
When To Multiply Inside Your Neural Network?
When To Multiply Inside Your Neural Network?
Typical neural networks consist of linear combinations of input features and Relu units built upon them, and nothing else. So is there a need to introduce explicit multiplications, either on inputs or inside the network?
But first, let’s consider why you should not multiply inside your neural network. Suppose you have a bunch of features and want to construct arbitrary multiplicative terms. The straightforward thing would be to feed them into the network after applying log()
Secondly, neural networks can approximate arbitrary functions. And of course, it can approximate a multiplier as well. To see this, we train a single hidden layer neural network to learn multiplication. If you have Tensorflow installed, you can copy-paste the code below and run it.
''' Plot the root mean squared error of a single
hidden layer neural network while modeling x^2.
'''
import tensorflow as tf
import numpy as np
NUM_TRAIN_SAMPLES = 1000000
NUM_TEST_SAMPLES = 100000
feature_columns = [
tf.feature_column.numeric_column(key='a'),
tf.feature_column.numeric_column(key='b')]
a_train = np.random.rand(NUM_TRAIN_SAMPLES)
b_train = np.random.rand(NUM_TRAIN_SAMPLES)
train = tf.estimator.inputs.numpy_input_fn(
x={'a': a_train, 'b': b_train},
y=a_train * b_train, # model a * b
batch_size=128,
shuffle=True)
a_test = np.random.rand(NUM_TRAIN_SAMPLES)
b_test = np.random.rand(NUM_TRAIN_SAMPLES)
test = tf.estimator.inputs.numpy_input_fn(
x={'a': a_test, 'b': b_test},
y=a_test * b_test,
shuffle=False)
range_test = np.arange(0.00, 10.0, 0.01)
ranget = tf.estimator.inputs.numpy_input_fn(
x={'a': range_test, 'b': range_test},
y=range_test * range_test,
shuffle=False)
def estimate_error(num_hidden_units):
model = tf.estimator.DNNRegressor(
hidden_units=[num_hidden_units],
feature_columns=feature_columns)
model.train(input_fn=train, steps=100000)
eval_result = model.evaluate(input_fn=test)
mse = eval_result["average_loss"]**0.5
print('rmse=%f'%mse)
