
基於Spark的FPGrowth(關聯規則演算法)
在推薦中,關聯規則推薦使用的比較頻繁,畢竟是通過概率來預測的,易於理解且準確度比較高,不過有一個缺點為,想要覆蓋推薦物品的數量,就要降低支援度與置信度。過高的支援度與置信度會導致物品覆蓋不過,這裡需要其他的推薦方法合作,建議使用基於Spark的模型推薦演算法(矩陣分解+ALS).
一FPGrowth演算法描述:
FPGrowth演算法
概念:支援度,置信度,提升度(Spark好像沒有計算這個的函式,需要自己計算)
列子:假如10000個消費者購買了商品,尿布1000個,啤酒2000個,麵包500個,同時購買了尿布和啤酒800個,同時購買了尿布和麵包100個。
1)支援度:在所有項集中出現的可能性,項集同時含有,x與y的概率。是第一道門檻,衡量量是多少,可以理解為‘出鏡率’,一般會支援初始值過濾掉低的規則。
尿布和啤酒的支援度為:800/10000=8%
2)置信度:在X發生的條件下,Y發生的概率。這是第二道門檻,衡量的是質量,設定最小的置信度篩選可靠的規則。
尿布-》啤酒的置信度為:800/1000=80%,啤酒-》尿布的置信度為:800/2000=40%
3)提升度:在含有x條件下同時含有Y的可能性(x->y的置信度)比沒有x這個條件下含有Y的可能性之比:confidence(尿布=> 啤酒)/概率(啤酒)) = 80%/((2000+800)/10000) 。如果提升度=1,那就是沒啥關係這兩個。
通過支援度和置信度可以得出強關聯關係,通過提升的,可判別有效的強關聯關係。
2 FPGrowth特點
1)產生候選集,2)只需要兩次遍歷資料庫,提高效率。
再舉個我們這裡的列子,列如時間的原因是,使用最近的行為訓練規則,太久的行為沒有意義
樣本如下:
列子:使用者,時間,消費的漫畫
u1,20160925,成都1995,seven,神獸退散。
u2,20160925,成都1995,seven,six。
u1,20160922,成都1995,惡魔日記
比如產生了如下規則:
規則:成都1995,seven->神獸退散
這條規則:
成都1995,seven的支援度2/3
成都1995,seven-》神獸退散,的置信度1/2
這裡打個廣告哈,成都1995,seven,神獸退散(漫畫)比較真的比較好看,成都1995也要拍網劇了哈!!
關聯規則主要的難道在於頻繁項集的篩選,apriori演算法就是一個一個組合的,如果item數量很多,那麼太慢了,FPGrowth演算法速度比較快。
我本身對FPGowth的樹形結構產生頻繁項集不是特別瞭解,以後可以研究下哈,核心點就是通過頭樹和樹減少遍歷次數吧
3
演算法
輸入:引數,樣本
輸出:規則
FPGrowth參考資料
參考資料
http://www.cnblogs.com/zhangchaoyang/articles/2198946.html
二Spark程式碼實現(修改了一下Spark的列子)
//資料樣本:
r z h k p
z y x w v u t s
s x o n r
x z y m t s q e
z
x z y r q t p package org.wq.scala.ml
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/10/24.
*/
object FP_GrowthTest {
def main(args:Array[String]){
val conf = new SparkConf().setAppName("FPGrowthTest").setMaster("local").set("spark.sql.warehouse.dir","E:/ideaWorkspace/ScalaSparkMl/spark-warehouse")
val sc = new SparkContext(conf)
//設定引數
//最小支援度
val minSupport=0.2
//最小置信度
val minConfidence=0.8
//資料分割槽
val numPartitions=2
//取出資料
val data = sc.textFile("data/mllib/sample_fpgrowth.txt")
//把資料通過空格分割
val transactions=data.map(x=>x.split(" "))
transactions.cache()
//建立一個FPGrowth的演算法實列
val fpg = new FPGrowth()
//設定訓練時候的最小支援度和資料分割槽
fpg.setMinSupport(minSupport)
fpg.setNumPartitions(numPartitions)
//把資料帶入演算法中
val model = fpg.run(transactions)
//檢視所有的頻繁項集,並且列出它出現的次數
model.freqItemsets.collect().foreach(itemset=>{
println( itemset.items.mkString("[", ",", "]")+","+itemset.freq)
})
//通過置信度篩選出推薦規則則
//antecedent表示前項
//consequent表示後項
//confidence表示規則的置信度
//這裡可以把規則寫入到Mysql資料庫中,以後使用來做推薦
//如果規則過多就把規則寫入redis,這裡就可以直接從記憶體中讀取了,我選擇的方式是寫入Mysql,然後再把推薦清單寫入redis
model.generateAssociationRules(minConfidence).collect().foreach(rule=>{
println(rule.antecedent.mkString(",")+"-->"+
rule.consequent.mkString(",")+"-->"+ rule.confidence)
})
//檢視規則生成的數量
println(model.generateAssociationRules(minConfidence).collect().length)
//並且所有的規則產生的推薦,後項只有1個,相同的前項產生不同的推薦結果是不同的行
//不同的規則可能會產生同一個推薦結果,所以樣本資料過規則的時候需要去重
}
}
上面規則是本地執行的,部署的話需要改下哈,程式碼如下
package org.wq.scala.ml
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/10/24.
