
簡單理解KMP演算法
KMP演算法是迄今為止最為高效的字串匹配演算法。當然,在KMP演算法出現之前,有關字串的匹配問題當然經過了一個漫長的探索過程。從一開始最簡單的樸素字串匹配演算法,到Rabin-Karp演算法,再到有限自動機演算法等等,可以說任何一個偉大演算法的誕生都不可能是一朝一夕之功,在它之前一定有大量的理論及實驗的基礎。所以,想要徹底理解KMP演算法最好是從頭開始,對整個字串的匹配問題有個完整的瞭解。
但是,我在這篇博文中講的卻是對KMP演算法最簡單的理解。只能幫助大家瞭解KMP最基本的思路和應用。若要詳細瞭解,推薦《演算法導論》中的“字串匹配”一節。我沒有見過比這一章講解得更詳細的資料了。
所謂字串匹配,解決的問題就是在一段文字(text)之中尋找我們要匹配的模式(pattern)。文字和模式都是由字串構成的,模式的長度<=文字的長度。例如,模式為”aba”,文字為”abcbaba”,所謂字串匹配就是在文字中查詢模式出現的位置(一般以文字成功匹配的欄位的第一個字元的位置表示),這裡應該返回4。
一種比較簡單的辦法是樸素字串匹配,就是一個字元一個字元去匹配。比如上面這個例子,一開始對文字和模式都是從頭開始匹配,效果如下圖:
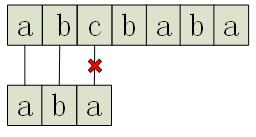
我們發現,第三個字元處文字為”c”,而模式為”a”,於是匹配失敗。那麼接下來,自然而然就能想到,把整個模式向右平移一位,再次進行匹配:
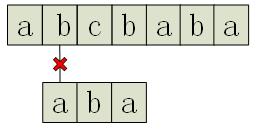
很遺憾,這次模式的第一個字元就沒能匹配成功。這樣,每次向後移動一位,依次匹配,若出現某一時刻模式的全部字元都能和它當時所對應的文字匹配,則匹配成功一次;繼續向後,直到模式的第一個字元對應的是文字的第(n - m + 1)個字元為止(其中,n為文字長度,m為字串長度),匹配結束。也就是說當模式的最後一個字元對應的是文字的最後一個字元時,就自然沒有必要再進行匹配了。
通過時間複雜度分析,可知樸素匹配演算法的時間複雜度為. 但是這個裡面有個問題,就是其實我們沒有必要在一次匹配失敗(成功)之後,向右移動一位繼續。而可以向右移動不止一位。
為什麼呢?還是看上面的例子,第一次匹配是,模式的第三個字元沒有和文字匹配,那同時也就說明了模式的前兩位和對應的文字是匹配的。我們可以確定模式未匹配的那一位所對應的文字的前一位(這裡就是文字的第二位)是b。而模式的第一位是a,那麼,顯然,a與b不同,往後移動一位讓a與b匹配就是多餘的,沒有必要的。
那麼應該往後移動幾位呢?可以想象,假如模式的第 i 位不能匹配,那麼,就需要移動模式,使得模式的前k位成為模式前 i - 1 位的字尾(k在此是個小於 i 的)。
先說明一下字串的字首,字尾:比如字串”abcde”中, “a”, “ab”, “abc”等等都是字首,而”cde”, “de”, “e” 等等都是字尾。也就是說,從字串頭開始截任意小於等於字串長度的字元,就是字首,而從後開始截任意長度就是字尾。
回到剛才的問題,為了能夠實現可能的匹配,需要模式向右偏移,使得模式以“最長的頭”匹配上剛才已經匹配的文字欄位的尾。也就是說尋找模式的前 i -1 項的字尾中能成為模式的最長字首的部分。而如果字尾中找不到字首,則將模式偏移 i 位即可。話有點抽象,看看這個例子:文字”ababababc”,模式”ababc”
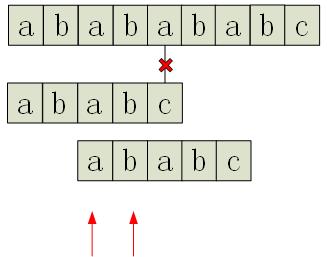
同樣的,第一次匹配在模式的第5個字元處失敗,但是此時並沒有從後面一個字元開始重新匹配,而是向右移動兩位,為什麼是兩位呢,我們可以觀察一下紅箭頭指的兩位,因為模式的第5位匹配失敗,所以,現在我們看看能否在在模式前4位的字尾中找到模式的字首,剛好,字串”ab”可以作為模式前4位的字尾,同時也是模式的字首(字尾中最長的字首)。不難發現,只有這樣,才能使得這一次匹配是“可能有意義”的。
