
《統計學習方法》-邏輯迴歸筆記和python原始碼
邏輯迴歸(Logistic regression)
邏輯迴歸是統計學習中的經典分類方法。其多用在二分類{0,1}問題上。
定義1:
設X是連續隨機變數,X服從邏輯迴歸分佈是指X具有下列分佈函式與密度函式:
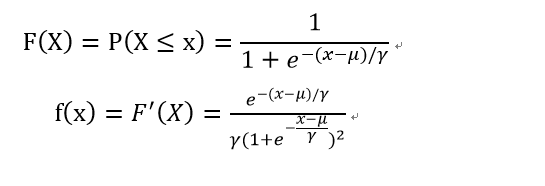

分佈函式屬於邏輯斯諦函式,其圖形是一條S形曲線。
定義2:
二項邏輯斯諦迴歸模型是如下條件概率分佈:

從上式可以看出,邏輯迴歸對線性迴歸經行了歸一化操作,將輸出範圍規定在{0,1}。
現在來看,邏輯迴歸的的特點,機率,指一件事件發生的概率與不發生的概率的比值。對上式分別求對數,我們可得如下式子。
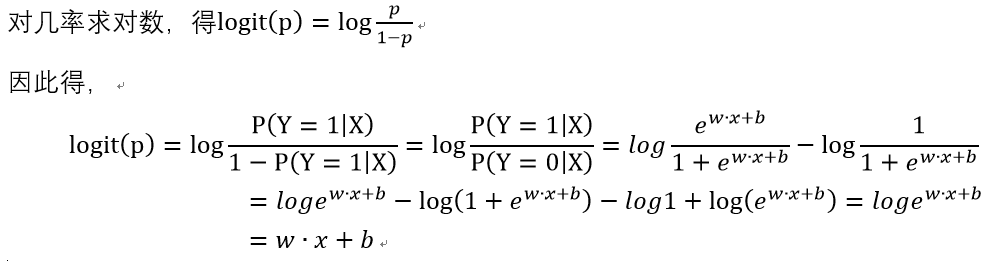
這就是說,在邏輯迴歸模型中,輸出Y=1的對數機率是輸入x的線性函式。
對輸入x經行分類的線性函式w*x,其值域為實數域。通過邏輯迴歸模型可以將線性函式轉化為概率,
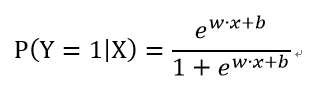
這就意味著,線性函式值越接近正無窮,概率越接近1;線性函式值越接近負無窮,概率值越接近0。這樣的模型稱為邏輯迴歸模型。
損失函式:
如同,在感知機一節中一樣,我們需要構造損失函式,更新權值引數。我們利用極大似然估計法估計模型引數,即w。極大似然估計法是已經知道結果,然後尋求使該結果成立的最大可能條件(條件即模型引數)。
似然函式:

對數似然函式:
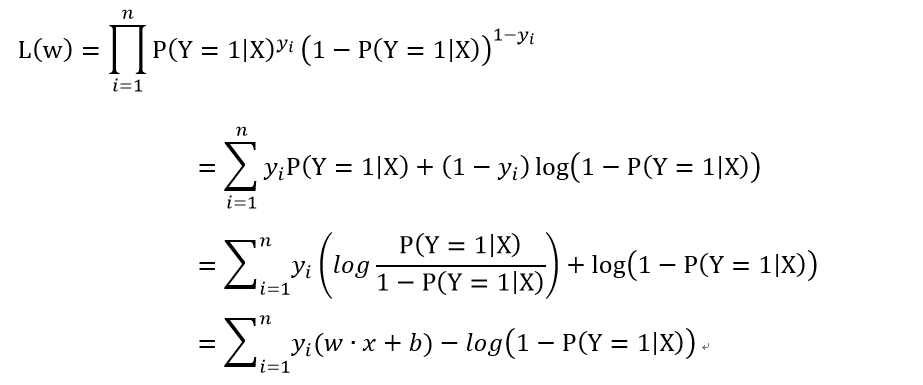
這樣子,我們有了損失函式,這裡我們只要將該函式極大化即可,求其最大值時的w即可。
優化求解:
梯度下降法
總是朝著負方向改變,直到找到極小值。初中數學中,對一個函式求導可以得到函
數在某一點的斜率k(表示函式的增長速率,朝著正方向改變),如果我
-k,那麼就得到了朝著負方向增長的速率。在這裡,由於我們要極大化對數似然函式,所
以在這裡不用加負號。
更新公式:
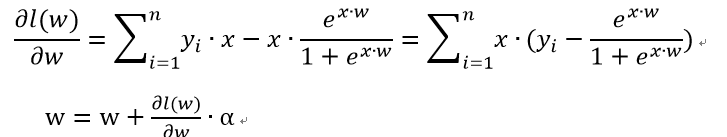
其中,alpha是學習率。
python原始碼:
實驗結果圖:#coding=utf-8 #author=altman import numpy as np import matplotlib.pyplot as plt def loadData(): train_x = [] train_y = [] fileIn = open('data.txt') for line in fileIn.readlines(): lineArr = line.strip().split() train_x.append([1.0, float(lineArr[0]), float(lineArr[1])]) train_y.append(float(lineArr[2])) train_x = np.array(train_x) train_y = np.array(train_y).T return train_x,train_y def sigmod(x): return 1.0/(1.0+np.exp(-x)) def train(matrix,labels): size = matrix.shape[1] w = np.ones(size) while True: x = np.dot(matrix,w) y = sigmod(x) diff = labels - y tmpW = w + 0.01*np.dot(matrix.T,diff) diff2 = (tmpW-w)**2 sum_diff2 = sum(diff2) sq = sum_diff2**0.5 if sq < 0.001: break else: w = tmpW return w def test(matrix,labels,w): x = np.dot(matrix,w) y = sigmod(x) error = 0.0 for i,result in enumerate(y): if result > 0.5: predict = 1.0 if predict != labels[i]: error +=1 else: predict = 0.0 if predict != labels[i]: error +=1 print("錯誤率:%3.2f" %(error/100.0)) def show(data,labels,w): x1=[] y1=[] x2=[] y2=[] for i in range(len(labels)): if