
PyTorch動態神經網路(二)
利用PyTorch搭建神經網路
神經網路可以使用PyTorch的torch.nn包來構建。
autograd實現了反向傳播的功能,但是直接用來深度學習的程式碼在很多情況下還是稍顯複雜。
torch.nn是專門為神經網路設計的模組化介面,nn構建於autograd之上,可以用來定義和執行神經網路。nn.Moudle是nn中最重要的類,可把它看成是一個網路的封裝,包含網路各層定義以及forward方法,呼叫forward(input)方法,可返回前向傳播的結果。
一個典型的神經網路訓練過程如下:
- 定義具有一些可學習引數(或權重)的神經網路
- 迭代輸入資料集
- 通過網路處理輸入
- 計算損失(輸出的預測值於實際值之間的距離)
- 將梯度傳播回網路
- 更新網路的權重,通常使用一個簡單的更新規則:weight = weight - learning_rate * gradient
1、Variable變數
在神經網路裡,資料都是Variable變數的形式,是把tensor的資料放入神經網路的variable變數中,來慢慢更新神經網路中的引數。
import torch
from torch.autograd import Variable
tensor = torch.FloatTensor([[1,2],[3,4]])
variable = Variable(tensor,requires_grad=True) #用Variable將tensor放入variable變數中 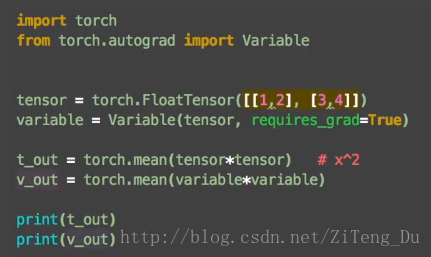
執行結果:
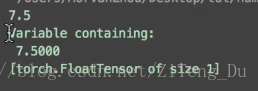
可以看到tensor的結果是7.5,variable的結果是Variable containing巴拉巴拉下面一堆,這說明。tensor只得到一個結果,而variable卻是屬於圖的一部分,什麼圖呢,就是神經網路的流程圖,這裡有必要提到PyTorch於TensorFlow的區別了,TensorFlow是先建立一個靜態的流程圖在放資料,而PyTorch是一邊放資料一邊搭圖,所以tensor不能夠作為神經網路中的變數,因為它不是圖的一部分同時也不能進行反向傳播。
下面來看下兩者在反向傳播中的差別:
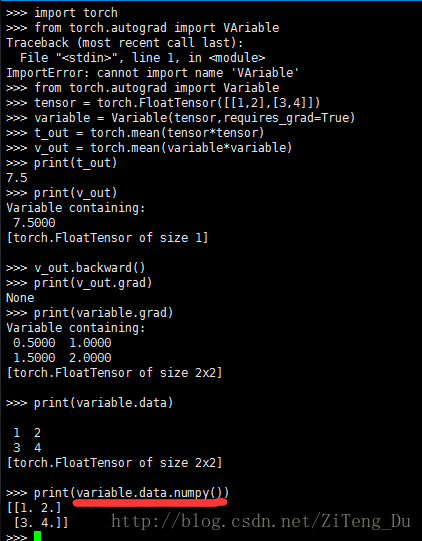
variable是神經網路中的變數,它有梯度grad的屬性,也有data的屬性,它的data的屬性就是tensor型別的資料,所以從variable轉化為Numpy的話,要用variable.data.numpy(),也就是先轉為tensor再轉為numpy。
而tensor只是資料並沒有任何屬性。
2、激勵函式(Activation Function)
首先來看神馬是激勵函式:
現實生活中很多問題都是非線性的,不規則的,所以這就需要激勵函式幫助我們處理這些非線性問題。
Linear function:y = wx
Unlinear function: y = AF(Wx) 其中AF就是激勵函式,其實激勵函式就是一個非線性函式,將這個非線性函式作用線上性結果上,強行將線性結果變非線性,從而使輸出結果也會帶有非線性的特徵。

甚至可以自己創造激勵函式處理問題,但是要保證你的激勵函式是可以微分的,因為誤差反向傳播的過程,只有可以微分的函式才可以將誤差反向傳遞回去。
當神經網路層數較少的情況下,你可以隨意選擇激勵函式都沒問題,但是當神經網路層數較多的情況下,就不能在隨意選擇了,因為會涉及到梯度消失,梯度爆炸的問題。
卷積神經網路中推薦用relu,迴圈神經網路中推薦用relu和tanh。
下面來看下激勵函式的用法:

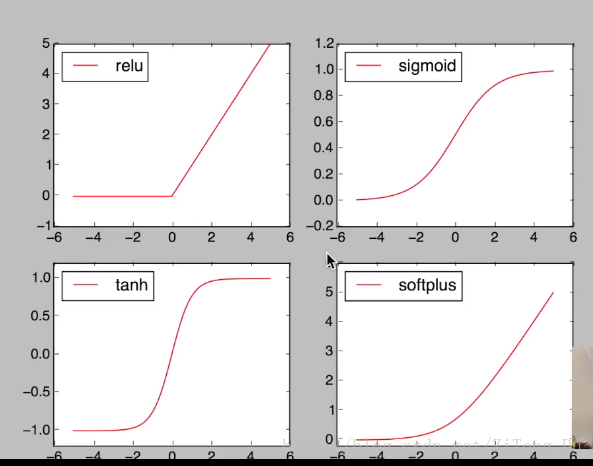
注意在神經網路中進行運算的資料都是variable變數,所以要接受激勵函式的作用就要先將numpy的資料利用torch.tensor(numpy)來轉化為variable型別的資料,但是使用matplotlib畫圖的時候還是需要numpy的資料,所以要利用x.data.numpy()來轉化回numpy。
3、初步搭建神經網路
(1)關係擬合迴歸:
import torch
from torch.autograd import Variable
