
基於深度學習的目標檢測研究進展
前言

開始本文內容之前,我們先來看一下上邊左側的這張圖,從圖中你看到了什麼物體?他們在什麼位置?這還不簡單,圖中有一個貓和一個人,具體的位置就是上圖右側影象兩個邊框(bounding-box)所在的位置。其實剛剛的這個過程就是目標檢測,目標檢測就是“給定一張影象或者視訊幀,找出其中所有目標的位置,並給出每個目標的具體類別”。
目標檢測對於人來說是再簡單不過的任務,但是對於計算機來說,它看到的是一些值為0~255的陣列,因而很難直接得到影象中有人或者貓這種高層語義概念,也不清楚目標出現在影象中哪個區域。影象中的目標可能出現在任何位置,目標的形態可能存在各種各樣的變化,影象的背景千差萬別……,這些因素導致目標檢測並不是一個容易解決的任務。
得益於深度學習——主要是卷積神經網路(convolution neural network: CNN)和候選區域(region proposal)演算法,從2014年開始,目標檢測取得了巨大的突破。本文主要對基於深度學習的目標檢測演算法進行剖析和總結,文章分為四個部分:第一部分大體介紹下傳統目標檢測的流程,第二部分介紹以R-CNN為代表的結合region proposal和CNN分類的目標檢測框架(R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN); 第三部分介紹以YOLO為代表的將目標檢測轉換為迴歸問題的目標檢測框架(YOLO, SSD); 第四部分介紹一些可以提高目標檢測效能的技巧和方法。

如上圖所示,傳統目標檢測的方法一般分為三個階段:首先在給定的影象上選擇一些候選的區域,然後對這些區域提取特徵,最後使用訓練的分類器進行分類。下面我們對這三個階段分別進行介紹。
1) 區域選擇
這一步是為了對目標的位置進行定位。由於目標可能出現在影象的任何位置,而且目標的大小、長寬比例也不確定,所以最初採用滑動視窗的策略對整幅影象進行遍歷,而且需要設定不同的尺度,不同的長寬比。這種窮舉的策略雖然包含了目標所有可能出現的位置,但是缺點也是顯而易見的:時間複雜度太高,產生冗餘視窗太多,這也嚴重影響後續特徵提取和分類的速度和效能。(實際上由於受到時間複雜度的問題,滑動視窗的長寬比一般都是固定的設定幾個,所以對於長寬比浮動較大的多類別目標檢測,即便是滑動視窗遍歷也不能得到很好的區域)
2) 特徵提取
由於目標的形態多樣性,光照變化多樣性,背景多樣性等因素使得設計一個魯棒的特徵並不是那麼容易。然而提取特徵的好壞直接影響到分類的準確性。(這個階段常用的特徵有SIFT、HOG等)
3) 分類器
主要有SVM, Adaboost等。
總結:傳統目標檢測存在的兩個主要問題:一個是基於滑動視窗的區域選擇策略沒有針對性,時間複雜度高,視窗冗餘;二是手工設計的特徵對於多樣性的變化並沒有很好的魯棒性。
二. 基於Region Proposal的深度學習目標檢測演算法對於傳統目標檢測任務存在的兩個主要問題,我們該如何解決呢?
對於滑動視窗存在的問題,region proposal提供了很好的解決方案。region proposal(候選區域)是預先找出圖中目標可能出現的位置。但由於region proposal利用了影象中的紋理、邊緣、顏色等資訊,可以保證在選取較少視窗(幾千個甚至幾百個)的情況下保持較高的召回率。這大大降低了後續操作的時間複雜度,並且獲取的候選視窗要比滑動視窗的質量更高(滑動視窗固定長寬比)。比較常用的region proposal演算法有selective Search和edge Boxes,如果想具體瞭解region proposal可以看一下PAMI2015的“What makes for effective detection proposals?”
