
GBDT(Gradient Boosting Decision Tree) 沒有實現只有原理
阿彌陀佛,好久沒寫文章,實在是受不了了,特來填坑,最近實習了(ting)解(shuo)到(le)很多工業界常用的演算法,諸如GBDT,CRF,topic model的一些演算法等,也看了不少東西,有時間可以詳細寫一下,而至於實現那真的是沒時間沒心情再做了,等回學校了再說吧。今天我們要說的就是GBDT(Gradient Boosting Decision Tree)
=======================================================================
〇.前序
GBDT是看一個大牛團隊做推薦演算法比賽的時候拿這個模型來處理最後得到的所有的feature並輸出結果的模型,想到自己以前天真地拿著SVD單模型調參參加這類比賽的時候真是……聞者傷心,聽著流淚啊,別的不談,這次講GBDT主要是因為了解GBDT的一些前置條件我都在部落格裡寫過,可以直接跳到關鍵部分開寫……進入正題吧
一.前置條件
1.決策樹
雖然裡面寫的都是決策分類樹,而我們這次主講的是決策迴歸樹,不過其實都差不多,決策迴歸樹呢就是把分到某個分支上的所有訓練樣例的目標值求平均或者取中位數返回而已。
2.boosting
一般來說哦講boosting都以adaboost這個特例開始講,所以你可以先看一看我的這篇部落格:AdaBoost--從原理到實現
然後我們來接著講boosting……新開一章吧,這個其實是主要內容
二.boosting 提升方法
提升方法其實是一個比adaboost概念更大的演算法,因為adaboost可以表示為boosting的前向分佈演算法(Forward stagewise additive modeling)
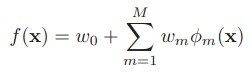
其中的w是權重,Φ是弱分類器(迴歸器)的集合,其實就是一個加法模型(即基函式的線性組合)
前向分佈演算法實際上是一個貪心的演算法,也就是在每一步求解弱分類器Φ(m)和其引數w(m)的時候不去修改之前已經求好的分類器和引數:

為了表示方便,我們以後用β代替w進行描述了,圖中的b是之前說的Φ弱分類器
OK,這也就是提升方法(之前向分佈演算法)的大致結構了,可以看到其中存在變數的部分其實就是極小化損失函式
三.各種提升方法
不同的損失函式和極小化損失函式方法決定了boosting的最終效果,我們現在來說幾個常見的boosting:
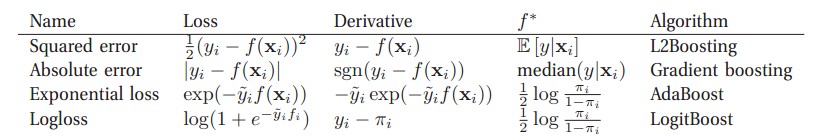
(圖自 Machine Learning A Probabilistic Perspective)對於二分類問題來說:其中πi=sigm(2f(xi)) ,y~i∈{-1,+1},yi∈{0,1}
廣義上來講,所謂的Gradient Boosting 其實就是在更新的時候選擇梯度下降的方向來保證最後的結果最好,一些書上講的“殘差” 方法其實就是L2Boosting吧,因為它所定義的殘差其實就是L2Boosting的Derivative,接下來我們著重講一下弱迴歸器(不知道叫啥了,自己編的)是決策樹的情況,也就是GBDT。(不知道為何上表的Absolute被命名為了Gradient boosting,關於Gradient boosting在後面會有更細緻的介紹)
四.GBDT
對於決策樹,其實可以把它表示為下式,即是把特徵空間劃分為多個區域,每個區域返回某個值作為決策樹的預測值
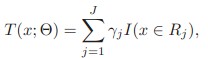
其中Rj是區域,γ是返回值,I()在其中的條件成立情況下為1,否則為0.其中的引數J可以大概看做樹的深度的一個表示,這是一個待調的引數
我們知道Gradient Boosting最重要的一步就是去擬合下式:
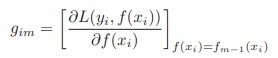
對於不同的Loss function,其梯度有不同的表示式:

(圖自The Elements of Statisic Learning)
前三種對應的loss function如下圖:其中Huber是低於某個值表現為square error,高於某個值則表現為線性
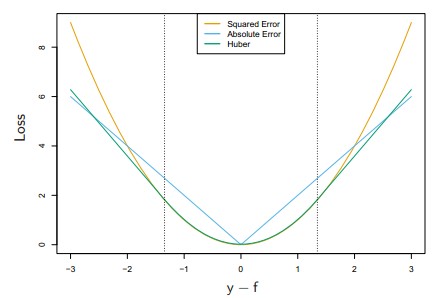