import torch.nn.function as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1,1,100),dim=1) #因為在torch中它的資料是有維度的,unsqueeze就是把一維的資料轉化為二維
y = x.pow(2) + 0.2*torch.rand(x.size())
x,y = Variable(x), Varitable(y)
#plt.scatter(x.data.numpy(),y.data.numpy()) #這裡是畫圖
#plt.show()
#下面開始搭建神經網路:
class Net(torch.nn.Module):
#init中設定好每一層的輸入輸出口有幾個
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_features,n_hidden)
self.predict = torch.nn.Linear(n_hidden,n_output)
#forward才算是真正開始搭建神經網路,x是輸入資訊,
def forward(self,x):
#輸入資料先經過一個隱藏層,然後再用激勵函式啟用
x = F.relu(self.hidden(x))
#再讓x經過輸出層,這裡可以不再用激勵函式啟用,因為大多數我們所預測的結果的取值都是從正無窮到負無窮,所以並不需要使用激勵函式進行擷取(因為一般的激勵函式的值域都只是在一定區間內)
x = self.predict(x)
return x
net = Net(1,10,1)
print(net)
#到此為止,神經網路就算是搭建完成了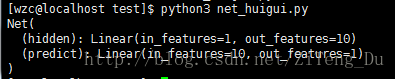
總結下以上的一些類:
- torch.Tensor是一個多維陣列,於ndarrary類似,只不過可以利用張量在GPU上加速運算
- Variable:是神經網路內的變數,variable不僅含有資料,也包括資料在神經網路中的一些操作行為,換句話說variable就是用來包裝tensor,並且記錄tensor資料在網路中的歷史操作,variable有梯度grad。
- nn.Module 是一個神經網路模組,說白了就是一個封裝好的網路,包含初始化,網路中每層的定義等,我們可以通過繼承這個類,重寫它的函式來方便的形成我們自己的網路。
- torch.functional是torch的方法類,用來獲得激勵函式。
計算損失函式並更新權重:
我們使用神經網路的優化器來對網路引數進行優化,,torch.optim中有很多optimizer,這裡使用的是SGD,net.parameters()就是網路中所有的引數,lr是學習率,學習率越高,學習的越快,但是學習的越快就會忽視一些內容,造成學習效率並不高的結果,所以一般lr小於1。
損失函式採用(output,target)輸入對,並計算預測輸出結果與實際目標的距離。
在nn包裡有幾種不同的損失函式,一個簡單的損失函式是nn.MSELoss計算輸出和目標之間的均方誤差,迴歸問題用這個就足夠了,如果是分類問題,就用另外一個,下面會提到
optimizer = torch.optim.SGD(net.parameters(),lr=0.5)#定義優化器
loss_func = torch.nn.MSELoss() #計算損失值
#開始訓練
for t in range(100):
prediction = net(x) #經過網路得到結果
loss = loss_func(prediction,y) #計算預測值與真實值之間的距離,注意順序,loss_func(預測值,真實值),因為反過來有可能會出錯。
optimizer.zero_grad() #把之前的梯度清零,否則梯度會累加之前的梯度(詳細的原因還在探究中,稍後補上)
loss.backward() #進行反向誤差傳播,計算各結點梯度
optimizer.step() #用optimizer優化更新網路引數
(2)分類神經網路
整體的程式碼和迴歸其實都差不多,只需修改下資料和損失函式。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
n_data = torch.ones(100,2)
