
caffe多標籤訓練
阿新 • • 發佈:2019-01-09
最近剛接觸caffe弄了一個caffe多標籤遇到各種蛋疼的問題跟大家分享分享。
一 準備資料這裡用的驗證碼0-9+26個字母字母生成4位數的驗證碼
二 修改caffe原始碼涉及到修改的檔案有
caffe.proto ,
convert_imageset.cpp,
data_layer.cpp,
io.cpp,
data_layer.hpp,
io.hpp
具體修改就不介紹了去下面地址下載修改後的檔案然後替換掉原有caffe中的
檔案下載地址:https://pan.baidu.com/s/1eSP1RUi
這裡我們理解一下,caffe原本不支援多標籤分類任務,這裡的主要修改是為了是的caffe支援多標籤分類,我們知道caffe的label原版指定的是整數型且只有1個,看caffe.proto裡面寫的:Datum就是我們的資料層,那麼資料層的label是int32,這就限制了資料label的輸入必須是一個整數,那麼修改他的起點就是從proto裡面開始,加一個labels,陣列型別
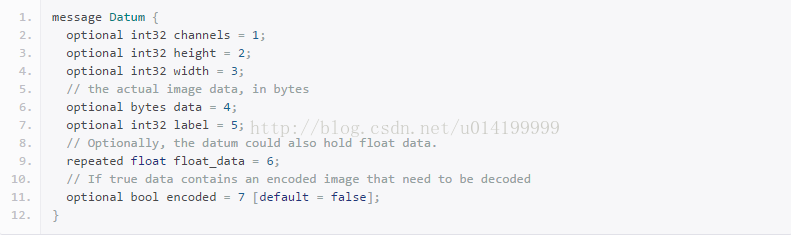
修改完了然後接著修改caffe使用Datum部分程式碼,實現對labels的支援
最後修改convert_imageset.cpp,讓他實現對例如如下:
imgs/abc.jpg 1 2 3 4 5
這種型別的多標籤做支援
最終完成這次修改,再編譯一遍就好了
三 製作資料標籤
圖片路徑 + 對應的標籤 samples/MYL1.bmp 22 34 21 1
四 寫個多分類網路
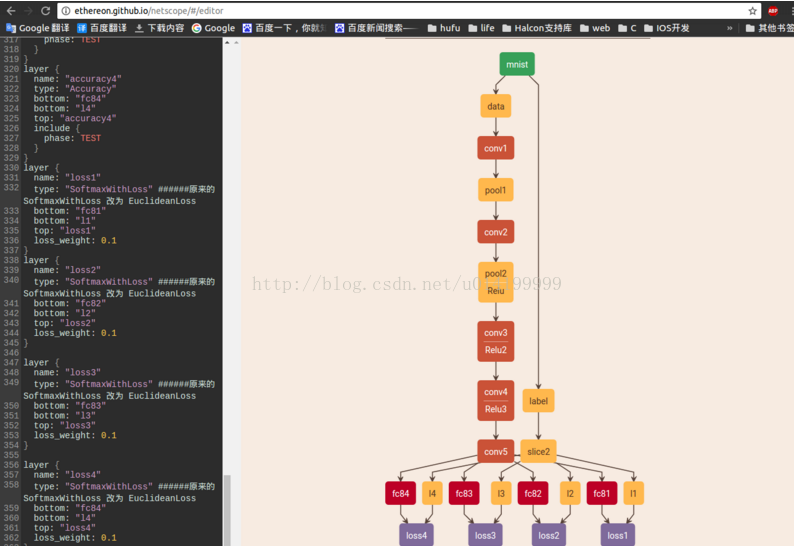
結構如下:
-
name:"LeNet" -
layer{ -
name:"mnist" -
type:"Data" -
top:"data" -
top:"label" -
include{ -
phase: TRAIN -
} -
transform_param{ -
scale:0.003921568627451 -
} -
data_param{ -
source:"train_lmdb" -
batch_size:64 -
backend: LMDB -
} -
} -
layer{ -
name:"mnist" -
type:"Data" -
top:"data" -
top:"label" -
include{ -
phase: TEST -
} -
transform_param{ -
scale:0.003921568627451 -
} -
data_param{ -
source:"val_lmdb" -
batch_size:64 -
backend: LMDB -
} -
} -
layer{ -
name:"conv1" -
type:"Convolution" -
bottom:"data" -
top:"conv1" -
param{ -
lr_mult:1 -
} -
param{ -
lr_mult:2 -
} -
convolution_param{ -
num_output:128 -
kernel_size:7 -
stride:1 -
weight_filler{ -
type:"xavier" -
} -
bias_filler{ -
type:"constant" -
} -
} -
} -
layer{ -
name:"pool1" -
type:"Pooling" -
bottom:"conv1" -
top:"pool1" -
pooling_param{ -
pool: MAX -
kernel_size:2 -
stride:2 -
} -
} -
layer{ -
name:"conv2" -
type:"Convolution" -
bottom:"pool1" -
top:"conv2" -
param{ -
lr_mult:1 -
} -
param{ -
lr_mult:2 -
} -
convolution_param{ -
num_output:128 -
kernel_size:5 -
stride:1 -
weight_filler{ -
type:"xavier" -
} -
bias_filler{ -
type:"constant" -
} -
} -
} -
layer{ -
name:"pool2" -
type:"Pooling" -
bottom:"conv2" -
top:"pool2" -
pooling_param{ -
pool: MAX -
kernel_size:2 -
stride:1 -
} -
} -
layer{ -
name:"Relu" -
type:"ReLU" -
bottom:"pool2" -
top:"pool2" -
} -
layer{ -
name:"conv3" -
type:"Convolution" -
bottom:"pool2" -
top:"conv3" -
param{ -
lr_mult:1 -
} -
param{ -
lr_mult:2 -
} -
convolution_param{ -
num_output:128 -
kernel_size:3 -
stride:1 -
weight_filler{ -
type:"xavier" -
} -
bias_filler{ -
type:"constant" -
} -
} -
} -
layer{ -
name:"Relu2" -
type:"ReLU" -
bottom:"conv3" -
top:"conv3" -
}