下面是GBDT的大概框架:(Gradient Tree Boosting應該是GBDT另一種說法,有誤請指正)

(演算法自TheElementsofStatisticalLearning)
整個框架描述得其實已經很清晰了,就不在這裡贅述了,總之所謂Gradient就是去擬合Loss function的梯度,將其作為新的弱迴歸樹加入到總的演算法中即可。
五.尾巴
本文大概寫了一下GBDT的框架和原理,後續其實還有涉及到引數的選擇(如樹的深度),正則化(regularization)等內容,主要是在實現的時候要注意,有時間會寫一份toy程式碼出來。
【Reference】
【1】《TheElementsofStatisticalLearning》
【2】《統計學習方法》
【3】《Machine Learning A Probabilistic Perspective》
相關推薦
GBDT(Gradient Boosting Decision Tree) 沒有實現只有原理
阿彌陀佛,好久沒寫文章,實在是受不了了,特來填坑,最近實習了(ting)解(shuo)到(le)很多工業界常用的演算法,諸如GBDT,CRF,topic model的一些演算法等,也看了不少東西,有時間可以詳細寫一下,而至於實現那真的是沒時間沒心情再
GBDT(Gradient boosting Decision Tree)梯度提升決策樹
參考資料 部落格1 GBDT演算法原理深入解析 這位大佬後面講了推導,讓我明白了這段話: Gradient Boosting是一種Boosting的方法,其與傳統的Boosting的區別是,每一次的計算是為了 **減少上一次的殘差(residual) **,而為了消除殘差,可以在殘差
Gradient Boosting Decision Tree (GBDT)
GBDT也是整合學習Boosting家族的成員,Boosting是各個基學習器之間有很強的依賴關係,即序列。GBDT限定了基學習器只能使用CART迴歸樹。 樹模型的優缺點: GBDT是一個加法模型,採用前向分步演算法進行求解。假設前一輪得到的模型是 ft−1(x)
梯度提升決策樹-GBDT(Gradient Boosting Decision Tree)
研究GBDT的背景是業務中使用到了該模型,用於做推薦場景,當然這裡就引出了GBDT的一個應用場景-迴歸,他的另外一個應用場景便是分類,接下來我會從以下幾個方面去學習和研究GBDT的相關知識,當然我也是學習者,只是把我理解到的整理出來。本文參考了網上
『機器學習筆記 』GBDT原理-Gradient Boosting Decision Tree
1. 背景 決策樹是一種基本的分類與迴歸方法。決策樹模型具有分類速度快,模型容易視覺化的解釋,但是同時是也有容易發生過擬合,雖然有剪枝,但也是差強人意。 提升方法(boosting)在分類問題中,它通過改變訓練樣本的權重(增加分錯樣本的權重,減
梯度提升決策樹(Gradient Boosting Decision Tree),用於分類或迴歸。
今天學習了梯度提升決策樹(Gradient Boosting Decision Tree, GBDT),準備寫點東西作為記錄。後續,我會用python 實現GBDT, 釋出到我的Github上,敬請Star。 梯度提升演算法是一種通用的學習演算法,除了決策樹,還可以使用其它模型作為基學習器。梯度提升演算法的
『 論文閱讀』LightGBM原理-LightGBM: A Highly Efficient Gradient Boosting Decision Tree
17年8月LightGBM就開源了,那時候就開始嘗試上手,不過更多還是在調參層面,在作者12月論文發表之後看了卻一直沒有總結,這幾天想著一定要翻譯下,自己也梳理下GBDT相關的演算法。 Abstract Gradient Boosting Decision Tr
Parallel Gradient Boosting Decision Trees
perfect mes etc som mos val swa enumerate gre 本文轉載自:鏈接 Highlights Three different methods for parallel gradient boosting decision tre
Decision Tree 及實現
