
多通道(比如RGB三通道)卷積過程
今天一個同學問 卷積過程好像是對 一個通道的影象進行卷積, 比如10個卷積核,得到10個feature map, 那麼輸入影象為RGB三個通道呢,輸出就為 30個feature map 嗎, 答案肯定不是的, 輸出的個數依然是 卷積核的個數。 可以檢視常用模型,比如lenet 手寫體,Alex imagenet 模型, 每一層輸出feature map 個數 就是該層卷積核的個數。
1、 一通道單個卷積核卷積過程
2、 一通道 多個卷積核卷積過程
一個卷積核得到的特徵提取是不充分的,我們可以新增多個卷積核,比如32個卷積核,可以學習32種特徵。在有多個卷積核時,如下圖所示:輸出就為32個feature map

3、 多通道的多個卷積核
下圖展示了在四個通道上的卷積操作,有兩個卷積核,生成兩個通道。其中需要注意的是,四個通道上每個通道對應一個卷積核,先將w2忽略,只看w1,那麼在w1的某位置(i,j)處的值,是由四個通道上(i,j)處的卷積結果相加然後再取啟用函式值得到的。 所以最後得到兩個feature map, 即輸出層的卷積核核個數為 feature map 的個數。


所以,在上圖由4個通道卷積得到2個通道的過程中,引數的數目為4×2×2×2個,其中4表示4個通道,第一個2表示生成2個通道,最後的2×2表示卷積核大小。
下面是常見模型, 理解一下 每層feature map 個數,為上一層卷積核的個數
下圖即為Alex的CNN結構圖。需要注意的是,該模型採用了2-GPU並行結構,即第1、2、4、5卷積層都是將模型引數分為2部分進行訓練的。在這裡,更進一步,並行結構分為資料並行與模型並行。資料並行是指在不同的GPU上,模型結構相同,但將訓練資料進行切分,分別訓練得到不同的模型,然後再將模型進行融合。而模型並行則是,將若干層的模型引數進行切分,不同的GPU上使用相同的資料進行訓練,得到的結果直接連線作為下一層的輸入。

上圖模型的基本引數為:
輸入:224×224大小的圖片,3通道
第一層卷積:5×5大小的卷積核96個,每個GPU上48個。
第一層max-pooling:2×2的核。
第二層卷積:3×3卷積核256個,每個GPU上128個。
第二層max-pooling:2×2的核。
第三層卷積:與上一層是全連線,3*3的卷積核384個。分到兩個GPU上個192個。
第四層卷積:3×3的卷積核384個,兩個GPU各192個。該層與上一層連線沒有經過pooling層。
第五層卷積:3×3的卷積核256個,兩個GPU上個128個。
第五層max-pooling:2×2的核。
第一層全連線:4096維,將第五層max-pooling的輸出連線成為一個一維向量,作為該層的輸入。
第二層全連線:4096維
Softmax層:輸出為1000,輸出的每一維都是圖片屬於該類別的概率。
4 DeepID網路結構
DeepID網路結構是香港中文大學的Sun Yi開發出來用來學習人臉特徵的卷積神經網路。每張輸入的人臉被表示為160維的向量,學習到的向量經過其他模型進行分類,在人臉驗證試驗上得到了97.45%的正確率,更進一步的,原作者改進了CNN,又得到了99.15%的正確率。
如下圖所示,該結構與ImageNet的具體引數類似,所以只解釋一下不同的部分吧。

上圖中的結構,在最後只有一層全連線層,然後就是softmax層了。論文中就是以該全連線層作為影象的表示。在全連線層,以第四層卷積和第三層max-pooling的輸出作為全連線層的輸入,這樣可以學習到區域性的和全域性的特徵。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
下面講一下,caffe中的實現。