x0 = torch.normal (2*n_data,1)
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data,1)
y1 = torch.ones(100)
x = torch.cat((x0.x1),0).type(torch.FloatTensor)
y = torch.cat((y0,y1),).type(torch.LongTensor)
x,y = Variable(x), Variable(y)
class Net(torch.nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_feature,n_hidden)
self.predict = torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(2,10,2)
print(net)
optimizer = torch.optim.SGD(net.parameters(),lr=0.02)
loss_func = torch.nn.CrossEntropyLoss()
for t in range(100):
prediction = net(x)
loss = loss_func(prediction,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()相關推薦
PyTorch動態神經網路(二)
利用PyTorch搭建神經網路 神經網路可以使用PyTorch的torch.nn包來構建。 autograd實現了反向傳播的功能,但是直接用來深度學習的程式碼在很多情況下還是稍顯複雜。 torch.nn是專門為神經網路設計的模組化介面,nn構建於autog
PyTorch動態神經網路(一)
PyTorch是什麼? 它是一個基於Python的科學計算包,其主要是為了解決兩類場景: 1、一種是可以替代Numpy進行科學計算,同時還可以使用張量在GPU上進行加速運算。 2、一個深度學習的研究平臺,提供最大的靈活性和速度。 一、Tensors(張量
搭建簡單圖片分類的卷積神經網路(二)-- CNN模型與訓練
一、首先,簡單來說CNN卷積神經網路與BP神經網路主要區別在於: 1、網路的層數的多少(我這裡的CNN是比較簡單的,層數較少,真正應用的話,層數是很多的)。 2、CNN名稱來說,具有卷積運算的特點,對於大型的圖片或者數量多的圖片,卷積運算可以大量提高計算效能,而BP神經網路大都為全連線層,計
機器學習-神經網路(二)
上一篇:機器學習-神經網路(一) 神經網路的代價函式 符號 意義 L
神經網路(二):Softmax函式與多元邏輯迴歸
一、 Softmax函式與多元邏輯迴歸 為了之後更深入地討論神經網路,本節將介紹在這個領域裡很重要的softmax函式,它常被用來定義神經網路的損失函式(針對分類問題)。 根據機器學習的理論,二元邏輯迴歸的模型公式可以寫為如下的形式: (1)P(y=1)=11
人工神經網路(二)單層感知器
本篇文章,我們開始介紹最簡單的神經網路結構,感知器,在瞭解原理的基礎上,下篇部落格我們程式碼實現一個單層感知器: 感知器: 人工神經網路的第一個里程碑是感知機perceptron, 這個名字其實有點誤導, 因為它根本上是做決策的。 一個感知機其實是對神經元最基本概念的
卷積神經網路(二):應用簡單卷積網路實現MNIST數字識別
卷積神經網路簡單實現MNIST數字識別 本篇的主要內容: 一個兩層卷積層的簡單卷積網路的TensorFlow的實現 網路的結構 在這張圖裡,我把每一層的輸入以及輸出的結構都標註了,結合閱讀程式碼食用效果更佳。 具體程式碼 具體的內容,都寫在相應位置的註釋中
機器學習與神經網路(二):感知器的介紹和Python程式碼實現
前言:本篇博文主要介紹感知器的相關知識,採用理論+程式碼實踐的方式,進行感知器的學習。本文首先介紹感知器的模型,然後介紹感知器學習規則(Perceptron學習演算法),最後通過Python程式碼實現單層感知器,從而給讀者一個更加直觀的認識。 1.單層感知器模型 單層感知器
Matlab實現BP神經網路和RBF神經網路(二)