有了候選區域,剩下的工作實際就是對候選區域進行影象分類的工作(特徵提取+分類)。對於影象分類,不得不提的是2012年ImageNet大規模視覺識別挑戰賽(ILSVRC)上,機器學習泰斗Geoffrey Hinton教授帶領學生Krizhevsky使用卷積神經網路將ILSVRC分類任務的Top-5 error降低到了15.3%,而使用傳統方法的第二名top-5 error高達 26.2%。此後,卷積神經網路佔據了影象分類任務的絕對統治地位,微軟最新的ResNet和谷歌的Inception V4模型的top-5 error降到了4%以內多,這已經超越人在這個特定任務上的能力。所以目標檢測得到候選區域後使用CNN對其進行影象分類是一個不錯的選擇。
2014年,RBG(Ross B. Girshick)大神使用region proposal+CNN代替傳統目標檢測使用的滑動視窗+手工設計特徵,設計了R-CNN框架,使得目標檢測取得巨大突破,並開啟了基於深度學習目標檢測的熱潮。
1)R-CNN (CVPR2014, TPAMI2015)
(Region-based Convolution Networks for Accurate Object detection and Segmentation)
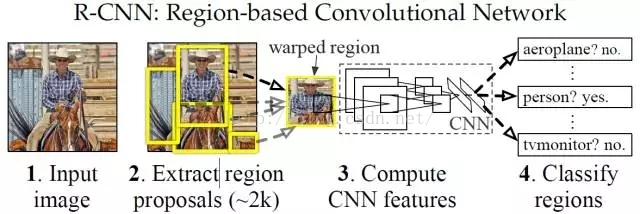
上面的框架圖清晰的給出了R-CNN的目標檢測流程:
(1) 輸入測試影象
(2) 利用selective search演算法在影象中提取2000個左右的region proposal。
(3) 將每個region proposal縮放(warp)成227x227的大小並輸入到CNN,將CNN的fc7層的輸出作為特徵。
(4) 將每個region proposal提取到的CNN特徵輸入到SVM進行分類。
針對上面的框架給出幾點解釋:
* 上面的框架圖是測試的流程圖,要進行測試我們首先要訓練好提取特徵的CNN模型,以及用於分類的SVM:使用在ImageNet上預訓練的模型(AlexNet/VGG16)進行微調得到用於特徵提取的CNN模型,然後利用CNN模型對訓練集提特徵訓練SVM。
* 對每個region proposal縮放到同一尺度是因為CNN全連線層輸入需要保證維度固定。
* 上圖少畫了一個過程——對於SVM分好類的region proposal做邊框迴歸(bounding-box regression),邊框迴歸是對region proposal進行糾正的線性迴歸演算法,為了讓region proposal提取到的視窗跟目標真實視窗更吻合。因為region proposal提取到的視窗不可能跟人手工標記那麼準,如果region proposal跟目標位置偏移較大,即便是分類正確了,但是由於IoU(region proposal與Ground Truth的視窗的交集比並集的比值)低於0.5,那麼相當於目標還是沒有檢測到。
小結:R-CNN在PASCAL VOC2007上的檢測結果從DPM HSC的34.3%直接提升到了66%(mAP)。如此大的提升使我們看到了region proposal+CNN的巨大優勢。
但是R-CNN框架也存在著很多問題:
(1) 訓練分為多個階段,步驟繁瑣: 微調網路+訓練SVM+訓練邊框迴歸器
(2) 訓練耗時,佔用磁碟空間大:5000張影象產生幾百G的特徵檔案
(3) 速度慢: 使用GPU, VGG16模型處理一張影象需要47s。
針對速度慢的這個問題,SPP-NET給出了很好的解決方案。
2)SPP-NET (ECCV2014, TPAMI2015)(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
先看一下R-CNN為什麼檢測速度這麼慢,一張圖都需要47s!仔細看下R-CNN框架發現,對影象提完region proposal(2000個左右)之後將每個proposal當成一張影象進行後續處理(CNN提特徵+SVM分類),實際上對一張影象進行了2000次提特徵和分類的過程!
