
特徵選擇(feature selection)
特徵選擇 feature selection
終於有時間把好久之前就想寫的關於特徵選擇的基本介紹補上來了,主要想從以下幾個方面介紹:
- 特徵選擇的動機–為什麼要特徵選擇
- 常見的特徵選擇方法–如何特徵選擇
- 特徵選擇的效果
一. 動機
提到特徵選擇的動機首先要說下維災難(the curse of dimensionality),用個圖(圖片來自wiki)來形象的說明維災難:
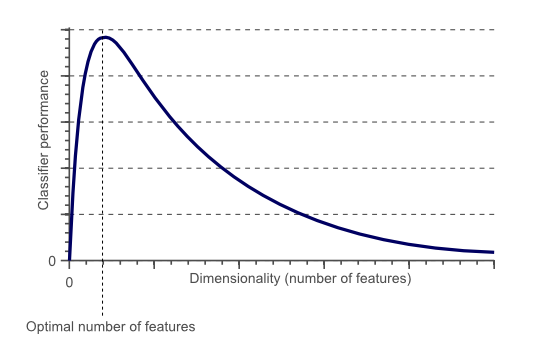
所謂的維災難就是當特徵維度超過一定界限後,分類器的效能隨著特徵維度的增加反而下降(而且維度越高訓練模型的時間開銷也會越大)。導致分類器下降的原因往往是因為這些高緯度特徵中含有無關特徵和冗餘特徵,因此特徵選擇的主要目的是去除特徵中的無關特徵和冗餘特徵:

無關特徵:是指與當前學習任務無關的特徵(該特徵所提供的資訊對於當前學習任務無用),如對於學生成績而言,學號則是無關特徵。
冗餘特徵:是指該特徵所包含的資訊能從其他特徵推演出來,如對於“面積”這個特徵而言,從能從“長”和“寬”得出,則它是冗餘特徵。
二. 常見的特徵選擇方法
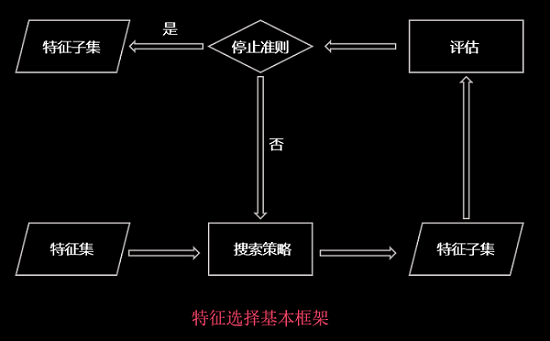
1.特徵選擇的基本框架
2.搜尋策略
常見的搜尋策略主要有三種:
- 完全搜尋
也就是列舉特徵集中的所有特徵組合從而選出最優的特徵子集,複雜度為O(2n) ,因此實際應用中幾乎不用。 - 啟發式搜尋
啟發式搜尋策略主要有序列前向選擇(SFS,Sequential Forward Selection)和序列後向選擇(SFS,Sequential Forward Selection)等。假定原始特徵集是f ,挑選出來的特徵子集是fsub 。序列前向搜尋策略首先把特徵子集fsub 初始化為空集,每一步從f−fsub (餘下的特徵集)中選擇使得評價函式J(fsub+x) 最優的特徵x 直至評價函式J 無法改進,該演算法便認為得到了最優的屬性子集。與序列前向搜尋策略相反的是,序列後向搜尋策略搜尋特徵子集fsub 從全集開始,每次刪除一個屬性x ,重複該過程,直到評價函式J(fsub−x) 最優。序列前向搜尋策略和序列後向搜尋策略的思想都為貪心思想,因此有時候容易陷入到區域性最優中。 - 隨機搜尋
隨機搜尋策略,即在計算過程中把特徵選擇問題和禁忌搜尋演算法、模擬退火演算法和遺傳演算法等,或隨機重取樣過程結合起來以概率推理和隨機取樣作為演算法基礎,基於對分類有效性的評估,在計算過程中對每個特徵賦予一定的權重,然後根據自適應的閾值或者使用者自定義的閾值來對特徵重要性進行評估,選擇大於閾值的特徵。Relief系列演算法是典型的代表。
3.特徵選擇演算法的分類
常見的特徵選擇方法可以大致分為三類:過濾法(filter)、包裹式(wrapper)、嵌入式(embedding)。
- 過濾式(filter)
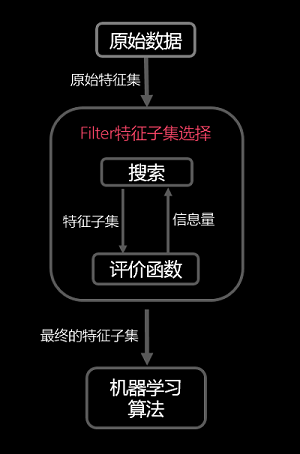
過濾式的基本原理如下圖所示:
其先對資料集進行特徵選擇,使用選擇出來的特徵子集訓練學習器,特徵選擇選擇過程與後續的學習器無關。 - 包裹式(wrapper)
