
Spark-- docker + spark +hadoop進行搭建本機的偽叢集
簡介
之前擺弄了一個docker + hadoop3.1 的映象,通不了,所以這裡直接先再github上找了一個Spark搭建的叢集。
docker-spark : https://github.com/houshuai0816/docker-spark 這個專案中當前使用的是Spark 2.3.0 和 hadoop2.7 和jdk8
構建
- 進行檢出倉庫內容
git clone https://github.com/houshuai0816/docker-spark.git- 進入你的容器
cd G:\project\Github_Porject\docker-spark- 通過
yml進行啟動此專案
docker-compose up -d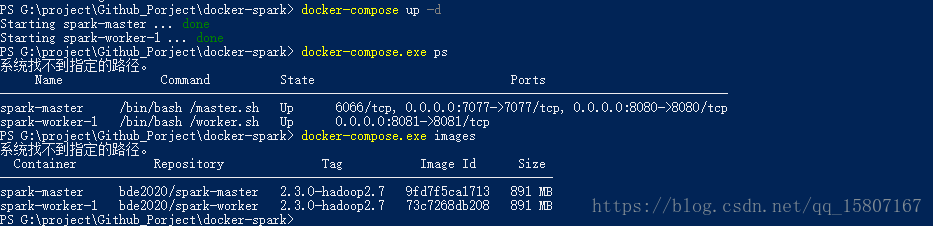
相關推薦
Spark-- docker + spark +hadoop進行搭建本機的偽叢集
簡介 之前擺弄了一個docker + hadoop3.1 的映象,通不了,所以這裡直接先再github上找了一個Spark搭建的叢集。 docker-spark : https://github.c
斷網的情況 搭建本機和虛擬機器內部區域網
因為家裡沒網,但是還想實現xshell連線虛擬機器。於是就想到了讓本機和虛擬機器處於同一個區域網內。廢話不多說,具體實現步驟如下:1、設定本機電腦開啟網路屬性-》網路連線-》VMware Network Adapter VMnet8 右鍵屬性,找到Internet 協議版本4(TCP/IPv4)比如這這裡設定
斷網的情況 搭建本機和虛擬機內部局域網
blog ifcfg sysconfig 內容 打開 方便 具體實現 如果 restart 因為家裏沒網,但是還想實現xshell連接虛擬機。於是就想到了讓本機和虛擬機處於同一個局域網內。廢話不多說,具體實現步驟如下:1、設置本機電腦打開網絡屬性-》網絡連接-》VMware
Hadoop之MapReduce 本機windows模式執行
hadoop在windows本機執行 (1)在 windows環境下編譯好的hadoop放到沒有中文和空格的路徑下 (2)編譯好的hadoop內的hadoop.all檔案要放到windows機器的windows-system32目錄下 , 否則報錯 (3)配置windows環
elasticsearch叢集搭建手冊(偽叢集搭建)
安裝部署 建立程式目錄 安裝目錄 mkdir /usr/local/elasticsearch mkdir /usr/local/elasticsearch/6.4.3 mkdir /usr/local/elasticsearch/6.4.3/01 #第一個節
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。
centos 失敗 sco pan html top n 而且 div href Centos7出現異常:Failed to start LSB: Bring up/down networking. 按照《Kafka:ZK+Kafka+Spark Streaming集群環
hadoop生態搭建(3節點)-10.spark配置
sla over doc you 環境變量 添加 home usr count # https://www.scala-lang.org/download/2.12.4.html# ==============================================
Spark學習筆記(三) Ubuntu搭建Hadoop分散式叢集
Ubuntu搭建Hadoop分散式叢集 執行環境 配置目標 搭建Hadoop分散式叢集步驟 1 搭建master 1.1 安裝JDK 1.2 安裝SSH 1.3 安裝Hadoop 2
使用docker安裝Hadoop和Spark
使用docker配置安裝hadoop和spark 分別安裝hadoop和spark映象 安裝hadoop映象 選擇的docker映象地址,這個映象提供的hadoop版本比較新,且安裝的是jdk8,可以
hadoop zookeeper hbase spark phoenix (HA)搭建過程
環境介紹: 系統:centos7 軟體包: apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz 下載連結:http://mirror.bit.edu.cn/apache/phoenix/apache-phoenix-4.14.1-HBase-1.4/bin/
搭建大資料處理叢集(Hadoop,Spark,Hbase)
搭建Hadoop叢集 配置每臺機器的 /etc/hosts保證每臺機器之間可以互訪。 120.94.158.190 master 120.94.158.191 secondMaster 1、建立hadoop使用者 先建立had
Spark+Hadoop環境搭建
一、工具下載: 1、spark下載 目前最新的是2.1.1,spark 2.0開始api和之前的還是有比較多的變化,因此如果選擇2.0以上版本,最好看一下api變化,下載地址:http://spark.apache.org/downloads.html 2、hadoop下載
Spark之路:(一)Scala + Spark + Hadoop環境搭建
一、Spark 介紹 Spark是基於記憶體計算的大資料分散式計算框架。Spark基於記憶體計算,提高了在大資料環境下資料處理的實時性,同時保證了高容錯性和高可伸縮性,允許使用者將Spark部署在大量廉價硬體之上,形成叢集。 1.提供分散式計算功能,將分散式
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz的叢集搭建(單節點)(Ubuntu系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言的程式設計,如paython
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的叢集搭建(單節點)(CentOS系統)
前言 關於幾個疑問和幾處心得! a.用NAT,還是橋接,還是only-host模式? b.用static的ip,還是dhcp的? 答:static c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。 d.重用起來指令碼語言
mac下Hadoop、HDFS、Spark環境的安裝和搭建
環境搭建 相比之前搭建Hadoop環境的Windows系統的相對繁瑣步驟,Mac下顯得簡單不少。 雖然我們需要搭建的是Spark環境,但是因為Spark依賴了Hadoop的HDFS以及YARN計算框架,當然還有類似軟體包管理軟體。 安裝前必備 作業系統:Mac OS
Docker4Windows -- 從外部(非本機host)訪問 由docker container運行的程序
style 機器 轉發 配置 tin 外部 acl 16px 轉發規則 背景 當我們在windows 上面運行docker container的時候,我們需要借助於模擬器(例如,Virtual box/Hyper V),她的目的主要是在我們的windows系統上面模擬出一
下載基於大數據技術推薦系統實戰教程(Spark ML Spark Streaming Kafka Hadoop Mahout Flume Sqoop Redis)
大數據技術推薦系統 推薦系統實戰 地址:http://pan.baidu.com/s/1c2tOtwc 密碼:yn2r82課高清完整版,轉一播放碼。互聯網行業是大數據應用最前沿的陣地,目前主流的大數據技術,包括 hadoop,spark等,全部來自於一線互聯網公司。從應用角度講,大數據在互聯網領域主
用nodejs的express框架在本機搭建一臺服務器
redirect sta start moc 頁面 exe 瀏覽器 server proc [本文出自天外歸雲的博客園] 簡介 用express框架在本機搭建一個服務器,這樣大家可以通過指定的url來在你的服務器上運行相應的功能。 Express是一個基於nodejs
如何讓虛擬機與本機進行通信
.cn 虛擬 主機 ifconfig 復制 配置 通信 列操作 nbsp 如果ifconfig還不能看到IP,那麽就需要做下列操作,或者說如果虛擬機是復制來的,就需要做以下操作 進行主機配置 橋接:虛擬機利用的是真實網卡和互聯網局域網進行通信 僅主機:缺點就是不可以上