predictions = list(model.predict(input_fn=ranget))
for ip, p in zip(range_test, predictions):
v = p["predictions"][0]
print('x=%f, x^2=%f, model=%f'%(ip, ip*ip, v))
if __name__ == "__main__":
estimate_error(80)
With 80 Relus, we get to a root mean squared error near 0.003, which seems like a reasonable approximation of a multiplier. The code above also feeds numbers in the (0, 1) range to both inputs of the multiplier, essentially evaluating x², and then compares it with the actual value of x². The plot below shows the comparison. Unsurprisingly, the model seems quite good at emulating multiplication.

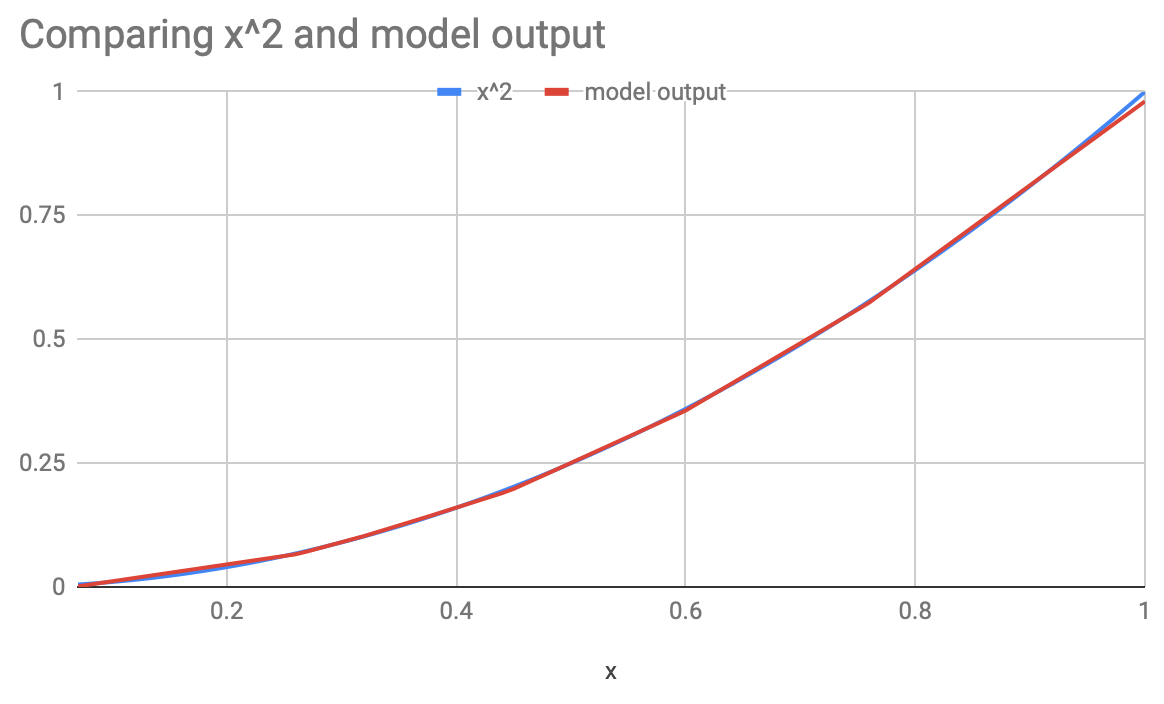
So the case for multiplication inside the network seems dead? Not quite. Note that the model has just learnt to approximate the output for the examples in the training data, it understands nothing about multiplication. In other words, what the model has learnt doesn’t generalize to true multiplication. To understand the significance of this, we extend the plot above, to values beyond the (0, 1) range that the training data is restricted to. Now the plot looks like:

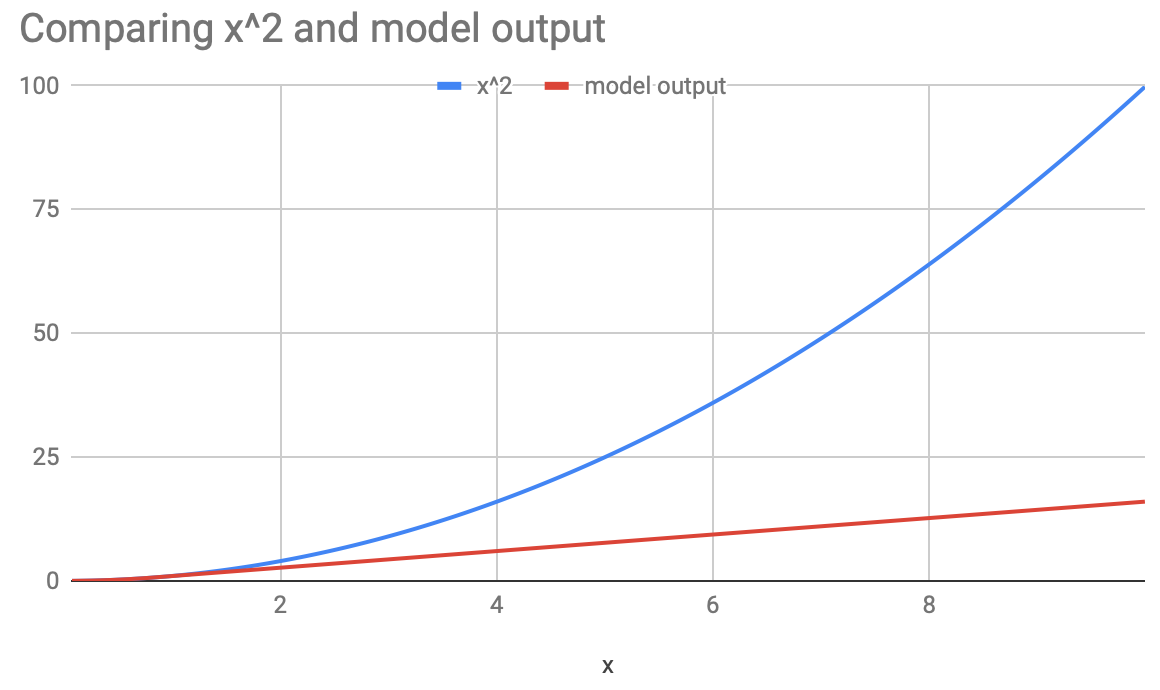
The neural network can masquerade as a multiplier, but that breaks down quite dramatically as you go beyond the values seen during training. This may be important if your training data doesn’t represent the entirety of the universe in which the model operates. For example, if your model is used in search ranking, your training data may be limited to results from the first page, whereas in reality the model is used to score documents that are 100x in volume, beyond what is logged as training data.
So if you have a strong intuition that multiplication is the right way to model certain relations, then it may be better to explicitly enforce that in the network. The effect of it may not be immediately apparent from the logged data that is split as train and test. An online test may be the best way to confirm your intuition. Best of luck!
See also:
相關推薦
When To Multiply Inside Your Neural Network?
