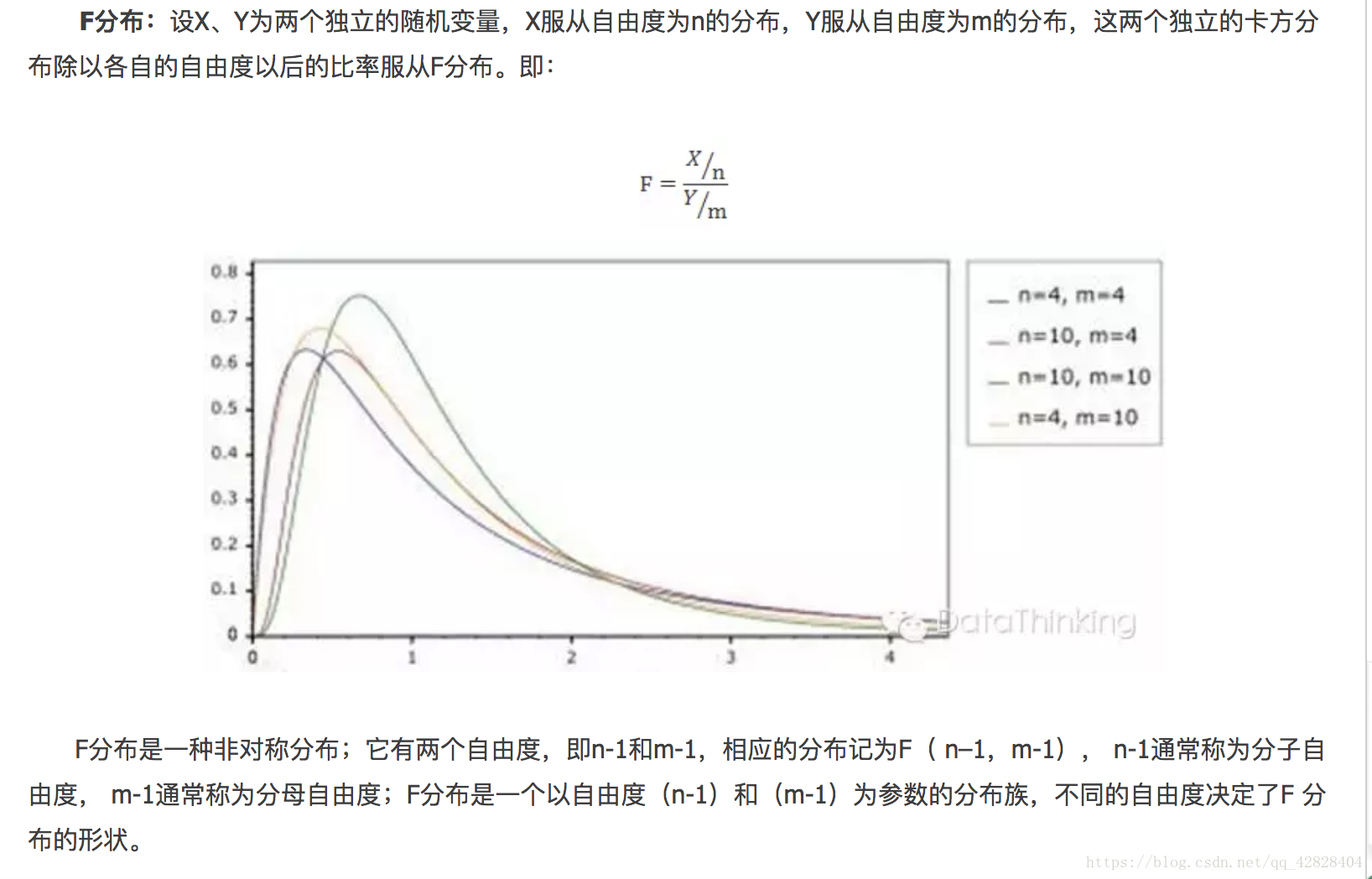
應用場景:
Z就是正態分佈,X^2分佈是一個正態分佈的平方,t分佈是一個正態分佈除以(一個X^2分佈除以它的自由度然後開根號),F分佈是兩個卡方分佈分佈除以他們各自的自由度再相除
比如X是一個Z分佈,Y(n)=X1^2+X2^2+……+Xn^2,這裡每個Xn都是一個Z分佈,t(n)=X/根號(Y/n),F(m,n)=(Y1/m)/(Y2/N)
各個分佈的應用如下:
方差已知情況下求均值是Z檢驗。
方差未知求均值是t檢驗(樣本標準差s代替總體標準差R,由樣本平均數推斷總體平均數)
均值方差都未知求方差是X^2檢驗
兩個正態分佈樣本的均值方差都未知情況下求兩個總體的方差比值是F檢驗。
相關推薦
幾大分佈:正態分佈、卡方分佈、t分佈、F分佈整理
一、正態分佈 正態分佈(Normal distribution)又名高斯分佈(Gaussiandistribution),若隨機變數X服從一個數學期望為μ、方差為σ^2的高斯分佈,記為N(μ,σ^2)。其概率密度函式為正態分佈的期望值μ決定了其位置,其標準差σ
【程式設計師眼中的統計學(7)】正態分佈的運用:正態之美
作者 白寧超 2015年10月15日18:30:07 摘要:程式設計師眼中的統計學系列是作者和團隊共同學習筆記的整理。首先提到統計學,很多人認為是經濟學或者數學的專利,與計算機並沒有交集。誠然在傳統學科中,其在以上學科發揮作用很大。然而隨著科學技術的發展和機器智慧的普及,統計學在機器智慧中的作用越來
均勻分佈差生正態分佈
文章目錄 中心極限定理 中心極限定理 中心極限定理是說,n只要越來越大,這n個數的樣本均值會趨近於正態分佈,並且這個正態分佈以u為均值,sigma^2/n為方差。 換句話說,假設我們與樣本
MATLAB實現由均勻分佈產生正態分佈和銳利分佈
xaxis=-10:0.1:10; miu=0; delta=1; N=1000000; u1=rand(1,N); u2=rand(1,N); y1=(-2*log(u1)).^0.5; y2=
統計學三大分佈與正態分佈的關係
三大抽樣分佈:卡方分佈,F分佈,t分佈 這三個分佈都是基於正態分佈變形得到的,在實際中只能用來做假設檢驗。比如,已知樣本X都是服從正態分佈的樣本,而且方差未知,那麼,檢驗X的均值就會用到t分佈,其他的情況也類似 以X^2分佈為例子 x1,x2..xn都遵守
Excel圖表—二項分佈和正態分佈的對應關係
問題:假定某二項分佈對應引數為n=500, p=0.4,試分析與該二項分佈具有相同均值和標準差的正態分佈於該二項分佈的漸進關係。 結論:在實驗次數較大時(n=500),二項分佈已經與正態分佈基本