換句話說,可以通過對模式本身的計算,得出一個數組,其中告訴我們,如果模式的第位不能和文字匹配時,模式的前位中字尾中的最大字首的長度。比如,模式 "ababaca" 相對應的陣列為:
因為模式一般比文字短很多,所以,我們計算這個陣列消耗的計算量是可以接受的,尤其是模式比文字短很多的情況下。這樣,模式就應該向右偏移位。並且直接從模式的開始與文字上次沒有與模式成功匹配的位做比較。
總結一下上面的思路:
- 模式的第位與文字的第位不匹配了,就查詢;
- 重新開始比較與
上面的思路寫成程式碼如下:
def kmp(pattern, text):
m, n = len(pattern), len(text)
# i為模式的下標
i = 0
# 遍歷文字
for j in range(n):
# 要求i > 0的原因是如果模式的第一位都不能匹配,那就直接向右移動一格掃描文字
while i > 0 and pattern[i] != text[j]:
i = pi[i - 1]
# 匹配成功,則繼續模式下一位與文字下一位的比對
if pattern[i] == text[j]:
i += 1
# 整個模式匹配成功,輸出資訊
if i == m:
print("the pattern occurs at %d" % (j - i + 1))
# 一次匹配完成,重新計算偏移量
i = pi[i - 1]程式碼中,我假設陣列 pi 已經被提前計算出來了。那現在的問題是怎麼計算陣列 pi ?
如果你已經理解了上面的程式碼,那麼計算 pi 就容易了,我們只需要稍微將上面的程式碼改一下,改成讓模式與模式自身匹配(當然是讓一個模式從第1位開始與另一個模式從第2位開始匹配),將每次匹配的最多字元的長度記錄下來就是所謂“字尾的最大字首”了。
因此,我的輔助函式 helper() 如下,負責計算偏移量陣列。
# 實際上是模式的字首與模式本身匹配
def helper(pattern):
m = len(pattern)
# pi的第1位是0,意思是如果pattern的第一個字元就不匹配的話,無偏移量
pi = [0]
k = 0
# 遍歷模式,從第2位(也就是下標1開始)
for j in range(1, m):
# 不匹配,向右偏移,偏移量的計算還是依靠已經計算了部分的陣列pi
# 這種思想有點類似於動態規劃,根據之前的計算結果計算新的結果
# 每次計算的k值其實是當pattern[i]與文字不能匹配時的偏移量
while k > 0 and pattern[k] != pattern[j]:
k = pi[k - 1]
# 匹配成功,k + 1得到最大字首
if pattern[k] == pattern[j]:
k += 1
pi.append(k)
return pi把這兩段程式碼合成:
我省去了所有註釋,讓程式碼更清楚,就是下面的樣子,一共25行
def kmp(pattern, text):
m, n = len(pattern), len(text)
i = 0
for j in range(n):
while i > 0 and pattern[i] != text[j]:
i = pi[i - 1]
if pattern[i] == text[j]:
i += 1
if i == m:
print("the pattern occurs at %d" % (j - i + 1))
i = pi[i - 1]
def helper(pattern):
m = len(pattern)