labels[i] == 0: x1.append(data[i,1]) y1.append(data[i,2]) else: x2.append(data[i,1]) y2.append(data[i,2]) plt.scatter(x1,y1,edgecolors='r') plt.scatter(x2,y2,edgecolors='k') max_x = (np.max(data[:,1])) min_x = (np.min(data[:,1])) y_min_x = float(-w[0] - w[1] * min_x) / w[2] y_max_x = float(-w[0] - w[1] * max_x) / w[2] plt.plot([min_x, max_x], [y_min_x, y_max_x], '-g') plt.show() def main(): matrix,labels = loadData() weights = train(matrix,labels) test(matrix,labels,weights) show(matrix,labels,weights) if __name__ == '__main__': main()
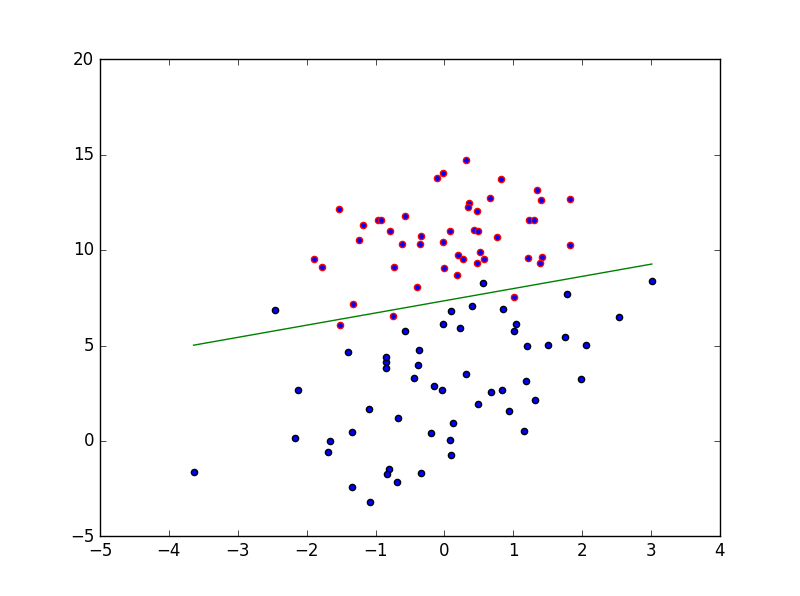
實驗資料集:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0相關推薦
《統計學習方法》-邏輯迴歸筆記和python原始碼
邏輯迴歸(Logistic regression) 邏輯迴歸是統計學習中的經典分類方法。其多用在二分類{0,1}問題上。 定義1: 設X是連續隨機變數,X服從邏輯迴歸分佈是指X具有下列分佈函式與密度函式: 分佈函式屬於邏輯斯諦函式,其圖形是一條S形曲線。 定義2: 二
【統計學習方法-李航-筆記總結】六、邏輯斯諦迴歸和最大熵模型
本文是李航老師《統計學習方法》第六章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: http://www.cnblogs.com/YongSun/p/4767100.html https://blog.csdn.net/tina_ttl/article/details/53519391
《統計學習方法》-樸素貝葉斯法筆記和python原始碼
樸素貝葉斯法 樸素貝葉斯法是基於貝葉斯定理與特徵條件獨立假設的分類方法。對於給定的訓練資料集,首先基於特徵條件獨立假設學習輸入/輸出的聯合概率分佈;然後基於此模型,對給定的輸入x,利用貝葉斯定理求出後驗概率最大的輸出y。 換句話說,在已知條件概率和先驗概率的情況下(即,在事
統計學習方法邏輯斯蒂迴歸
邏輯斯諦迴歸(logistic regression) 是統計學習中的經典分類方法。 最大熵是概率模型學習的一個準則, 將其推廣到分類問題得到最大熵模型(maximum entropy model) 。邏輯斯諦迴歸模型與最大熵模型都屬於對數線性模型。本文只介紹邏輯斯諦迴歸。 設X是連續隨機變數, X
【統計學習方法-李航-筆記總結】十一、條件隨機場
本文是李航老師《統計學習方法》第十一章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://www.cnblogs.com/YongSun/p/4767734.html 主要內容: 1. 概率無向圖模型 2. 條件隨機場的定義與形式 3. 條件隨機
【統計學習方法-李航-筆記總結】十、隱馬爾可夫模型
本文是李航老師《統計學習方法》第十章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://www.cnblogs.com/YongSun/p/4767667.html https://www.cnblogs.com/naonaoling/p/5701634.html htt
【統計學習方法-李航-筆記總結】九、EM(Expectation Maximization期望極大演算法)演算法及其推廣
本文是李航老師《統計學習方法》第九章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://www.cnblogs.com/YongSun/p/4767517.html https://blog.csdn.net/u010626937/article/details/751160
【統計學習方法-李航-筆記總結】八、提升方法