概率演算法-均勻分佈產生正態分佈
大部分語言只能產生均勻分佈的隨機數。C語言用(double)rand()/RAND_MAX產生0到1之間均勻分佈的隨機數。那麼如何產生正態分佈的呢? 一般,一種概率分佈,如果其分佈函式為y=F(x),那麼,y的範圍是0~1,求其反函式G,然後產生0到1之間的隨
統計分析之:正態性檢驗——SPSS操作指南
在進行統計分析時,研究者們經常遇到不能確定總體分佈的情況,SPSS的正態性檢驗可以幫助解決這一問題。 先來看一下什麼是正態性檢驗。利用觀測資料判斷總體是否服從正態分佈的檢驗稱為正態性檢
TensorFlow入門教程:17:正態噪聲下的線性迴歸
這篇文章來看一下,使用加入正態分佈的噪聲之後產生的資料進行訓練,看是否能夠得到期待的結果。 事前準備 訓練資料使用如下方式生成: xdata = np.linspace(0,1,100) ydata = 2 * xdata + 1 + np.random.no
漫步數理統計二十四——伽瑪、卡方與貝塔分佈
本篇博文我們講介紹伽瑪(Γ),卡方(χ2)與貝塔(β)分佈。在高等微積分中已經證明過,對於α>0,積分 ∫∞0yα−1e−ydy 存在且積分值為正數,這個積分稱為α的伽瑪函式,寫成 Γ(α)=∫∞0yα−1e−ydy 如果α=1,顯然 Γ(1)=
SPSS:T檢驗、方差分析、非參檢驗、卡方檢驗的使用要求和適用場景
一、T檢驗 1.1 樣本均值比較T檢驗的使用前提 正態性;(單樣本、獨立樣本、配對樣本T檢驗都需要) 連續變數;(單樣本、獨立樣本、配對樣本T檢驗都需要) 獨立性;(獨立樣本T檢驗要求) 方差齊性;(獨立樣本T檢驗要求) 1.2 樣本均值比較T
統計學常用概念:T檢驗、F檢驗、卡方檢驗、P值、自由度
1,T檢驗和F檢驗的由來 一般而言,為了確定從樣本(sample)統計結果推論至總體時所犯錯的概率,我們會利用統計學家所開發的一些統計方法,進行統計檢定。 通過把所得到的統計檢定值,與統計學家建立了一些隨機變數的概率分佈(probability distribution)進
卡特蘭數(catalan數)總結 (卡特蘭大數、卡特蘭大數取模、卡特蘭數應用)
本文講解卡特蘭數的各種遞推公式,以及卡特蘭數、卡特蘭大數、卡特蘭大數取模的程式碼實現,最後再順帶提一下卡特蘭數的幾個應用。 什麼是卡特蘭數呢?卡特蘭數無非是一組有著某種規律的序列。重要的是它的應用。
課堂練習--計算陣列的最大值,最小值,平均值,標準差,中位數;numpy.random模組提供了產生各種分佈隨機數的陣列;正態分佈;Matplotlib