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Gradient Boosting Decision trees: XGBoost vs LightGBM
Gradient boosting decision trees is the state of the art for structured data problems. Two modern algorithms that make gradient boosted tree models are XGB
機器學習技法課程學習筆記11 -- Gradient Boosted Decision Tree
上節課我們主要介紹了Random Forest演算法模型。Random Forest就是通過bagging的方式將許多不同的decision tree組合起來。除此之外,在decision tree中加入了各種隨機性和多樣性,比如不同特徵的線性組合等。RF還可以使用O
機器學習方法(四):決策樹Decision Tree原理與實現技巧
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術、應用感興趣的同學加入。 前面三篇寫了線性迴歸,lasso,和LARS的一些內容,這篇寫一下決策樹這個經典的分
機器學習:sklearn&pydotplus實現Decision Tree
import csv from sklearn.feature_extraction import DictVectorizer from sklearn import preprocessing from sklearn import tree import pydotplus ''' 資料集
【機器學習演算法-python實現】決策樹-Decision tree(1) 資訊熵劃分資料集
1.背景 決策書演算法是一種逼近離散數值的分類演算法,思路比較簡單,而且準確率較高。國際權威的學術組織,資料探勘國際會議ICDM (the IEEE International Con
機器學習經典演算法詳解及Python實現--決策樹(Decision Tree)
(一)認識決策樹 1,決策樹分類原理 決策樹是通過一系列規則對資料進行分類的過程。它提供一種在什麼條件下會得到什麼值的類似規則的方法。決策樹分為分類樹和迴歸樹兩種,分類樹對離散變數做決策樹,迴歸樹對連續變數做決策樹。 近來的調查表明決策樹也是最經常使用的資料探勘演算法,它
機器學習之決策樹(Decision Tree)及其Python程式碼實現
決策樹是一個預測模型;他代表的是物件屬性與物件值之間的一種對映關係。樹中每個節點表示某個物件,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經歷的路徑所表示的物
【Machine Learning】【Python】選擇最優引數(Decision Tree, Random Forest, Adaboost, GBDT)
之前訓練SVM用了PSO太慢了。 這次比較幸運看到一篇關於調參的部落格。 給了很大啟發。 不具體針對某種分類演算法詳細說了,這個真的需要大量實踐經驗,這也是我欠缺的。 我參考上面部落格做了一些實驗,準確率是在逐步提升,但因為我特徵處理這塊做的不好,準確率提升不明顯。 再
機器學習教程之13-決策樹(decision tree)的sklearn實現
0.概述 決策樹(decision tree)是一種基本的分類與迴歸方法。 主要優點:模型具有可讀性,分類速度快。 決策樹學習通常包括3個步驟:特徵選擇、決策樹的生成和決策樹的修剪。 1.決策樹模型與學習 節點:根節點、子節點;內部節點(inter
Decision Tree 1: Basis 決策樹基礎
entropy inf 屬於 得到 == bad spa span idt 介紹 我們有一些歷史數據: record id\attributes A B C Result 1 a1 b1 c1 Good 2 a2 b2 c1 Bad 3 a1 b3
機器學習入門 - 1. 介紹與決策樹(decision tree)
recursion machine learning programmming 機器學習(Machine Learning) 介紹與決策樹(Decision Tree)機器學習入門系列 是 個人學習過程中的一些記錄與心得。其主要以要點形式呈現,簡潔明了。1.什麽是機器學習?一個比較概括的理解是: