
另闢蹊徑的歸併排序複雜度分析
筆者,特別地對歸併排序的
複雜度進行了分析;
看了好多部落格,只是簡單的說了下結論,結論怎麼來的,根本不去分析,寫部落格跟沒寫似的,,更氣人的是,還有抄書的,書上寫啥,部落格就寫啥,浪費時間,這種部落格,寫的人、看的人,時間都被浪費了;
目錄
歸併排序
先了解下歸併排序中歸併的意思;
歸併:即將兩個有序的陣列,合併為一個更大的有序的陣列 ;
思想:要想將一個大陣列排序,我們可以將大陣列分為兩個小的陣列,對這個小的陣列進行排序,然後將兩個小的有序的陣列,歸併 到一個大的陣列中;遞迴 這個過程,直到小的陣列中元素 只有一個,然後進行歸併;
缺點(使用‘原地歸併’
從上面的 思想 裡面,我們可以知道,歸併排序 是一個使用 遞迴 的排序演算法;而說到遞迴,就會想到每次遞迴需要的 空間;
就像我們上面說的一樣,每次歸併兩個小陣列的時候,都建立一個新的陣列(申請新的記憶體空間),將歸併的結果放到裡面;這樣做,當需要進行排序的陣列的長度,很小的時候,沒有什麼問題;
但是,需要排序的陣列的長度很大的時候,我們需要遞迴的次數,也就隨之變多,這樣一個遞迴排序需要的空間,就急劇增加,是我們不能忍受的 ;
這裡我們可以將使用的空間降低到最低,就是每次遞迴,進行歸併兩個小的陣列的時候,我們並不建立新的陣列,來儲存歸併的結果 ;而是在遞迴開始的時候,建立一個跟需要排序的陣列一樣大的陣列,在每次遞迴的時候,先把兩個小數組裡面的元素,複製進這個大數組裡面,而將歸併的結果,放回小數組裡面
但是,還是避免不了最少使用 N 個額外的陣列空間 ;這裡的原地,並不是真正的原地 ;還是需要最少 N 個額外空間 ;
上述思想是一種
原地排序的思想;
java程式碼實現
歸併排序有兩種實現方式,這是其一:自頂向下的歸併排序
package cn.yaz.study.sort._2_2;
import cn.yaz.study.sort._2_1.Example;
import org.junit.Test;
/**
* 歸併排序(自頂向下的歸併排序)
*/
public class Merge {
@Test Example類,請見 ;
複雜度分析
我看了好多部落格,根本不對複雜度進行分析,只是直接寫出結論,沒意思;
先分析 比較次數
遞迴樹
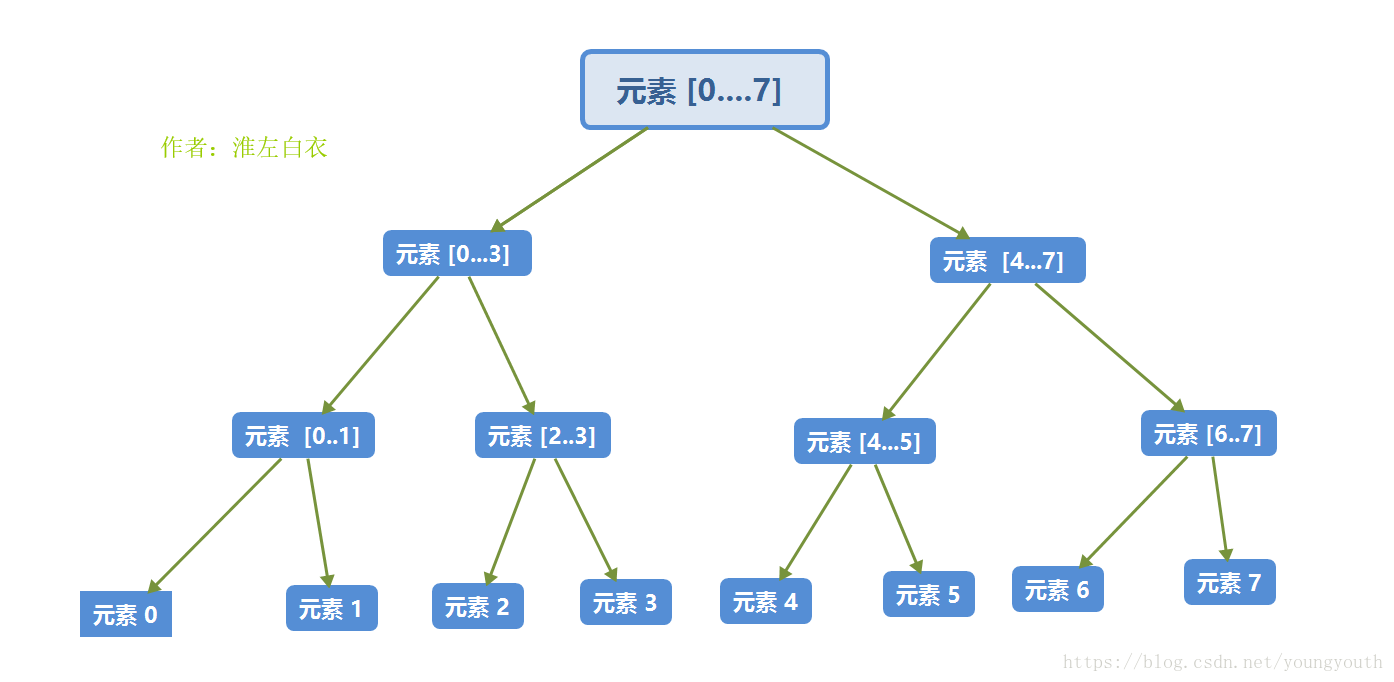
(K從0開始計數)第K層,有 個子陣列 ;每個子陣列有 個元素,對於有 個元素的陣列,最多需要比較 次;第 K 層,需要 x = 次比較;( n = N是陣列元素的總數,因此,這裡也就是 N 次比較 ;)
這裡說的,都是書上的話,看了也不定記得!反正筆者是沒記住
擦!正在我苦苦思索,怎麼用語言把比較次數直白的、簡單的、容易記住的 描述出來的時候,我突然發現,遞迴樹,每層元素都是一樣多的,都是N個元素,而我們為N個元素進行排序的時候,最多需要N次比較;so,只要知道遞迴樹有多少層就可以求出一共比較了多少次了;很容易推匯出,N 個元素的陣列的 二分遞迴樹 一共有 層(根節點除外,學過高中數學就可以推匯出)
因此一共比較了 N x = N 次;
上述說的比較次數是最壞情況下,因為,陣列的個數是2的冪,此時遞迴樹是一個完全二叉樹;
假如,陣列的不是2的冪,則 遞迴樹,將不是 一個完全二叉樹,最後一層的元素,就將比 N 少,因此,最後一層的比較次數,比 N 少;