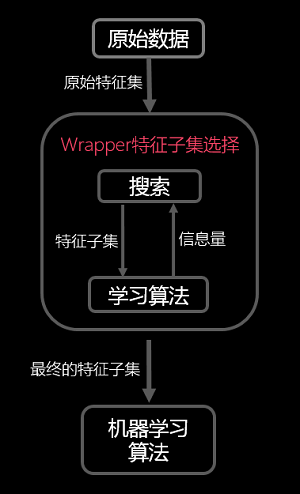
過濾式的基本原理如下圖所示:
包裝法特徵選擇方法直接把最終將要使用的學習器的效能作為特徵子集的評價準則,這是與過濾法特徵選擇方法最大的區別。
Dash等人在總結Ben-Bassat等人、Doak等人的工作後將評價準則分為五類:距離度量(Distance Measure)、資訊增益度量(Information Gain Measure)、依賴性度量(Dependence Measure)、一致性度量(Consistency Measure)和分類器錯誤率度量(Classifier Error Rate Measure)。
(1)距離度量:距離度量一般認為是差異性或者分離性的度量,常用的距離度量方法有歐式距離等。對於一個二元分類問題,對於兩個特徵
(2)資訊增益度量:特徵f的資訊增益定義為使用特徵f的先驗不確定性與期望的後驗不確性之間的差異。若特徵
(3)依賴性度量:依賴性度量又稱為相關性度量(Correlation Measure)、通常可採用皮爾遜相關係數(Pearson correlation coefficient)來計算特徵f與類別C之間的相關度,若特徵
(4)一致性度量:假定兩個樣本,若它們的特徵值相同,且所屬類別也相同,則認為它們是一致的:否則,則稱它們不一致。一致性常用不一致率來衡量,其嘗試找出與原始特徵集具有一樣辨別能力的最小的屬性子集。
(5)分類器錯誤率度量:該度量使用學習器的效能作為最終的評價閾值。它傾向於選擇那些在分類器上表現較好的子集。
以上5種度量方法中,距離度量(Distance Measure)、資訊增益度量(Information Gain Measure)、依賴性度量(Dependence Measure)、一致性度量(Consistency Measure)常用於過濾式(filter);分類器錯誤率度量(Classifier Error Rate Measure)則用於包裹式(wrapper)。

因為包裝式特徵選擇直接將最終將要使用的學習器的效能作為評價函式,因此從模型效能的角度出發,能夠發現包裝式特徵選擇的效能要優於過濾式特徵選擇,但是包裝式特徵選擇的時間開銷較大。而過濾式特徵選擇由於和特定的學習器無關,所以計算開銷小,泛化能力強於包裝式特徵選擇。因此,在實際應用中由於資料集很大,特徵維度高,過濾式特徵選擇應用的更廣泛些。
- 嵌入式(embedding)
嵌入式特徵選擇方法是將特徵選擇過程與學習器訓練過程融為一體,兩者在同一個優化過程中完成,即在學習器訓練過程中自動完成了特徵選擇。具體的內容可以參見周志華大牛的《機器學習》(西瓜書)。
三. 特徵選擇的效果
通過在平時的應用中能夠發現特徵選擇能夠明顯的改善學習器的精度,減少模型訓練時間,有效的避免維災難問題。
參考文獻:
[1]Dash M, Liu H. Feature Selection for Classification[J]. Intelligent Data Analysis, 1997,1(1-4):131–156.