有沒有方法提速呢?好像是有的,這2000個region proposal不都是影象的一部分嗎,那麼我們完全可以對影象提一次卷積層特徵,然後只需要將region proposal在原圖的位置對映到卷積層特徵圖上,這樣對於一張影象我們只需要提一次卷積層特徵,然後將每個region proposal的卷積層特徵輸入到全連線層做後續操作。(對於CNN來說,大部分運算都耗在卷積操作上,這樣做可以節省大量時間)。現在的問題是每個region proposal的尺度不一樣,直接這樣輸入全連線層肯定是不行的,因為全連線層輸入必須是固定的長度。SPP-NET恰好可以解決這個問題:
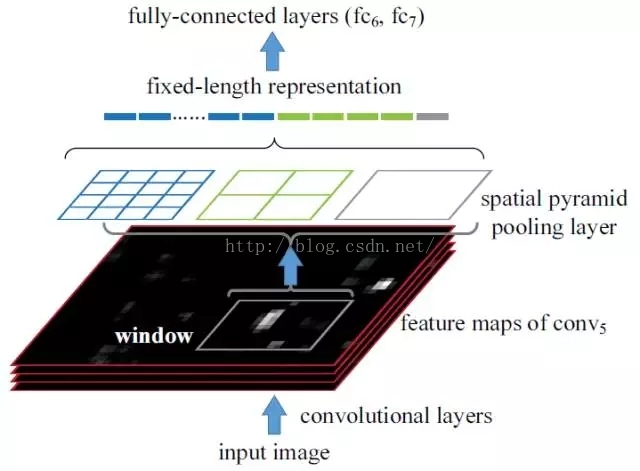
上圖對應的就是SPP-NET的網路結構圖,任意給一張影象輸入到CNN,經過卷積操作我們可以得到卷積特徵(比如VGG16最後的卷積層為conv5_3,共產生512張特徵圖)。圖中的window是就是原圖一個region proposal對應到特徵圖的區域,只需要將這些不同大小window的特徵對映到同樣的維度,將其作為全連線的輸入,就能保證只對影象提取一次卷積層特徵。SPP-NET使用了空間金字塔取樣(spatial pyramid pooling):將每個window劃分為4*4, 2*2, 1*1的塊,然後每個塊使用max-pooling下采樣,這樣對於每個window經過SPP層之後都得到了一個長度為(4*4+2*2+1)*512維度的特徵向量,將這個作為全連線層的輸入進行後續操作。
小結:使用SPP-NET相比於R-CNN可以大大加快目標檢測的速度,但是依然存在著很多問題:
(1) 訓練分為多個階段,步驟繁瑣: 微調網路+訓練SVM+訓練訓練邊框迴歸器
(2) SPP-NET在微調網路的時候固定了卷積層,只對全連線層進行微調,而對於一個新的任務,有必要對卷積層也進行微調。(分類的模型提取的特徵更注重高層語義,而目標檢測任務除了語義資訊還需要目標的位置資訊)
針對這兩個問題,RBG又提出Fast R-CNN, 一個精簡而快速的目標檢測框架。
3) Fast R-CNN(ICCV2015)
有了前邊R-CNN和SPP-NET的介紹,我們直接看Fast R-CNN的框架圖:
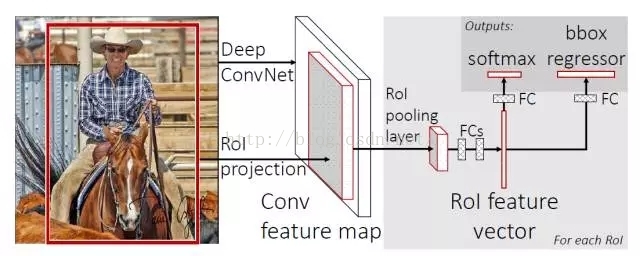
與R-CNN框架圖對比,可以發現主要有兩處不同:一是最後一個卷積層後加了一個ROI pooling layer,二是損失函式使用了多工損失函式(multi-task loss),將邊框迴歸直接加入到CNN網路中訓練。
(1) ROI pooling layer實際上是SPP-NET的一個精簡版,SPP-NET對每個proposal使用了不同大小的金字塔對映,而ROI pooling layer只需要下采樣到一個7x7的特徵圖。對於VGG16網路conv5_3有512個特徵圖,這樣所有region proposal對應了一個7*7*512維度的特徵向量作為全連線層的輸入。
(2) R-CNN訓練過程分為了三個階段,而Fast R-CNN直接使用softmax替代SVM分類,同時利用多工損失函式邊框迴歸也加入到了網路中,這樣整個的訓練過程是端到端的(除去region proposal提取階段)。
(3) Fast R-CNN在網路微調的過程中,將部分卷積層也進行了微調,取得了更好的檢測效果。
小結:Fast R-CNN融合了R-CNN和SPP-NET的精髓,並且引入多工損失函式,使整個網路的訓練和測試變得十分方便。在Pascal VOC2007訓練集上訓練,在VOC2007測試的結果為66.9%(mAP),如果使用VOC2007+2012訓練集訓練,在VOC2007上測試結果為70%(資料集的擴充能大幅提高目標檢測效能)。使用VGG16每張影象總共需要3s左右。
缺點:region proposal的提取使用selective search,目標檢測時間大多消耗在這上面(提region proposal 2~3s,而提特徵分類只需0.32s),無法滿足實時應用,而且並沒有實現真正意義上的端到端訓練測試(region proposal使用selective search先提取處來)。那麼有沒有可能直接使用CNN直接產生region proposal並對其分類?Faster R-CNN框架就是符合這樣需要的目標檢測框架。
4)Faster R-CNN(NIPS2015)
(Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
在region proposal + CNN分類的這種目標檢測框架中,region proposal質量好壞直接影響到目標檢測任務的精度。如果找到一種方法只提取幾百個或者更少的高質量的預選視窗,而且召回率很高,這不但能加快目標檢測速度,還能提高目標檢測的效能(假陽例少)。RPN(Region Proposal Networks)網路應運而生。
RPN的核心思想是使用卷積神經網路直接產生region proposal,使用的方法本質上就是滑動視窗。RPN的設計比較巧妙,RPN只需在最後的卷積層上滑動一遍,因為anchor機制和邊框迴歸可以得到多尺度多長寬比的region proposal。
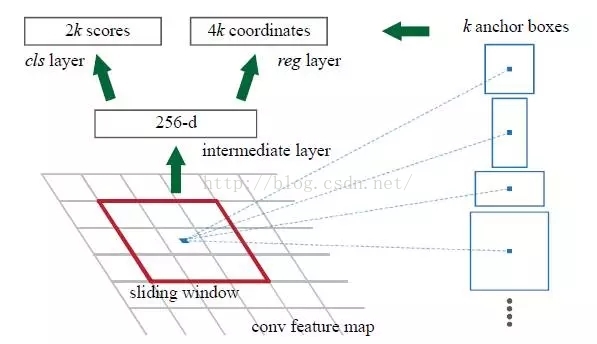
我們直接看上邊的RPN網路結構圖(使用了ZF模型),給定輸入影象(假設解析度為600*1000),經過卷積操作得到最後一層的卷積特徵圖(大小約為40*60)。在這個特徵圖上使用3*3的卷積核(滑動視窗)與特徵圖進行卷積,最後一層卷積層共有256個feature map,那麼這個3*3的區域卷積後可以獲得一個256維的特徵向量,後邊接cls layer和reg layer分別用於分類和邊框迴歸(跟Fast R-CNN類似,只不過這裡的類別只有目標和背景兩個類別)。3*3滑窗對應的每個特徵區域同時預測輸入影象3種尺度(128,256,512),3種長寬比(1:1,1:2,2:1)的region proposal,這種對映的機制稱為anchor。所以對於這個40*60的feature map,總共有約20000(40*60*9)個anchor,也就是預測20000個region proposal。
這樣設計的好處是什麼呢?雖然現在也是用的滑動視窗策略,但是:滑動視窗操作是在卷積層特徵圖上進行的,維度較原始影象降低了16*16倍(中間經過了4次2*2的pooling操作);多尺度採用了9種anchor,對應了三種尺度和三種長寬比,加上後邊接了邊框迴歸,所以即便是這9種anchor外的視窗也能得到一個跟目標比較接近的region proposal。
NIPS2015版本的Faster R-CNN使用的檢測框架是RPN網路+Fast R-CNN網路分離進行的目標檢測,整體流程跟Fast R-CNN一樣,只是region proposal現在是用RPN網路提取的(代替原來的selective search)。同時作者為了讓RPN的網路和Fast R-CNN網路實現卷積層的權值共享,訓練RPN和Fast R-CNN的時候用了4階段的訓練方法:
(1) 使用在ImageNet上預訓練的模型初始化網路引數,微調RPN網路;
(2) 使用(1)中RPN網路提取region proposal訓練Fast R-CNN網路;
(3) 使用(2)的Fast R-CNN網路重新初始化RPN, 固定卷積層進行微調;
(4) 固定(2)中Fast R-CNN的卷積層,使用(3)中RPN提取的region proposal微調網路。
權值共享後的RPN和Fast R-CNN用於目標檢測精度會提高一些。
使用訓練好的RPN網路,給定測試影象,可以直接得到邊緣迴歸後的region proposal,根據region proposal的類別得分對RPN網路進行排序,並選取前300個視窗作為Fast R-CNN的輸入進行目標檢測,使用VOC07+12訓練集訓練,VOC2007測試集測試mAP達到73.2%(selective search + Fast R-CNN是70%), 目標檢測的速度可以達到每秒5幀(selective search+Fast R-CNN是2~3s一張)。
需要注意的是,最新的版本已經將RPN網路和Fast R-CNN網路結合到了一起——將RPN獲取到的proposal直接連到ROI pooling層,這才是一個真正意義上的使用一個CNN網路實現端到端目標檢測的框架。
小結:Faster R-CNN將一直以來分離的region proposal和CNN分類融合到了一起,使用端到端的網路進行目標檢測,無論在速度上還是精度上都得到了不錯的提高。然而Faster R-CNN還是達不到實時的目標檢測,預先獲取region proposal,然後在對每個proposal分類計算量還是比較大。比較幸運的是YOLO這類目標檢測方法的出現讓實時性也變的成為可能。
總的來說,從R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走來,基於深度學習目標檢測的流程變得越來越精簡,精度越來越高,速度也越來越快。可以說基於region proposal的R-CNN系列目標檢測方法是當前目標最主要的一個分支。
三. 基於迴歸方法的深度學習目標檢測演算法Faster R-CNN的方法目前是主流的目標檢測方法,但是速度上並不能滿足實時的要求。YOLO一類的方法慢慢顯現出其重要性,這類方法使用了迴歸的思想,既給定輸入影象,直接在影象的多個位置上回歸出這個位置的目標邊框以及目標類別。
1)YOLO (CVPR2016, oral)
(You Only Look Once: Unified, Real-Time Object Detection)
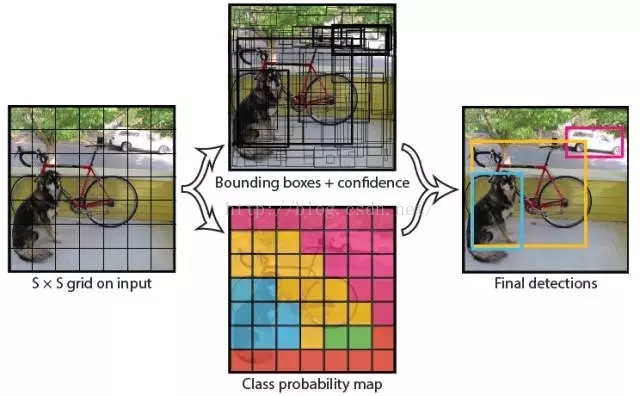
我們直接看上面YOLO的目標檢測的流程圖:
(1) 給個一個輸入影象,首先將影象劃分成7*7的網格
(2) 對於每個網格,我們都預測2個邊框(包括每個邊框是目標的置信度以及每個邊框區域在多個類別上的概率)
(3) 根據上一步可以預測出7*7*2個目標視窗,然後根據閾值去除可能性比較低的目標視窗,最後NMS去除冗餘視窗即可。
可以看到整個過程非常簡單,不需要中間的region proposal在找目標,直接回歸便完成了位置和類別的判定。

小結:YOLO將目標檢測任務轉換成一個迴歸問題,大大加快了檢測的速度,使得YOLO可以每秒處理45張影象。而且由於每個網路預測目標視窗時使用的是全圖資訊,使得false positive比例大幅降低(充分的上下文資訊)。但是YOLO也存在問題:沒有了region proposal機制,只使用7*7的網格迴歸會使得目標不能非常精準的定位,這也導致了YOLO的檢測精度並不是很高。
2)SSD(SSD: Single Shot MultiBox Detector)
上面分析了YOLO存在的問題,使用整圖特徵在7*7的粗糙網格內迴歸對目標的定位並不是很精準。那是不是可以結合region proposal的思想實現精準一些的定位?SSD結合YOLO的迴歸思想以及Faster R-CNN的anchor機制做到了這點。
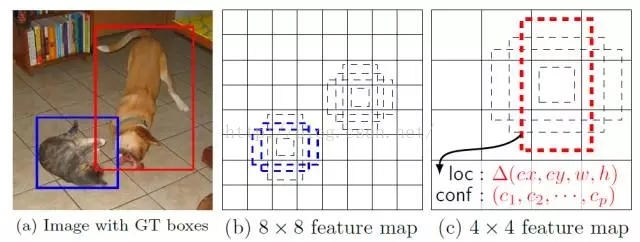
上圖是SSD的一個框架圖,首先SSD獲取目標位置和類別的方法跟YOLO一樣,都是使用迴歸,但是YOLO預測某個位置使用的是全圖的特徵,SSD預測某個位置使用的是這個位置周圍的特徵(感覺更合理一些)。那麼如何建立某個位置和其特徵的對應關係呢?可能你已經想到了,使用Faster R-CNN的anchor機制。如SSD的框架圖所示,假如某一層特徵圖(圖b)大小是8*8,那麼就使用3*3的滑窗提取每個位置的特徵,然後這個特徵迴歸得到目標的座標資訊和類別資訊(圖c)。
不同於Faster R-CNN,這個anchor是在多個feature map上,這樣可以利用多層的特徵並且自然的達到多尺度(不同層的feature map 3*3滑窗感受野不同)。
小結:SSD結合了YOLO中的迴歸思想和Faster R-CNN中的anchor機制,使用全圖各個位置的多尺度區域特徵進行迴歸,既保持了YOLO速度快的特性,也保證了視窗預測的跟Faster R-CNN一樣比較精準。SSD在VOC2007上mAP可以達到72.1%,速度在GPU上達到58幀每秒。
總結:YOLO的提出給目標檢測一個新的思路,SSD的效能則讓我們看到了目標檢測在實際應用中真正的可能性。
四. 提高目標檢測方法R-CNN系列目標檢測框架和YOLO目標檢測框架給了我們進行目標檢測的兩個基本框架。除此之外,研究人員基於這些框架從其他方面入手提出了一系列提高目標檢測效能的方法。
(1) 難分樣本挖掘(hard negative mining)
R-CNN在訓練SVM分類器時使用了難分樣本挖掘的思想,但Fast R-CNN和Faster R-CNN由於使用端到端的訓練策略並沒有使用難分樣本挖掘(只是設定了正負樣本的比例並隨機抽取)。CVPR2016的Training Region-based Object Detectors with Online Hard Example Mining(oral)將難分樣本挖掘(hard example mining)機制嵌入到SGD演算法中,使得Fast R-CNN在訓練的過程中根據region proposal的損失自動選取合適的region proposal作為正負例訓練。實驗結果表明使用OHEM(Online Hard Example Mining)機制可以使得Fast R-CNN演算法在VOC2007和VOC2012上mAP提高 4%左右。
(2) 多層特徵融合
Fast R-CNN和Faster R-CNN都是利用了最後卷積層的特徵進行目標檢測,而由於高層的卷積層特徵已經損失了很多細節資訊(pooling操作),所以在定位時不是很精準。HyperNet等一些方法則利用了CNN的多層特徵融合進行目標檢測,這不僅利用了高層特徵的語義資訊,還考慮了低層特徵的細節紋理資訊,使得目標檢測定位更精準。
(3) 使用上下文資訊
在提取region proposal特徵進行目標檢測時,結合region proposal上下文資訊,檢測效果往往會更好一些。(Object detection via a multi-region & semantic segmentation-aware CNN model以及Inside-Outside Net等論文中都使用了上下文資訊)
該文章屬於“深度學習大講堂”原創,如需要轉載,請聯絡@果果是枚開心果.