pi = [0]
k = 0
for j in range(1, m):
while k > 0 and pattern[k] != pattern[j]:
k = pi[k - 1]
if pattern[k] == pattern[j]:
k += 1
pi.append(k)
return pi相關推薦
簡單理解KMP演算法
KMP演算法是迄今為止最為高效的字串匹配演算法。當然,在KMP演算法出現之前,有關字串的匹配問題當然經過了一個漫長的探索過程。從一開始最簡單的樸素字串匹配演算法,到Rabin-Karp演算法,再到有限自動機演算法等等,可以說任何一個偉大演算法的誕生都不可能是一朝
循序漸進,深入理解KMP演算法
KMP演算法是三位大牛:D.E.Knuth、J.H.Morris和V.R.Pratt同時發現的。其中第一位就是《計算機程式設計藝術》的作者! KMP演算法要解決的問題就是在字串(也叫主串)中的模式(pattern)定位問題。說簡單點就是我們平時常說的關鍵字搜尋。模式串就是關鍵字(接下來
從DFA角度理解KMP演算法
KMP 演算法 KMP(Knuth-Morris-Pratt)演算法在字串查詢中是很高效的一種演算法,假設文字字串長度為n,模式字串長度為m,則時間複雜度為O(m+n),最壞情況下能提供線性時間執行時間保證。 《演算法導論》和其他地方在講解KMP演算法的時候
KMP之一:從頭到尾徹底理解KMP演算法(2014年8月1日版)
作者:July 時間:最初寫於2011年12月,2014年7月21日晚10點 全部刪除重寫成此文。 1. 引言 本KMP原文最初寫於2年多前的2011年12月,因當時初次接觸KMP,思路混亂導致寫也寫得非常混亂,如此,留言也是“罵聲”一片。所以一直想找機會重新寫下KMP,但苦於一直以來對KMP的理
簡單的KMP演算法
雖然題目聲稱KMP簡單,但只是對於理解了的人而言的,但是對於還沒有理解的人來說,KMP演算法確實是非常難的,但是不要緊,我相信通過我的介紹你會理解的,但是個人認為,不論什麼比較難理解的演算法,如果直接給你講,即使講的方法再簡單,但是你沒有去自己思考,那也是理解不
最簡單的KMP演算法求next陣列值的方法
本文依照嚴蔚敏串的資料結構(C語言版本)總結的方法: next陣列的求解方法是: 注意:1. j的下標識從0開始排的 2. 規定next[0]=-1,next[1]=0 j
透徹理解KMP演算法
好好打下字串演算法基礎。本篇通俗、透徹地解釋線性時間複雜度的字串匹配演算法:KMP演算法。 之前寫過KMP演算法,但時間久了回顧起來還是要花點兒時間,覺得需要進一步加深;現在就試圖徹底吃透它。若是感興趣豆友們能得到一點點的幫助就更好了~ 別忘了點個贊:-) KMP 演算法的
KMP演算法的簡單理解 【筆記】
//本文除實現程式碼外全部為原創內容 轉載請註明出處 程式碼來自這裡 kmp演算法是一種改進的字串匹配演算法,由D.E.Knuth與V.R.Pratt和J.H.Morris同時發現,故稱KMP演算法 字串匹配:從字串T中尋找字串P出現的位置(P遠小於T)。其中P稱為“模式”
kmp演算法(最簡單最直觀的理解,看完包會)
本文將以特殊的方式來讓人們更好地理解kmp演算法,不包括kmp演算法的推導,接下來,我們將從樸素演算法出發。 在這之前,我們先設主串為S,模式串為T,我們要解決的詢問是主串中是否包含模式串(即T是否為S的子串)。 版權宣告:本文為原創文章,轉載請標明出處。
KMP演算法淺顯理解
說明:轉載 KMP演算法看懂了覺得特別簡單,思路很簡單,看不懂之前,查各種資料,看的稀裡糊塗,即使網上最簡單的解釋,依然看的稀裡糊塗。 我花了半天時間,爭取用最短的篇幅大致搞明白這玩意到底是啥。 這裡不扯概念,只講演算法過程和程式碼理解: KMP演算法求解什麼型別問題 字串匹配。給
