
神經網路優化器
本部落格介紹了神經網路訓練過程中的常見優化策略,並進行了分析和對比,包括梯度下降、小批量梯度下降、動量梯度下降、RMSProp、Adam 等。下面貼出的程式碼地址能幫助讀者更詳細地理解各優化器的實現過程,原理和功能。
程式碼地址: https://github.com/SkalskiP/ILearnDeepLearning.py
神經網路陷阱:
(1)區域性極小值:優化器極易陷入區域性極小值從而無法找到全域性最優解。
(2)鞍點:當成本函式值幾乎不再變化時,就會形成平原(plateau)。在這些點上,任何方向的梯度都幾乎為零,使得函式無法逃離該區域。
梯度下降
公式如下:
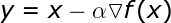
超引數 α 表示學習率,代表演算法每次迭代過程的前進步長。學習率的選擇一定程度上代表了學習速度與結果準確率之間的權衡。選擇步長過小不利於演算法求解,且增加迭代次數。反之,選擇步長過大則很難發現最小值。此外,該演算法很容易受鞍點問題的影響。因為後續迭代過程的步長與計算得到的梯度成比例,所以我們無法擺脫 plateau。且每次迭代過程都要用到整個資料集,不適用於大樣本網路。
解決方法:小批量梯度下降,即將完整資料集切分成許多小批量以完成後續訓練。
動量梯度下降
動量梯度下降利用指數加權平均,來避免成本函式的梯度趨近於零的問題。簡單說,允許演算法獲得動量,這樣即使區域性梯度為零,演算法基於先前的計算值仍可以繼續前進。所以,動量梯度下降幾乎始終優於純梯度下降。
然而,動量梯度下降的不足之處在於,每當臨近最小點,動量就會增加。如果動量增加過大,演算法將無法停在正確位置。
RMSProp
RMSProp(Root Mean Squared Propagation)是另一種改善梯度下降效能的策略,是最常用的優化器。該演算法也使用指數加權平均。而且,它具備自適應性──其允許單獨調整模型各引數的學習率。後續引數值基於為特定引數計算的之前梯度值。
其公式如下:

顧名思義,每次迭代我們都要計算特定引數的成本函式的導數平方。此外,使用指數加權平均對近期迭代獲取值求平均。最終,在更新網路引數之前,相應的梯度除以平方和的平方根。這表示梯度越大,引數學習率下降越快;梯度越小,引數學習率下降越慢。該演算法用這種方式減少振盪,避免支配訊號而產生的噪聲。為了避免遇到零數相除的情況(數值穩定性),我們給分母添加了極小值 ɛ。
該優化器的缺點是:由於每次迭代過程中公式的分母都會變大,學習率會逐漸變小,最終可能會使模型完全停止。
Adam
Adam應用廣泛且表現不俗,其利用了 RMSProp 的最大優點,且與動量優化思想相結合,形成快速高效的優化策略。然而,隨著優化方法有效性的提高,計算複雜度也會增加。