作者簡介:
王斌,中科院計算所前瞻研究實驗室跨媒體計算課題組博士生,導師張勇東研究員。研究方向為基於深度學習的目標檢測。2015年作為計算所MCG-ICT-CAS團隊成員,參加ImageNet競賽ILSVRC2015的目標檢測任務獲得全球第5名。
相關推薦
基於深度學習的目標檢測研究進展
前言 開始本文內容之前,我們先來看一下上邊左側的這張圖,從圖中你看到了什麼物體?他們在什麼位置?這還不簡單,圖中有一個貓和一個人,具體的位置就是上圖右側影象兩個邊框(bounding-box)所在的位置。其實剛剛的這個過程就是目標檢測,目標檢測就是“給定一張影象或者視訊幀,
深度學習目標檢測經典模型比較(RCNN、Fast RCNN、Faster RCNN)
深度學習目標檢測經典模型比較(RCNN、Fast RCNN、Faster RCNN) Faster rcnn是用來解決計算機視覺(CV)領域中目標檢測(Object Detection)的問題的。 區別目標分類、定位、檢測 一、傳統的目標檢測方法 其實目標檢
windows+tensorflow object detection api 深度學習目標檢測實踐
1、在github上下載tensorflow/model專案 1. 首先把protoc-win32資料夾下面的protoc.exe移至protobuf-python/src目錄下。 2. 在cmd中進入protobuf-python/python目錄,先執行a
深度學習目標檢測之YOLO系列
近年來目標檢測流行的演算法主要分為兩類:1、R-CNN系列的two-stage演算法(R-CNN、Fast R-CNN、Faster R-CNN),需要先使用啟發式方法selective search或者CNN網路RPN產生候選區域,然後在候選區域上進行分類和迴歸,準確度高但
深度學習目標檢測系列:faster RCNN實現|附python原始碼
目標檢測一直是計算機視覺中比較熱門的研究領域,有一些常用且成熟的演算法得到業內公認水平,比如RCNN系列演算法、SSD以及YOLO等。如果你是從事這一行業的話,你會使用哪種演算法進行目標檢測任務呢?在我尋求在最短的時間內構建最精確的模型時,我嘗試了其中的R-CNN系列演算法,如果讀者們對這方面的
深度學習目標檢測_01
基本上有三個月沒記錄具體的學習心得了。主要目前的研究重點放在影象識別和目標檢測上,所以這次就先開始寫寫目標檢測的內容,之後有時間再把理論學習的部分的坑填了。 目前而言,在目標檢測方面有不少的網路和模型,例如yolo、R-CNN、fast R-CNN等等,種類
深度學習目標檢測系列:一文弄懂YOLO演算法|附Python原始碼
在之前的文章中,介紹了計算機視覺領域中目標檢測的相關方法——RCNN系列演算法原理,以及Faster RCNN的實現。這些演算法面臨的一個問題,不是端到端的模型,幾個構件拼湊在一起組成整個檢測系統,操作起來比較複雜,本文將介紹另外一個端到端的方法——YOLO演算法,該方法操作簡便且模擬速度快,效
深度學習目標檢測模型全面綜述:Faster R-CNN、R-FCN和SSD
選自medium 機器之心編輯部 Faster R-CNN、R-FCN 和 SSD 是三種目前最優且應用最廣泛的目標檢測模型,其他流行的模型通常與這三者類似。本文介紹了深度學習目標檢測的三種常見模型:Faster R-CNN、R-FCN 和 SSD。 圖為機
深度學習-目標檢測綜述
二、目標檢測公共資料集 RuntimeWarning: invalid value encountered in log targets_dw = np.log(gt_widths / ex_widths) 那麼將lib/datasets/pasca
Matlab: 深度學習目標檢測xml標註資訊批量統計
""" https://blog.csdn.net/gusui7202/article/details/83239142 qhy。 """ 程式1:xml_read() #xml讀取 程式2:mian() #xml內容統計 使用:將兩個程式放入同一個資料夾