#計算陣列的最大值,最小值,平均值,標準差,中位數 import numpy as np a=np.array([1, 4, 2, 5, 3, 7, 9, 0]) print(a) a1=np.max(a) #最大值 print(a1) a2=np.min(a) #最小值 print(a2) a3
PyTorch 生成隨機數Tensor(標準分佈、標準正態、離散正態……)
在使用PyTorch做實驗時經常會用到生成隨機數Tensor的方法,比如: torch.rand() torch.randn() torch.normal() torch.linespace() 均勻分佈 *torch.rand(sizes, out=None) → Tensor
【114】Python小例子:numpy.random.randn生成符合正態分佈的資料,並畫出正態分佈的鐘曲線。
自己學習python 隨手寫的一個小例子。先利用 numpy.random.randn生成符合正態分佈的資料,然後再給這些資料畫正態分佈的曲線圖。 import numpy as np impor
C#產生正態分佈、泊松分佈、指數分佈、負指數分佈隨機數(原創)
http://blog.sina.com.cn/s/blog_76c31b8e0100qskf.html 在程式設計過程中,由於資料模擬模擬的需要,我們經常需要產生一些隨機數,在C#中,產生一般隨機數用Random即可,但是,若要產生服從特定分佈的隨機數,就需要一定的演
C++生成隨機數:高斯/正態分佈(gaussian/normal distribution)
常用的成熟的生成高斯分佈隨機數序列的方法由Marsaglia和Bray在1964年提出,C++版本如下: #include <stdlib.h> #include <math.h> double gaussrand() { static double V1, V2, S
R語言:生成正態分佈資料生成--rnorm,dnorm,pnorm,qnorm
norm是正態分佈,前面加r表示生成隨機正態分佈的序列,其中rnorm(10)表示產生10個數;給定正太分佈的均值和方差, Density(d), distribution function§, quantile function(q) and random® generation
統計學學習筆記:(五)正態分佈
正態分佈:二項分佈極好的近似 X是隨機變數,E(X)是期望值。正態分佈(normal distribution)也稱為高斯分佈(Gaussian distribution),或者鐘形曲線(bell curve)。 (x-μ)/σ也稱為z score(注意:z score是個通用的概念,包括非正態分佈)。因