When To Multiply Inside Your Neural Network?Typical neural networks consist of linear combinations of input features and Relu units built upon them, and no
How to Create a Simple Neural Network in Python
Neural networks (NN), also called artificial neural networks (ANN) are a subset of learning algorithms within the machine learning field that are loosely b
How to build your own Neural Network from scratch in Python
How to build your own Neural Network from scratch in PythonA beginner’s guide to understanding the inner workings of Deep LearningMotivation: As part of my
How to Visualize Your Recurrent Neural Network with Attention in Keras
Now for the interesting part: the decoder. For any given character at position t in the sequence, our decoder accepts the encoded sequence h=(h1,...,hT) as
Building your Deep Neural Network: Step by Step¶
pan auto plot chan arr src computing zeros rect Welcome to your week 4 assignment (part 1 of 2)! You have previously trained a 2-layer N
A Bayesian Approach to Deep Neural Network Adaptation with Applications to Robust Automatic Speech Recognition
機器學習 屬於 瓶頸 特征 oid ack enter 變換 表示 基於貝葉斯的深度神經網絡自適應及其在魯棒自動語音識別中的應用 直接貝葉斯DNN自適應 使用高斯先驗對DNN進行MAP自適應 為何貝葉斯在模型自適應中很有用? 因為自適應問題可以視為後驗估計
Make your own neural network(Python神經網路程式設計)一
這本書應該算我第一本深度學習的程式碼入門書了吧,之前看阿里云云棲社和景略集智都有推薦這本書就去看了, 成功建立了自己的第一個神經網路,也瞭解一些關於深度學習的內容,再加上這學期的概率論與數理統計的課, 現在再來看李大大的機器學習課程,終於能看懂LogisticsRegression概率那部分公
Make your own neural network(Python神經網路程式設計)三
前兩篇程式碼寫了初始化與查詢,知道了S函式,初始權重矩陣。以及神經網路的計算原理,總這一篇起就是最重要的神經網路的訓練了。 神經網路的訓練簡單點來講就是讓輸出的東西更加接近我們的預期。比如我們輸出的想要是1,但是輸出了-0.5,明顯不是 我們想要的。 誤差=(期望的數值)-(實際輸出),那麼我們的誤差就是
《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its...》論文閱讀之CRNN
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition paper: CRNN 翻譯:CRNN
深度學習論文翻譯解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
論文標題:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition 論文作者: Baoguang Shi, Xiang B
How to train Neural Network faster with optimizers?
from:https://towardsdatascience.com/how-to-train-neural-network-faster-with-optimizers-d297730b3713 AsI worked on the last article, I had the o
DL4J: How to create a neural network that draws images
Neural networks, machine learning, artificial intelligence – I get the impression that these slogans attack us from everywhere. They are mainly associated
The 4 Convolutional Neural Network Models That Can Classify Your Fashion Images
Fashion MNIST DatasetRecently, Zalando research published a new dataset, which is very similar to the well known MNIST database of handwritten digits. The
Ask HN: How do you know when to switch teams within your company?
I'm wondering how folks here suss out when the right time to switch teams/projects might be. How do you identify when you've learned all you can from a eng
How to train your Neural Networks in parallel with Keras and Apache Spark
Apache Spark on IBM Watson StudioNow, we will finally train our Keras model using the experimental Keras2DML API. To be able to execute the following code,
Why, How and When to Scale your Features
Why, How and When to Scale your FeaturesFeature scaling can vary your results a lot while using certain algorithms and have a minimal or no effect in other
神經網路與深度學習第四周-Building your Deep Neural Network
Building your Deep Neural Network: Step by StepWelcome to your week 4 assignment (part 1 of 2)! You have previously trained a 2-layer Neur
論文筆記:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application
1.歷史方法 1)基於字元的DCNN,比如photoOCR.單個字元的檢測與識別。要求單個字元的檢測器效能很強,crop的足夠好。 2)直接對圖片進行分類。9萬個單詞,組合成無數的單詞,無法直接應用 3)RNN,訓練和測試均不需要每個字元的位置。但是需要預處理,從圖片得到特
Make Your Own Neural Network(七)-----矩陣很有用
Make Your Own Neural Network構建你自己的神經網路作者:lz0499宣告:1)Make Your Own Neural Network翻譯自編寫的神經網路入門書籍。作者的目的是儘可能的少用術語和高深的數學知識,以圖文並茂的方式講解神經網路是如何工作的
論文翻譯------Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches
原文介紹了一種基於深度學習的密集匹配方法MC-NET,是第一篇將深度學習引入密集匹配方面的文章。 **********************************************************手動分割線**********************