
KNN機器學習演算法—python的surprise庫電影推薦系統爬坑筆記
阿新 • • 發佈:2019-01-10
本文僅為記錄嘗試的時候遇到的坑。
資料格式:user item rating timestamp
安裝庫:
在安裝surprise庫的時候如果用python3.X的時候會提示需要visio c++ 2014,但是筆者環境明明有visio c++2014和2015,具體好像還需要一些其他配置,並沒有去深究,後經搜尋用python2.7可以直接安裝使用:
在安裝之前首先要確認已經安裝了numpy庫。
pip install scikit-surprise原始碼如下:
# -*- coding:utf-8 -*- from __future__ import (absolute_import, division, print_function, unicode_literals) import os import io from surprise import KNNBaseline from surprise import Dataset import logging logging.basicConfig(level=logging.INFO, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', datefmt='%a, %d %b %Y %H:%M:%S') # 訓練推薦模型 步驟:1 def getSimModle(): # 預設載入movielens資料集 data = Dataset.load_builtin('ml-100k') trainset = data.build_full_trainset() #使用pearson_baseline方式計算相似度 False以item為基準計算相似度 本例為電影之間的相似度 sim_options = {'name': 'pearson_baseline', 'user_based': False} ##使用KNNBaseline演算法 algo = KNNBaseline(sim_options=sim_options) #訓練模型 algo.train(trainset) return algo # 獲取id到name的互相對映 步驟:2 def read_item_names(): """ 獲取電影名到電影id 和 電影id到電影名的對映 """ file_name = (os.path.expanduser('~') + '/.surprise_data/ml-100k/ml-100k/u.item') rid_to_name = {} name_to_rid = {} with io.open(file_name, 'r', encoding='ISO-8859-1') as f: for line in f: line = line.split('|') rid_to_name[line[0]] = line[1] name_to_rid[line[1]] = line[0] return rid_to_name, name_to_rid # 基於之前訓練的模型 進行相關電影的推薦 步驟:3 def showSimilarMovies(algo, rid_to_name, name_to_rid): # 獲得電影Toy Story (1995)的raw_id