*/
object FP_Growth {
def main(args:Array[String]){
if(args.length!=4){
println("請輸入4個引數 購物籃資料路徑 最小支援度 最小置信度 資料分割槽")
System.exit(0)
}
val conf = new SparkConf().setAppName("FPGrowthTest")
val sc = new SparkContext(conf)
val data_path=args(0)
//設定引數
//最小支援度
val minSupport=args(1).toDouble
//最小置信度
val minConfidence=args(2).toDouble
//資料分割槽
val numPartitions=args(3).toInt
//取出資料
val data = sc.textFile(data_path)
//把資料通過空格分割
val transactions=data.map(x=>x.split(" "))
transactions.cache()
//建立一個FPGrowth的演算法實列
val fpg = new FPGrowth()
//設定訓練時候的最小支援度和資料分割槽
fpg.setMinSupport(minSupport)
fpg.setNumPartitions(numPartitions)
//把資料帶入演算法中
val model = fpg.run(transactions)
//檢視所有的頻繁項集,並且列出它出現的次數
model.freqItemsets.collect().foreach(itemset=>{
println( itemset.items.mkString("[", ",", "]")+","+itemset.freq)
})
//通過置信度篩選出推薦規則則
//antecedent表示前項
//consequent表示後項
//confidence表示規則的置信度
//這裡可以把規則寫入到Mysql資料庫中,以後使用來做推薦
//如果規則過多就把規則寫入redis,這裡就可以直接從記憶體中讀取了,我選擇的方式是寫入Mysql,然後再把推薦清單寫入redis
model.generateAssociationRules(minConfidence).collect().foreach(rule=>{
println(rule.antecedent.mkString(",")+"-->"+
rule.consequent.mkString(",")+"-->"+ rule.confidence)
})
//檢視規則生成的數量
println(model.generateAssociationRules(minConfidence).collect().length)
//並且所有的規則產生的推薦,後項只有1個,相同的前項產生不同的推薦結果是不同的行
//不同的規則可能會產生同一個推薦結果,所以樣本資料過規則的時候需要去重
}
}
三提交部署
上傳jar與資料到主節點

#然後把資料檔案scp到各個節點
cd /home/jar/data
scp sample_fpgrowth.txt spark@slave1:/home/jar/data/
scp sample_fpgrowth.txt spark@slave2:/home/jar/data/
然後提交給spark叢集執行
資料目錄:/home/jar/data
jar目錄:/home/jar
模型目錄:/home/jar/model
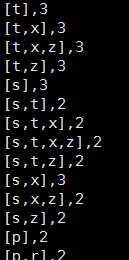
spark-submit --class org.wq.scala.ml.FP_Growth --master spark://master:7077 --executor-memory 700m --num-executors 1 /home/jar/FP_Growth.jar /home/jar/data/sample_fpgrowth.txt 0.2 0.8 2執行結果:
頻繁項集:
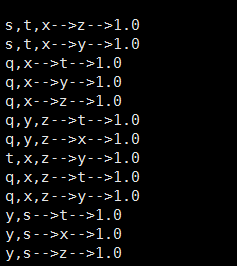
規則:
叢集跑job資訊

四:注意事項