KMP演算法最淺顯理解
說明 KMP演算法看懂了覺得特別簡單,思路很簡單,看不懂之前,查各種資料,看的稀裡糊塗,即使網上最簡單的解釋,依然看的稀裡糊塗。 我花了半天時間,爭取用最短的篇幅大致搞明白這玩意到底是啥。 這裡不扯概念,只講演算法過程和程式碼理解: KMP演算法求解什麼型別問題
KMP 演算法(1):如何理解 KMP
http://www.61mon.com/index.php/archives/183/ 系列文章目錄 KMP 演算法(1):如何理解 KMPKMP 演算法(2):其細微之處 一:背景TOC 給定一個主字串(以 S 代替)和模式串(以 P 代替),要
樸素貝葉斯分類演算法簡單理解
樸素貝葉斯分類演算法簡單理解 貝葉斯分類是一類分類演算法的總稱,這類演算法均以貝葉斯定理為基礎,故統稱為貝葉斯分類。而樸素樸素貝葉斯分類是貝葉斯分類中最簡單,也是常見的一種分類方法。這篇文章我儘可能用直白的話語總結一下我們學習會上講到的樸素貝葉斯分類演算法,希望有利於他人理解。 1
演算法 時間和空間複雜度的簡單理解小述
一、概述 本節主要簡單分析下演算法的時間、空間複雜度,並不會涉及公式的推倒,主要以能用能理解為主,因為我自己也是一個門外漢,想深入的總結也是心有餘而力不足。 二、分析 當一個問題的演算法被確定以後,那麼接下來最重要的當然是評估一下該演算法使用的時間和佔用記憶體資源的相關問題了
蒙特卡洛演算法簡單理解與demo
本文轉自:https://blog.csdn.net/u011021773/article/details/78301557 蒙特卡洛演算法,實際上就是用頻率估計概率。 首先我們知道一個邊長為2的正方形面積是22=4,他的內接圓的面積是π1,那麼我們在這樣一個正方形內隨機生成10
PID演算法控制簡單理解
1 傳統的位式控制演算法 使用者期望值Sv(設定值)經控制演算法輸出一個輸出訊號OUT,輸出訊號載入到執行部件上(像MOS管等)對控制物件進行控制(步進電機、加熱器等),控制物件的當前值(Pv)如速度通過感測器反饋給控制演算法與Sv相比較。 特點:1 位式演算法輸出的控制訊
對動態規劃演算法的簡單理解
動態規劃演算法通常基於一個遞推公式及一個或多個初始狀態。當前子問題的解將由上一次子問題的解推出。使用動態規劃來解題只需要多項式時間複雜度,因此它比回溯法、暴力法等要快許多。 首先,我們要找到某個狀態的最優解,然後在它的幫助下,找到下一個狀態的最優解,“狀態"用來描述該問題的子問題的解。“
二分圖最大匹配 匈牙利演算法的簡單理解
(本文圖片及被*標註內容來自CSDN部落格:pi9nc) 基本概念—二分圖 二分圖:是圖論中的一種特殊模型。若能將無向圖G=(V,E)的頂點V劃分為兩個交集為空的頂點集,並且任意邊的兩個端點都分屬於兩個集合,則稱圖G為一個為二分圖。 匹配:一個匹配即一個包含若干條邊的集合,且其中任
對KMP演算法的理解
概述 這篇文章本來寫在了word文件裡,兩天倉促寫了這些東西,但不知不覺就搞了16頁的word,為了留存勞動成果,發一遍存到部落格上。文章幾乎一直在用失配後如何選擇新的合適的起點來說這個演算法,總之就是為了減少不必要的匹配,直接判掉某些匹配起始點,再就是匹配時主串是不會回退的。 說明 為
電影推薦系統設計思路(簡單易懂的演算法理解)
以下是我在澳洲留學期間設計的一個電影推薦系統的設計思路,因為我覺得比較有趣,所以放出來也算是一個懷念 本文理論主要參考 Networked Life: 20 Questions and Answers 以及 UNSW COMP9318課程 http://www.handb