
Deep Learning的學習實踐 2 -- 邏輯迴歸和人工神經網路
學習DeepLearning,必須要先學習邏輯迴歸模型(LR)和傳統的人工神經網路模型(ANN),這個是基礎。
簡單說一下邏輯迴歸模型(LogisticRegression,這裡翻譯成邏輯迴歸可能不太準確,但是沿用目前大家常用的名稱),這個模型是非常實用的,在工業界的機器學習應用中很多場景都會使用,這個模型簡單有效,而且,可以處理非常高維的輸入特徵。其核心是邏輯迴歸函式,一般化的形式如下(這個函式也叫S形函式或Sigmoid函式):
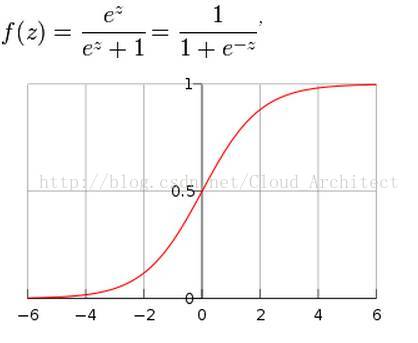
這裡面的核心是自然對數的底數e(2.718281828459),他的作用是把正無窮到負無窮的所有數通過上述Sigmoid函式的輸出壓縮的0到1之間,(這個底數e是個神奇的數字,它能反應很多自然界的基本規律,它是大數學家尤拉發現的,所以定義為
該模型的詳細求解過程和開原始碼,網上有很多材料。我對求解方法的簡單總結:1,梯度下降法:迭代計算全量資料的梯度(即曲線的導數,斜率)。2:隨機梯度下降法:每次迭代只取一個樣本計算梯度,避免過大的計算量,每次梯度不一定是最大梯度,經過多倫迭代後可以逐步接近最優方向。
Softmax Regression的原理與邏輯迴歸(LR)類似,只是把分類的公式泛化了,可以用於多分類問題(如果是二分類,Softmax與LR是一致的)。不過,LR也可以用於多分類問題(對每個類別做二分類判斷是否),對於多分類的問題,softmax與LR的區別是,softmax要求每個分類互斥,而LR可以讓多分類共存(一個數據可以歸屬多個類別)。
簡單說一下人工神經網路(ANN),ANN的基本單位是神經元,即感知器,它的啟用函式,一般是S函式(與邏輯迴歸一致)或者Tanh函式(雙曲正切函式),它們的主要區別是,S函式的輸出在0~之間,平滑一些,Tanh函式的輸出在-1~1之間,陡峭一些,實際應用中的差異,要看具體場景。傳統的人工神經網路是3層,一般使用BP(反向傳播)演算法進行訓練,如果網路層數多了,用BP這種訓練方法,會遇到“導數消亡”(vanishing gradient)問題(就是求解梯度的導數趨近於0,梯度很小了,進入“飽和區”或“平坦區”),如果層數多,在反向傳播梯度的時候,會越來越小,就會使得靠近輸入端的隱藏層引數不能得到有效的訓練,結果容易陷入區域性最小點,而不是全域性最小點。Deep Learning的訓練方法對這個問題有很好的改善和突破,所以可以把網路增加到Deep的深度,一般是5~10層的網路,其關鍵原因也在Pretraining裡面,我理解其核心是一層層的逐層優化,逐層單獨訓練,每一層的輸入是上一層的輸出,這一點很重要,這樣做實際上是把多層網路的訓練分解為N個部分分別訓練,也就規避了多層傳導梯度導致“導數消亡”的問題,從而達到更好的訓練效果,然後的Fineturning,與以前的BP演算法基本一致,使用標註資料做整個網路權值的微調。這個問題的原理在上一篇文章介紹的材料裡面有詳細介紹。
對基本的人工神經網路的介紹,有很多書和學習資料,如《BP神經網路詳解與例項》,是我覺得最詳細和清楚的材料,建議先閱讀這個入門材料。
另一篇文章,講解人工神經網路的入門級原理,講的很好,通過11行的Python程式碼進行詳細講解,如下:
什麼是Theano?這是以大牛Bengio主導的一個開源專案,基於Python,完整實現DeepLearning的3種核心模型,你看過“這篇文章,你就明白,這個開源專案絕對權威。而且這個開源專案,有很詳細的文件說明,有很好的程式碼註釋,這個專案的本意就是讓你去學習Deep Learning技術的,所以,講解的非常詳細,具體內容,請參考文章《Deep Learning Tutoria》。而且這個開源專案,支援基於GPU訓練Deep Learning模型,這也是非常重要的功能。不過,整個專案是基於函數語言程式設計的,其程式設計思路,與面向物件的程式設計方法有很大差異。目前,在機器學習領域,函數語言程式設計比較火,比如Spark的Scala就是函數語言程式設計。總的來說,函數語言程式設計不能修改函式內部的變數,一切以宣告好的函式基礎,只能控制函式的輸入和輸出,函數語言程式設計主要的優勢是併發效能很好,理論上不會死鎖。而且,編寫遞迴和迭代類的演算法,非常簡潔,所以機器學習的演算法用函數語言程式設計比普通面向物件的程式設計,程式碼量少一個數量級。但是,他是怎麼work的,對我這樣的傳統開發人員有些難以理解,入門需要花些時間,不過,值得學習一下。