[2]周志華.機器學習[M].北京:清華大學出版社,2016:252-253.
未經博主同意,不得盜用博文插圖,轉載請註明出處
相關推薦
特徵選擇(feature selection)
特徵選擇 feature selection 終於有時間把好久之前就想寫的關於特徵選擇的基本介紹補上來了,主要想從以下幾個方面介紹: - 特徵選擇的動機–為什麼要特徵選擇 - 常見的特徵選擇方法–如何特徵選擇 - 特徵選擇的效果
paper_reading:Online Feature Selection線上特徵選擇
Online Feature Selection: A Limited-Memory Substitution Algorithm and Its Asynchronous Parallel Variation 線上特徵選擇:有限儲存器替換演算法及其非同步並行變化 ABSTRACT摘要
scikit-learn--Feature selection(特徵選擇)
去掉方差較小的特徵 方差閾值(VarianceThreshold)是特徵選擇的一個簡單方法,去掉那些方差沒有達到閾值的特徵。預設情況下,刪除零方差的特徵,例如那些只有一個值的樣本。 假設我們有一個有布林特徵的資料集,然後我們想去掉那些超過80%的樣本都是0(或者1)的特徵。
總結 特徵選擇(feature selection)演算法筆記
什麼是特徵選擇 特徵選擇也稱特徵子集選擇,或者屬性選擇,是指從全部特診中選取一個特徵子集,使構造出來的模型更好。為什麼要做特徵選擇在機器學習的實際應用中,特徵數量往往較多,其中可能存在不相關的特徵,特徵之間也可能存在相互依賴,容易導致: 特徵個數越多,分析特徵、訓練模型所需
sklearn-學習:Dimensionality reduction(降維)-(feature selection)特徵選擇
本文主要對對應文件的內容進行簡化(以程式碼示例為主)及漢化 對應文件位置:http://scikit-learn.org/stable/modules/feature_selection.html#feature-selection feature selection
sklearn feature selection特徵選擇
一、特徵選擇器1. sklearn.feature_selection.SelectKBest(score_func, k) Select features according to the k highest scores. 其中引數score_func是評分函式,預
機器學習-特徵工程-Feature generation 和 Feature selection
概述:上節咱們說了特徵工程是機器學習的一個核心內容。然後咱們已經學習了特徵工程中的基礎內容,分別是missing value handling和categorical data encoding的一些方法技巧。但是光會前面的一些內容,還不足以應付實際的工作中的很多情況,例如如果咱們的原始資料的feature
【排序算法】選擇排序(Selection sort)
排序算法 void tput rgs 有關 span -s 最小數 小數 0. 說明 選擇排序(Selection sort)是一種簡單直觀的排序算法。 它的工作原理如下。 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然後,再從剩余未排
CSS3選擇器selection--改變選中文字的顏色
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title></title> <style> p::selection{ b
Spark_Mllib系列之二———提取,轉化和特徵選擇