toy_story_raw_id = name_to_rid['Toy Story (1995)'] logging.debug('raw_id=' + toy_story_raw_id) #把電影的raw_id轉換為模型的內部id toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id) logging.debug('inner_id=' + str(toy_story_inner_id)) #通過模型獲取推薦電影 這裡設定的是10部 toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, 10) logging.debug('neighbors_ids=' + str(toy_story_neighbors)) #模型內部id轉換為實際電影id neighbors_raw_ids = [algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors] #通過電影id列表 或得電影推薦列表 neighbors_movies = [rid_to_name[raw_id] for raw_id in neighbors_raw_ids] print('The 10 nearest neighbors of Toy Story are:') for movie in neighbors_movies: print(movie) if __name__ == '__main__': # 獲取id到name的互相對映 rid_to_name, name_to_rid = read_item_names() # 訓練推薦模型 algo = getSimModle() ##顯示相關電影 showSimilarMovies(algo, rid_to_name, name_to_rid)
資料集路徑問題:
1、第一次執行的時候總是會在read_item_names()函式中第一句提醒找不到ml-100k的資料集檔案,後經查閱os.path.expanduser(path) 的作用是:把path中包含“~”和“~user”轉換成使用者目錄。後自己去單獨下載了ml-100k資料集,並放在同級目錄下,然後將單引號中路徑換為‘/ml-100k/u.item’,還是找不到。再把os.path.expanduser('~')去掉,不通過此方式,後發現不抱錯,應該是找到了對應檔案。
2、接下來在getSimModel()函式中,提醒需要下載ml-100k資料集,這裡好像是直接使用surprise庫中Dataset的資料集,按照提示下載即可,如果太慢的話,用藍燈開VPN進行下載。
執行:
之後雖然會有報警告,但是已經可以正常運行了:
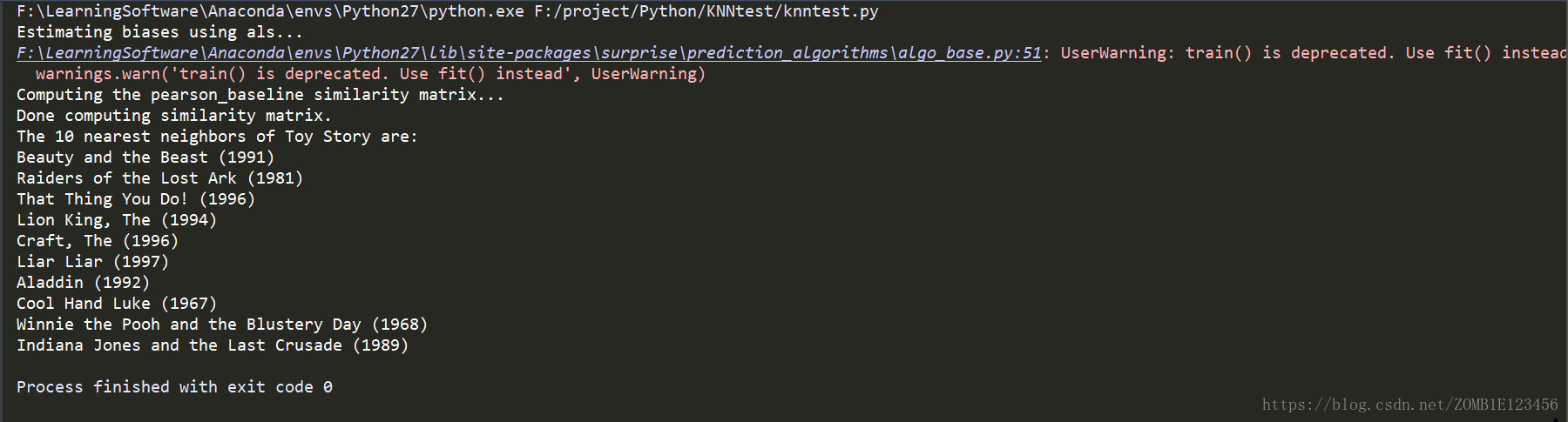
此處輸出就是Toy Story (1995)最相近的10部電影。
嘗試將引數換為Beauty and the Beast(1991),輸出結果如下:
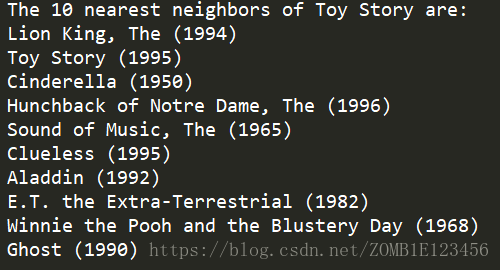
同樣Toy Story(1995)也在其中。
資料:/ml-100k/u.item內容如下
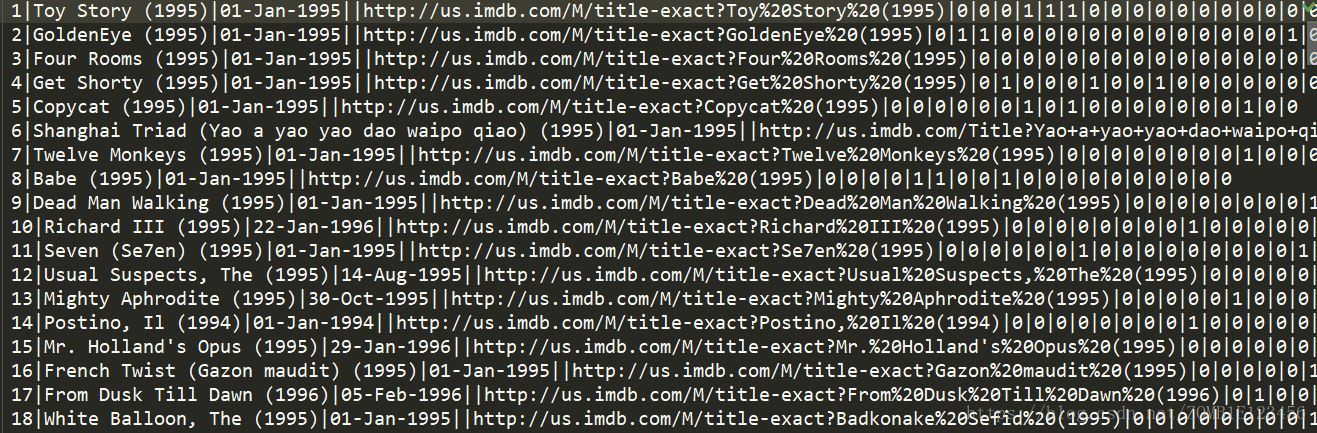
尾部的引數就是根據電影以及影評人的評分所構造的矩陣。