深度學習-目標檢測資料集以及評估指標
資料集和效能指標 目標檢測常用的資料集包括PASCAL VOC,ImageNet,MS COCO等資料集,這些資料集用於研究者測試演算法效能或者用於競賽。目標檢測的效能指標要考慮檢測物體的位置以及預測類別的準確性,下面我們會說到一些常用的效能評估指標。 資料集 PA
深度學習目標檢測(object detection)系列(四) Faster R-CNN
Faster R-CNN簡介 RBG團隊在2015年,與Fast R-CNN同年推出了Faster R-CNN,我們先從頭回顧下Object Detection任務中各個網路的發展,首先R-CNN用分類+bounding box解決了目標檢測問題,SP
深度學習目標檢測常用工具型程式碼:對檢測出來的結果單獨進行softnms操作
# -*- coding: utf-8 -*- """ Created on Mon Apr 9 21:09:09 2018 對每一類生成的prebbox.txt進行softnms操作 1.讀入文字,讀入bbox @author: ygx """ import os imp
深度學習目標檢測:RCNN,Fast,Faster,YOLO,SSD比較
需要說明一個核心: 目前雖然已經有更多的RCNN,但是Faster RCNN當中的RPN仍然是一個經典的設計。下面來說一下RPN:在Faster RCNN當中,一張大小為224*224的圖片經過前面的5個卷積層,輸出256張大小為13*13的 特徵圖(你也可以理解為一張13*13*256大小的特徵圖,256表
基於深度學習的NLP研究大盤點
AI深入淺出公眾號ID:xiumius關注在過去的幾年裡,深度學習(DL)架構和演算法在諸如影象
論文學習-深度學習目標檢測2014至201901綜述-Deep Learning for Generic Object Detection A Survey
visual 視覺 尺度 iss https 展開 http stones 使用 目錄 寫在前面 目標檢測任務與挑戰 目標檢測方法匯總 基礎子問題 基於DC
深度學習目標檢測 caffe下 yolo-v1 yolo-v2 vgg16-ssd squeezenet-ssd mobilenet-v1-ssd mobilenet-v12-ssd
1、caffe下yolo系列的實現1.1 caffe-yolo-v1我的github程式碼 點選開啟連結yolo-v1 darknet主頁 點選開啟連結上面的caffe版本較老。對新版的cudnn支援不好,可能編譯出錯,需要修改 cudnn.hpp標頭檔案在次進行編譯,修改後
基於深度學習的目標檢測及場景文字檢測研究進展
根據本人組會PPT總結整理,複習備用。一.目標檢測與場景文字檢測定義目標檢測:給定一張圖片或者視訊幀,找出其中所有目標的位置,並給出每個目標的具體類別。場景文字檢測:文字檢測(Text Detection):對照片中存在文字的區域進行定位,即找到單詞或者文字行(word/li
基於深度學習的目標檢測演算法綜述(一)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40047760 目標檢測(Object Detection)是計算機視覺領域的基本任務之一,學術界已有將近二十年的研究歷史。近些年隨著深度學習技術的火熱發展,目標檢測演算法也從基於手工特徵的傳統演算法轉向了基於深度神經網路的檢測技
基於深度學習的目標檢測演算法綜述(三)(截止20180821)
參考:https://zhuanlan.zhihu.com/p/40102001 基於深度學習的目標檢測演算法綜述分為三部分: 1. Two/One stage演算法改進。這部分將主要總結在two/one stage經典網路上改進的系列論文,包括Faster R-CNN、YOLO、SSD等經