Extracting, transforming and selecting features 這部分將會講到特徵的演算法,粗略的分為一下幾個部分: 特徵的提取 TF-IDF 詞條頻率-逆向檔案頻率是一種被廣泛使用在文字提取的向量化特徵的方法,反映了一個詞條對一篇語料庫
【Mark Schmidt課件】機器學習與資料探勘——特徵選擇
本課件的主要內容如下: 上次課程回顧:尋找“真實”模型 資訊準則 貝葉斯資訊準則 關於食物過敏 特徵選擇 全基因組關聯分析 “迴歸權重”方法 搜尋評分法 評分函式的選擇 “特徵數量”懲罰
RandomForest的out of bag estimate 及Feature selection 具體作法
一、Out of bag estimate(OOB) 1、OOB sample number RF是bagging的一種發方法,在做有放回的bootstrap時,由抽樣隨機性可得到(其中1/e可由高數中的洛必達法則得到): RF中每次抽樣N個樣本訓練每一棵decision tree(gt),對於此棵
[轉載]Scikit-learn介紹幾種常用的特徵選擇方法
#### [轉載]原文地址:http://dataunion.org/14072.html 特徵選擇(排序)對於資料科學家、機器學習從業者來說非常重要。好的特徵選擇能夠提升模型的效能,更能幫助我們理解資料的特點、底層結構,這對進一步改善模型、演算法都有著重要作用。 特徵選擇主要有兩個功能: 減少特
機器學習特徵選擇方法
有一句話這麼說,特徵決定上限,模型逼近上限。特徵選擇對後面的模型訓練很重要,選擇合適重要的特徵,對問題求解尤為重要,下面介紹一些常見的特徵選擇方法。 通常來說,從兩個方面考慮來選擇特徵: 特徵是否發散:如果一個特徵不發散,例如方差接近於0,也就是說樣本在這個特徵上基本上沒有差異,這個
特徵選擇(2):mRMR特徵選擇演算法(matlab程式碼實現)
mRMR是什麼 是基於最大相關最小冗餘的特徵選擇方法。 要點:1.相關是特徵列與類標的相關性,也可以值特徵之間的相關性,通常來說,特徵與類標相關性越高,說明這個特徵越重要。則選擇這個特徵,這就是最大相關。 2.最小冗餘:特徵選擇的目的就是減少分類器的負擔,減少不需要的特徵。而兩個特徵之間
特徵選擇(1):特徵相關性度量之互資訊量(matlab程式碼實現)
互資訊的概念 互資訊量定義基於資訊熵的概念。在資訊理論中,資訊熵可度量變數的不確定性。設在隨機空間中,某一離散變數X 的概率分佈為p(x),則X 的資訊熵定義為:
機器學習筆記——特徵選擇
常見的特徵選擇方法大致可分為三類: 過濾式:過濾式方法先對資料集進行特徵選擇,然後再訓練學習器,特徵選擇過程與後續學習器無關。這相當於先用特徵選擇過程對初始特徵進行“過濾”,再用過濾後的特徵來訓練模型。 包裹式:包裹式特徵選擇直接把最終將要使用的學習器的效能作為特徵子集的評價標準。換言之,包
【排序演算法】選擇排序(Selection sort)
0. 說明 選擇排序(Selection sort)是一種簡單直觀的排序演算法。 它的工作原理如下。 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然後,再從剩餘未排序元素中繼續尋找最小(大)元素,然後放到已排序序列的末尾。以此類推,直到所有元素均排序完
基於Kubernetes的機器學習微服務系統設計系列——(六)特徵選擇微服務
內容提要 特徵選擇類圖 部分實現程式碼 請求JSON 響應JSON 特徵選擇微服務主要實現如下特徵選擇演算法:Document Frequency(DF)、Information Gain(IG)、(χ2)Chi-Square
特徵選擇——Matrix Projection演算法研究與實現
內容提要 引言 MP特徵選擇思想 MP特徵選擇演算法 MP特徵選擇分析 實驗結果 分析總結 引言 一般選擇文字的片語作為分類器輸入向量的特徵語義單元,而作為單詞或詞語的片語,在任何一種語言中都有數萬或數十萬個。另外