因此,總體上是 小於 N 次
再分析 訪問陣列次數
我另闢蹊徑,還是從,遞迴樹,每層元素都是一樣多的,都是N個元素,這個角度入手
訪問陣列的操作,只發生在 merge( ) 方法裡面,而遞迴樹的每層的每一個元素,都是要經過 merge( ) 方法的,在 merge( ) 方法裡面,N 個元素,需要 N 次 複製,N 次賦值,最多需要 N 次比較,我們在 merge( ) ,一共有 兩個陣列 ,每次訪問都是一起訪問,因此,訪問陣列 3N x 2 = 6N 次,而我們一共有 層;
因此,一共訪問 6N 次陣列 ;
master定理
對於這種遞迴的複雜度,找不到合理的方法,幹推,太鬧心了,如果不想推導,可以直接使用 master定理 ;
master定理
遞迴關係: T(n) = a*T(n/b)+c*n^k ;T(1) = c ;有這樣的結論:
if (a > b^k)——T(n) = O(n^(logb(a)))if (a = b^k)——T(n) = O(n^k*logn)if (a < b^k)——T(n) = O(n^k)
sort(comparables, lo, (lo + hi) / 2); //
sort(comparables, (lo + hi) / 2 + 1, hi);
merge(comparables, lo, hi);
我們寫的程式碼的 遞迴狀態方程:這裡又需要寫出 遞迴狀態方程 。。。。。不寫了!(感興趣的同學,自己去看專門介紹 master定理 的部落格,這裡我還是重點講 歸併排序 的)
改進
演算法第四版的課後作業,有下面的題,我會把程式碼放到我寫的
《演算法第四版-課後習題答案》,裡面,需要的同學,可以去檢視下 ;
我們可以對上述的程式碼,進行改進,提高歸併排序的效能 ;
對小規模陣列使用
插入排序理由:當我們進行遞迴二陣列的時候,如果當小陣列的長度,已經不是很大的時候,依然使用遞迴繼續二分的話,那麼,我們將頻繁的呼叫merge()方法;這也是遞迴固有的通病:當
子問題規模很小的時候,,遞迴會使得呼叫過於頻繁 ;因此,我們可以考慮,當小陣列的長度小於一定長度(書上建議為15)的時候,使用
插入排序,來對小陣列進行排序,可以提高插入排序的效能 ;因為
插入排序對 小規模亂序陣列(滿足插入排序適用場景之一:每個元素距離它最終的位置都不遠;) 排序很快;每次歸併之前,測試兩個小陣列,是否有序
理由:如果兩個小陣列滿足[mid] < [mid+1],也就是說,左邊的小陣列的最後一個元素,小於右邊小陣列的第一個元素;那麼這兩個小陣列,是可以直接歸併進大數組裡面的,這樣就省卻了每次都比較的開銷 ;每次歸併的時候,不將陣列複製到輔助數組裡面
理由: 我們可以不用把陣列複製到輔助數組裡面,再排序回原陣列中 ;其實,可以讓輔助陣列、原陣列的角色,來回交替變化,達到完成排序,而不復制的效果 ;
上述改動,均可見程式碼:
歸併排序的意義
我們前面學過的排序演算法,複雜度都是指數級別的,今天學的歸併排序,將複雜度降低到了,對數級別;這是一個很有意義的演算法,讓我們在對非常大多的資料量進行排序,變為可能;
但是,歸併排序並不是完美的,它有一個缺點,就是需要 N 個額外空間的輔助陣列,來輔助排序,並不是原地排序 ;
下次講的 快速排序,則可以克服掉 歸併排序 的 缺點 ;