1我使用了20w多樣本計算,近2000個物品,支援度5%,置信70%,訓練出來的規則很多,最後匹配的規則比較慢,而且物品的覆蓋比較少。所以把近2000的物品修改為主推的近500,這樣規則就減少了很多,切覆蓋的物品也比較多。具體引數自己試下哈,樣本和樣本的結構不一樣。
2FpGrowth的訓練其實比較快的,把樣本量提升到了50w,訓練的時間也是分鐘級別的,10分鐘左右吧,前提是支援度比高。在調整演算法的時間,支援度很重要,關係到執行的時間,我把支援度調整的很低的時候,演算法跑不出來,也會記憶體溢位(本身記憶體也不大哈)。不過時間多也無所謂,因為本身就是離線模型訓練哈。
3引數調整方案,多試試,覺得準確性和物品覆蓋比較滿意的時候就行了額,至於引數的自動迭代,完全沒什麼思路,除了輸入不同引數,求最好。
4訓練的時候資料能cache就cache哈,會比叫快哈
5 這個訓練中,6個樣本,都產生了85個規則,可以想象,樣本量大了之後,規則暴多,所以把規則寫入mysql,group by,group_concat()(會mysql的應該明白我說啥)可以合併規則,把置信度高的放在前面,當然自己寫程式碼可以哈。
s,t,x–>z–>1
s,t,x–>y–>1
合併為s,t,x–>z,y置信度高的在前面哈
相關推薦
基於Spark的FPGrowth(關聯規則演算法)
在推薦中,關聯規則推薦使用的比較頻繁,畢竟是通過概率來預測的,易於理解且準確度比較高,不過有一個缺點為,想要覆蓋推薦物品的數量,就要降低支援度與置信度。過高的支援度與置信度會導致物品覆蓋不過,這裡需要其他的推薦方法合作,建議使用基於Spark的模型推薦演算法(矩
sparkmllib關聯規則演算法(FPGrowth,Apriori)
關聯規則演算法的思想就是找頻繁項集,通過頻繁項集找強關聯。 介紹下基本概念: 對於A->B 1、置信度:P(B|A),在A發生的事件中同時發生B的概率 p(AB)/P(A)
python資料分析與挖掘學習筆記(6)-電商網站資料分析及商品自動推薦實戰與關聯規則演算法
這一節主要涉及到的資料探勘演算法是關聯規則及Apriori演算法。 由此展開電商網站資料分析模型的構建和電商網站商品自動推薦的實現,並擴充套件到協同過濾演算法。 關聯規則最有名的故事就是啤酒與尿布的故事,非常有效地說明了關聯規則在知識發現和資料探勘中起的作用和意義。 其中有
非監督學習演算法(聚類、降維、關聯規則挖掘)--機器學習--思維導圖手寫筆記(32)
一、思維導圖(點選圖方法) 二、補充筆記 三、K-means演算法的收斂性 說明: 當聚類中心μ確定時,求得的各個資料的cluster滿足聚類目標函式最小。 當資料cluster確
推薦演算法-關聯分析(關聯規則)
關聯分析又稱關聯挖掘,就是在交易資料、關係資料或其他資訊載體中,查詢存在於專案集合或物件集合之間的頻繁模式、關聯、相關性或因果結構。或者說,關聯分析是發現交易資料庫中不同商品(項)之間的聯絡。關聯分析是一種簡單、實用的分析技術,就是發現存在於大量資料集中的關聯性或相關性,從而描述了一個事物中某些屬性同時出現的
關聯規則演算法(Apriori)在Python上的實現
定義 關聯分析又稱關聯挖掘,就是在交易資料、關係資料或其他資訊載體中,查詢存在於專案集合或物件集合之間的頻繁模式、關聯、相關性或因果結構。可從資料庫中關聯分析出形如“由於某些事件的發生而引起另外一些事件的發生”之類的規則。如“67%的顧客在購買啤酒的同時也會購
HotSpot關聯規則演算法(1)-- 挖掘離散型資料
提到關聯規則演算法,一般會想到Apriori或者FP,一般很少有想到HotSpot的,這個演算法不知道是應用少還是我查資料的手段太low了,在網上只找到很少的內容,這篇http://wiki.pentaho.com/display/DATAMINING/HotSpo
基於pearson(皮爾遜)相似度的使用者推薦演算法
最近因為寫一些資料分析報告,把寫部落格的進度耽誤了一點,不過不要緊,我最近優化了一下做出的推薦演算法,用pearson相似度替換了歐氏距離相似度,優化了推薦演算法程式碼,另外將700多個使用者的推薦投資品迴圈計算了。 先說一下pearson相似度: pearson相似度與
推薦系統的初體驗(關聯規則,協同過濾)