本文是李航老師《統計學習方法》第八章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://www.cnblogs.com/YongSun/p/4767513.html 主要內容包括: 1. 提升方法AdaBoost演算法 2. AdaBoost演算法的訓練誤差分析
【統計學習方法-李航-筆記總結】七、支援向量機
本文是李航老師《統計學習方法》第七章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://www.cnblogs.com/YongSun/p/4767130.html https://blog.csdn.net/wjlucc/article/details/69376003
【統計學習方法-李航-筆記總結】五、決策樹
本文是李航老師《統計學習方法》第五章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://blog.csdn.net/u014248127/article/details/78971875 https://www.cnblogs.com/YongSun/p/4767085.ht
【統計學習方法-李航-筆記總結】四、樸素貝葉斯法
本文是李航老師《統計學習方法》第四章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://blog.csdn.net/zcg1942/article/details/81205770 https://blog.csdn.net/wds2006sdo/article/detail
【統計學習方法-李航-筆記總結】三、k近鄰法
本文是李航老師《統計學習方法》第三章的筆記,歡迎大佬巨佬們交流。 主要參考部落格:https://blog.csdn.net/u013358387/article/details/53327110 主要包括以下幾部分: 1. k近鄰演算法 2. k近鄰模型 3. kd樹 1.
統計學習方法|Logistic迴歸
01 邏輯斯諦分佈 logistic迴歸是一種經典的分類演算法,模型形式如下(二分類),其中x服從邏輯斯諦分佈: 什麼叫服從邏輯斯諦分佈呢? 直觀點,分佈函式和密度函式長這樣: 邏輯斯諦迴歸模型有什麼特點呢? 我們來看邏輯斯諦分佈函式的形狀,橫軸範圍在正負無窮
《統計學習方法》讀書筆記
10.2.3 後向演算法 βt(i)=∑j=1Naijbj(ot+1)βt+1(j)\beta_t(i)=\displaystyle \sum_{j=1}^N a_{ij} b_j(o_{t+1})
《統計學習方法》 讀書筆記 第五章
第五章 決策樹 概述 1.可以認為是if-then的集合,也可以認為是定義在特徵空間與類空間上的條件概率分佈。 2.主要優點是模型具有可讀性,分類速度快。 3.包括三個步驟:特徵選擇、決策樹的生成和決策樹的修剪。 5.1 決策樹模
分享《機器學習與資料科學(基於R的統計學習方法)》高清中文PDF+原始碼
下載:https://pan.baidu.com/s/1Lrgtp7bnVeLoUO46qPHFJg 更多資料:http://blog.51cto.com/3215120 高清中文PDF,299頁,帶書籤目錄,文字可以複製。配套原始碼。 本書指導讀者利用R語言完成涉及機器學習的資料科學專案。作者: Da
《統計學習方法(李航)》邏輯斯蒂迴歸與最大熵模型學習筆記
作者:jliang https://blog.csdn.net/jliang3 1.重點歸納 1)線性迴歸 (1)是確定兩種或以上變數間相互依賴的定量關係的一種統計分析方法。 (2)模型:y=wx+b (3)誤差函式: (4)常見求解方法 最小
李航·統計學習方法筆記·第6章 logistic regression與最大熵模型(1)·邏輯斯蒂迴歸模型
第6章 logistic regression與最大熵模型(1)·邏輯斯蒂迴歸模型 標籤(空格分隔): 機器學習教程·李航統計學習方法 邏輯斯蒂:logistic 李航書中稱之為:邏輯斯蒂迴歸模型 周志華書中稱之為:對數機率迴歸模
邏輯斯諦迴歸與最大熵模型-《統計學習方法》學習筆記
0. 概述: Logistic迴歸是統計學中的經典分類方法,最大熵是概率模型學習的一個準則,將其推廣到分類問題得到最大熵模型,logistic迴歸模型與最大熵模型都是對數線性模型。 本文第一部分主
最小二乘迴歸樹Python實現——統計學習方法第五章課後題
李航博士《統計學習方法》第五章第二題,試用平方誤差準則生成一個二叉迴歸樹。 輸入資料為: x 0 1 2 3