Caffe中的卷積計算是將卷積核矩陣和輸入影象矩陣變換為兩個大的矩陣A與B,然後A與B進行矩陣相乘得到結果C(利用GPU進行矩陣相乘的高效性),三個矩陣的說明如下:
(1)在矩陣A中
M為卷積核個數,K=k*k,等於卷積核大小,即第一個矩陣每行為一個卷積核向量(是將二維的卷積核轉化為一維),總共有M行,表示有M個卷積核。
(2)在矩陣B中
N=((image_h + 2*pad_h – kernel_h)/stride_h+ 1)*((image_w +2*pad_w – kernel_w)/stride_w + 1)
image_h:輸入影象的高度
image_w:輸入影象的寬度
pad_h:在輸入影象的高度方向兩邊各增加pad_h個單位長度(因為有兩邊,所以乘以2)
pad_w:在輸入影象的寬度方向兩邊各增加pad_w個單位長度(因為有兩邊,所以乘以2)
kernel_h:卷積核的高度
kernel_w:卷積核的寬度
stride_h:高度方向的滑動步長;
stride_w:寬度方向的滑動步長。
因此,N為輸出影象大小的長寬乘積,也是卷積核在輸入影象上滑動可擷取的最大特徵數。
K=k*k,表示利用卷積核大小的框在輸入影象上滑動所擷取的資料大小,與卷積核大小一樣大。
(3)在矩陣C中
矩陣C為矩陣A和矩陣B相乘的結果,得到一個M*N的矩陣,其中每行表示一個輸出影象即feature map,共有M個輸出影象(輸出影象數目等於卷積核數目)
(在Caffe中是使用src/caffe/util/im2col.cu中的im2col和col2im來完成矩陣的變形和還原操作)
舉個例子(方便理解):
假設有兩個卷積核為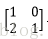
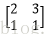
輸入影象矩陣為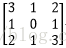
故N=[(3+2*0-2)/1+1]*[ (3+2*0-2)/1+1]=2*2=4
A矩陣(M*K)為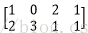
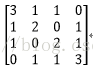
A 矩陣的由來:::
B矩陣的由來:(caffe 有 imtocol.cpp程式碼,專門用於實現)
C=A*B=
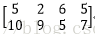
C中的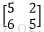
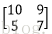
在Caffe原始碼中,src/caffe/util/math_functions.cu(如果使用CPU則是src/util/math_functions.cpp)中的caffe_gpu_gemm()函式,其中有兩個矩陣A(M*K)
與矩陣 B(K*N),大家可以通過輸出M、K、N的值即相應的矩陣內容來驗證上述的原理,程式碼中的C矩陣與上述的C矩陣不一樣,程式碼中的C矩陣儲存的是偏置bias,
是A 與B相乘後得到M*N大小的矩陣,然後再跟這個儲存偏置的矩陣C相加完成卷積過程。如果是跑Mnist訓練網路的話,可以看到第一個卷積層卷積過程中,
M=20,K=25,N=24*24=576。
(caffe中涉及卷積具體過程的檔案主要有:src/caffe/layers/conv_layer.cu、src/caffe/layers/base_conv_layer.cpp、 src/caffe/util/math_functions.cu、src/caffe/util/im2col.cu)
(對於他給出的ppt上的C表示影象通道個數,如果是RGB影象則通道數為3,對應於caffe程式碼中的變數為src/caffe/layers/base_conv_layer.cpp中
函式forward_gpu_gemm中的group_)
賈揚清的PPT如下:
下面看這個就簡單多了, im2col.cpp 的程式碼也好理解了
相關推薦
多通道(比如RGB三通道)卷積過程
今天一個同學問 卷積過程好像是對 一個通道的影象進行卷積, 比如10個卷積核,得到10個feature map, 那麼輸入影象為RGB三個通道呢,輸出就為 30個feature map 嗎, 答案肯定不是的, 輸出的個數依然是 卷積核的個數。 可以檢視常用模型,比如lene
多通道(比方RGB三通道)卷積過程
borde caff 一個 特征 結構 load 核數 alt log 今天一個同學問 卷積過程好像是對 一個通道的圖像進行卷積, 比方10個卷積核,得到10個feature map, 那麽輸入圖像為RGB三個通道呢,輸出就為 30個feature map 嗎, 答
TensorFlow官方文件樣例——三層卷積神經網路訓練MNIST資料
上篇部落格根據TensorFlow官方文件樣例實現了一個簡單的單層神經網路模型,在訓練10000次左右可以達到92.7%左右的準確率。但如果將神經網路的深度拓展,那麼很容易就能夠達到更高的準確率。官方中文文件中就提供了這樣的樣例,它的網路結構如
RGB彩圖卷積過程