在上一篇博文中:Matlab實現BP神經網路和RBF神經網路(一) 中,我們討論了BP網路設計部分,下面我們將設計RBF網路並將它們結果與SVM對比。 資料格式不變,詳情請看上一篇博文。 RBF神經網路: RBF網路和BP網路都是非線性多層前向網路,它們都
嘗試用google colab訓練自己的神經網路(二)
接下來我們要讀取資料了,首先掛載google drive:# Install the PyDrive wrapper & import libraries. # This only needs to be done once per notebook. !pip in
卷積神經網路(CNN)之一維卷積、二維卷積、三維卷積詳解
由於計算機視覺的大紅大紫,二維卷積的用處範圍最廣。因此本文首先介紹二維卷積,之後再介紹一維卷積與三維卷積的具體流程,並描述其各自的具體應用。 1. 二維卷積 圖中的輸入的資料維度為14×1414×14,過濾器大小為5×55×5,二者做卷積,輸出的資料維度為10×1
機器學習筆記(六)-吳恩達視訊課程(神經網路學習 二)
1.代價函式 神經網路層數L,表示L層(最後一層)神經元個數,表示每層的輸出神經元數 二類分類:=1 輸出層有一個神經元,輸出的y是一個實數 y = 0 or 1 表示類別 多類別分類:一共有K類,則=K,輸出層有K個神經元,&nbs
【論文閱讀筆記】---二值神經網路(BNN)
二值網路是將權值W和隱藏層啟用值二值化為1或者-1。通過二值化操作,使模型的引數佔用更小的儲存空間(記憶體消耗理論上減少為原來的1/32倍,從float32到1bit);同時利用位操作來代替網路中的乘加運算,大大降低了運算時間。由於二值網路只是將網路的引數和啟用值二值化,並沒有改變網路的結構。因此我們主要關注
深度學習基礎(二)—— 從多層感知機(MLP)到卷積神經網路(CNN)
經典的多層感知機(Multi-Layer Perceptron)形式上是全連線(fully-connected)的鄰接網路(adjacent network)。 That is, every neuron in the network is connec
pytorch 卷積神經網路(alexnet)訓練中問題以及解決辦法(更新中)
上一篇部落格中使用的是pytorch中的預訓練模型效果較好。https://blog.csdn.net/pc1022/article/details/80440913這篇部落格是自己訓練 卷積神經網路,最開始以簡單的alexnet進行訓練。對alexnet程式碼有三個版本的:
用pytorch實現一個神經網路(一)
對於影象資料的resize問題: pytorch裡有幾種resize資料的方法: 1.torchvision.transforms.Resize:這個我始終沒用成,好像是伺服器上安裝的anacond
使用Python+TensorFlow2構建基於卷積神經網路(CNN)的ECG心電訊號識別分類(二)
## 心律失常資料庫 目前,國際上公認的標準資料庫包含四個,分別為美國麻省理工學院提供的MIT-BIH(Massachusetts Institute of Technology-Beth Israel Hospital Database, MIT-BIH)資料庫、美國心臟學會提供的AHA( America
神經網路(三) 反向傳播直觀理解
oid 得到 文本分類 默認 img 自己 src 模型 com 這是典型的三層神經網絡的基本構成,Layer L1是輸入層,Layer L2是隱含層,Layer L3是隱含層,我們現在手裏有一堆數據{x1,x2,x3,...,xn},輸出也是一堆數據{y1,y2,y3,.
卷積神經網路(CNN)在語音識別中的應用
卷積神經網路(CNN)在語音識別中的應用 作者:侯藝馨 前言 總結目前語音識別的發展現狀,dnn、rnn/lstm和cnn算是語音識別中幾個比較主流的方向。2012年,微軟鄧力和俞棟老師將前饋神經網路FFDNN(Feed Forward Deep Neural Network)引入到聲學模
從迴圈神經網路(RNN)到LSTM網路
通常,資料的存在形式有語音、文字、影象、視訊等。因為我的研究方向主要是影象識別,所以很少用有“記憶性”的深度網路。懷著對迴圈神經網路的興趣,在看懂了有關它的理論後,我又看了Github上提供的tensorflow實現,覺得收穫很大,故在這裡把我的理解記錄下來,也希望對大家能有所幫助。