Theano的首頁:http://deeplearning.net/software/theano/
Theano是個程式碼框架,裡面還有很多自定義型別,這裡面的一些基礎程式設計方法要先熟悉和練習一下,不然,後面的模型程式碼沒法修改和測試。
依據《DeepLearning Tutorial》的指導,下載DeepLearningTutorials-master.zip,裡面有全部樣例程式碼,可以下載MNIST資料集(手寫數字0~9的圖片識別資料集)進行測試。
安裝:
本地安裝: python setup.py install
一些程式設計要點:
MNIST資料集的下載地址:
origin ='http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz'
本地資料檔案的路徑要設定一下,建議設定絕對路徑:
__file__ ="D:\\workspace\\DeepLearning\\Data\\" # set local dataset path
下面這個引用,會預設使用tensor.max()函式,資料會被造型成tensor型別,在計算樣本資料max最大值時會比較麻煩,建議註釋掉:
from theano.tensor import*
初始權值(引數)為隨機數:
rng =numpy.random.RandomState(1234)
rng = np.random
w = theano.shared(rng.randn(feats),name="w")
如果要指定初始權值,設為0或1,如下:
init_w = [0]*feats
w =theano.shared(value=np.asarray(init_w, dtype=theano.config.floatX), name='w',borrow=True) # 這裡需要把Python的矩陣(array)轉成Theano的型別
如果要列印每個資料的具體概率(0~1之間),需要增加輸出變數:
predict_Test, probability_Test = predict_probability(D_test[0])
print "probability ofprediction D on test data:", probability_Test #每個資料預測值的概率
評價預測結果,可以用AUC(這種方式同時評價正例預測準確率和負例預測準確率,是一個全面的評價指標),(這裡使用scikit的庫來計算,新增引用from sklearn import metrics):
fpr, tpr, thresholds =metrics.roc_curve(D_test[1], probability_Test) #計算AUC
AUC = metrics.auc(fpr, tpr)
神經網路MLP的輸出,可以這樣修改(注意outputs部分):
train_model =theano.function(inputs=[index],
outputs=[cost, classifier.hiddenLayer.W,classifier.hiddenLayer.b,classifier.logRegressionLayer.W,classifier.logRegressionLayer.b],
updates=updates,
givens={
x: train_set_x[index * batch_size:(index + 1) * batch_size],
y: train_set_y[index * batch_size:(index + 1) * batch_size]})
神經網路的輸出,使用的是SoftMax多分類模型,也可以用於2分類,與邏輯迴歸一致,n_out設定為2即可:
classifier = MLP(rng=rng, input=x,n_in=147, #n_in是特徵維數,第一層神經元數
n_hidden=10, n_out=2) #n_hidden隱層神經元預設是500。
先基於DeepLearningTutorials-master中的程式碼和MNIST資料測試一下logistic_sgd.py,mlp.py。然後使用自己的資料,修改一下程式碼去詳細測試分析一下,對Theano的程式碼框架就可以熟悉了,並且,這些程式碼以後可以複用。