轉載自:http://lib.csdn.net/article/aimachinelearning/42986 在CNN中,濾波器filter(帶著一組固定權重的神經元)對區域性輸入資料進行卷積計算。每計算完一個數據視窗內的區域性資料後,資料視窗不斷平移滑動,直到計算完所有資料。這個過程中,有這
最臨近 雙線性 三次卷積插值(影象放縮)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
卷積神經網路(CNN)之一維卷積、二維卷積、三維卷積詳解
由於計算機視覺的大紅大紫,二維卷積的用處範圍最廣。因此本文首先介紹二維卷積,之後再介紹一維卷積與三維卷積的具體流程,並描述其各自的具體應用。 1. 二維卷積 圖中的輸入的資料維度為14×1414×14,過濾器大小為5×55×5,二者做卷積,輸出的資料維度為10×1
[DeeplearningAI筆記]卷積神經網路4.11一維和三維卷積
4.4特殊應用:人臉識別和神經網路風格轉換 覺得有用的話,歡迎一起討論相互學習~Follow Me 4.11一維和三維卷積 二維和一維卷積 * 對於2D卷積來說,假設原始影象為1
神經網路的現狀、未來(從BP—CNN—RNN—GAN—GNN圖網路—CAP三維卷積膠囊模型及融合)
人工神經網路是計算智慧和機器學習研究的最活躍的分支之一 ,它是從人腦的生理結構出發 ,探討人類智慧活動的機理 。 從 1943 年 McCulloch 和 Pit ts 首先提出 M P 神經元數學模型開始 ,神經網路的研究大致經過了 1947 ~ 1969 年
最臨近、雙線性、三次卷積插值演算法比較
//原文:http://blog.csdn.net/google0802/article/details/8938849 【我只是想把最近鄰這個弄過來╮(╯-╰)╭ 】 插值演算法對於縮放比例較小的情況是完全可以接受的,令人信服的。一般的,縮小0.5倍以上或放大3.
三維卷積:全景影象Spherical CNNs(Code)
卷積神經網路(CNN)可以很好的處理二維平面圖像的問題。然而,對球面影象進行處理需求日益增加。例如,對無人機、機器人、自動駕駛汽車、分子迴歸問題、全球天氣和氣候模型的全方位視覺處理問題。 將球形訊號的平面投影作為卷積神經網路的輸入的這種Too
最近鄰、雙線性、三次卷積插值
轉載最鄰近插值(近鄰取樣法): 最臨近插值的的思想很簡單。對於通過反向變換得到的的一個浮點座標,對其進行簡單的取整,得到一個整數型座標,這個整數型座標對應的畫素值就是目的畫素的畫素值,也就是說,取浮點座標最鄰近的左上角點(對於DIB是右上角,因為它的掃描行是逆序儲存的)對應
【TensorFlow】第三課 卷積神經網路與影象應用
一,Image classification popeline 一般來說想要使用純程式設計的方式來讓機器識別一張圖片中的東西是非常困難的,常用的方法就是使用一些運算元來獲取影象中的很多的特徵,然後使用
深度學習三:卷積神經網路
# 卷積神經網路 **卷積神經網路(Convolutional Neural Network,CNN)**又叫**卷積網路(Convolutional Network)**,是一種專門用來處理具有類似網格結構的資料的神經網路。卷積神經網路一詞中的卷積是一種特殊的線性運算。卷積網路是指那些至少在網路的一層中使
CNN 的卷積過程為什麼 要將卷積核旋轉180°
CNN(卷積神經網路)的誤差反傳(error back propagation)中有一個非常關鍵的的步驟就是將某個卷積(Convolve)層的誤差傳到前一層的池化(Pool)層上,因為在CNN中是2D反傳,與傳統神
c++實現卷積過程
直接上程式碼: #include<iostream> #include<vector> using namespace std; int main() { //定義被卷積的矩陣(其實是一個數組,陣列元素的個數8*8)
[DeeplearningAI筆記卷積神經網絡1.6-1.7構造多通道卷積神經網絡
結果 一起 步驟 mar ref deep 右移 最終 inline 4.1卷積神經網絡 覺得有用的話,歡迎一起討論相互學習~Follow Me 1.6多通道卷積 原理 對於一個多通道的卷積操作,可以將卷積核設置為一個立方體,則其從左上角開始向右移動然後向下移動,這裏設
多通道影象卷積基礎知識介紹
轉:https://blog.csdn.net/williamyi96/article/details/77648047 1.對於單通道影象+單卷積核做卷積 Conv layers包含了conv,pooling,relu三種層。以python版本中的VGG16模型中的faster_rcnn_
多通道卷積後通道數計算理解
記憶為:卷積的深度(通道數)和卷積核的個數一致。 1、單通道卷積 &
多通道影象卷積
#1.三通道卷積 ##1.1通過設定不同filter 我們在進行影象處理的時候回遇到有色彩的影象,一般都是RGB,三個通道。 這個時候原始矩陣就變成了三維的,他們分別是原來的兩個維度寬width和高he
TensorFlow多通道卷積技術的演示
import cifar10_input import tensorflow as tf import numpy as np batch_size = 128 data_dir = '/tmp/cifar10_data/cifar-10-batches-bin' print("begin") images_