關聯規則是資料探勘中的典型問題之一,又被稱為購物籃分析,這是因為傳統的關聯規則案例大多發生在超市中,例如所謂的啤酒與尿布傳說。事實上,“購物籃”這個詞也揭示了關聯規則挖掘的一個重要特點:以交易記錄為研究物件,每一個購物籃(transaction)就是一條記錄。關聯規則希望挖掘的規則就是:哪些商品會經常在同一個
機器學習——K-means演算法(聚類演算法)
聚類 在說K-means聚類演算法之前必須要先理解聚類和分類的區別。 分類其實是從特定的資料中挖掘模式,作出判斷的過程。比如Gmail郵箱裡有垃圾郵件分類器,一開始的時候可能什麼都不過濾,在日常使用過程中,我人工對於每一封郵件點選“垃圾”或“不是垃圾”,過一段時間,Gmail就體現出
sqrt函式實現(神奇的演算法)
我們平時經常會有一些資料運算的操作,需要呼叫sqrt,exp,abs等函式,那麼時候你有沒有想過:這個些函式系統是如何實現的?就拿最常用的sqrt函式來說吧,系統怎麼來實現這個經常呼叫的函式呢? 雖然有可能你平時沒有想過這個問題,不過正所謂
資料結構與演算法JavaScript描述讀書筆記(高階排序演算法)
希爾排序 在插入排序的基礎上,只不過比較的步長不一樣,插入排序比較步長一直是1(即一個一個的比較)。希爾排序的步長第一次一般設定為gap=Math.floor(arr.length/2),之後依次將步長設定為gap/2,直到步長變為1,這個時候徹底轉化成插入排 測試時間普通排序演算法1
資料結構與演算法JavaScript描述讀書筆記(基本排序演算法)
前提準備 //自動生成陣列的函式,n:整數個數,數字在l-r之間 function setData(n,l,r){ var dataStore = []; for(var i=0;i<n;i++){ dataStore[i] = Math.floor(
單源最短路——(Bellman-Ford演算法)超詳細
今天看了一下午的白書的Bellman-Ford演算法,由於能力有限,可能理解不到位。。。。 感覺就是遍歷所有邊更新點,如果有更新的點,繼續遍歷所有邊,直到沒有點更新就退出. #include <iostream> #include <stdio.h> #inc
關聯規則演算法Apriori以及FP-growth學習
關聯規則演算法Apriori以及FP-growth學習 最近選擇了關聯規則演算法進行學習,目標是先學習Apriori演算法,再轉FP-growth演算法,因為Spark-mllib庫支援的關聯演算法是FP,隨筆用於邊學邊記錄,完成後再進行整理 一、概述 關聯規則是一種常見的推薦演算法,用於從發現
八皇后問題(回溯的演算法)
八皇后問題是經典的回溯演算法案例,但是對初學者有點難以理解... 基本思路是,從第一個皇后開始放置,同時設定列和左斜和右斜放置標誌(如果是從列開始的就設定行的標誌) 第i行遍歷,如果沒有能夠放的位
Mr.J--HanioTower(遞迴演算法)
HanioTower(漢諾塔),資料結構高階遞迴中的經典問題,是每一個初學資料結構的同學必經之路,可能有的同學在學習C語言時候就已經遇見過這個問題。 漢諾塔的起源:相傳在古印度聖廟中,有一種被稱為漢諾塔(Hanoi)的遊戲。該遊戲是在一塊銅板裝置上,有三根杆(編號A、B、C),在A杆自下而上
BZOJ1494: [NOI2007]生成樹計數(Berlekamp-Massey演算法)
傳送門 題解: 直接打表+BM算出遞推式,BM具體實現可以戳這裡 附上一份其醜無比的BM程式碼: const int L=4e2; namespace bm { int cnt,a[N],fail[N],delta[N]; vector <int> R[N]
Raft演算法(zookeeper核心演算法)
轉自: https://www.cnblogs.com/mindwind/p/5231986.html Leslie Lamport 在三十多年前發表的論文《拜占庭將軍問題》(參考[1])。 拜占庭位於如今的土耳其的伊斯坦布林,是東羅馬帝國的首都。由於當時拜占庭羅馬帝國
《數學之美》第11章—如何確定網頁和查詢的相關性(TF-IDF演算法)
文章目錄 如何查詢關於“原子能的應用”的網頁? 大致思路 問題描述 解決過程 一、使用“總詞頻” 二、加入IDF權重 三、IDF概念的理論支