
中文資訊處理 N-gram模型
阿新 • • 發佈:2019-01-12
一. 什麼是建模?模型又是什麼?
建模,是人們為了理解事物而對事物做出的一種抽象,是對事務進行書面無歧義的描述。
模型就是對實際問題或者是客觀規律進行的形式化的表達。
二. 關於語言模型
長久以來,人們一直希望計算機可以理解我們人類的語言,從而進行一系列其他的應用,比如機器翻譯,語音識別,分詞,輸入法,搜 索引擎的自動補全等。以前人們是進行基於規則的語言模型的研究方向,遇到了很大的問題,後來便出現了基於統計的語言模型,這些 在《數學之美》中吳軍老師有進行詳細的介紹。那麼,當下人們使用最多,應用最廣的便是n元語言模型。其實這個模型本質上就是在 判斷一個句子是句子的概率.
三. N-gram model
1. 定義
假設一個句子是由,來表示的,其中表示的句子中的單詞,那麼,一個語言模型就可以用如下來表示:
那麼我們將如何來計算呢?
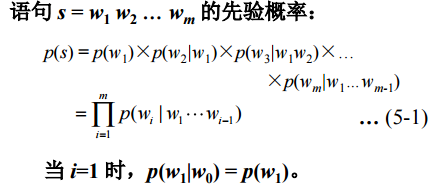
從公式可以看出,我們要計算這樣一個表示式的,是非常困難的,於是,這個時候馬爾可夫鏈便發揮了重大作用。
2.什麼是馬爾可夫鏈?
馬爾科夫鏈描述的是一個隨機狀態,他指出某個狀態只與其前(後)一個或者兩個狀態有關係,再往前的狀態對當前狀態的影響可以忽略不 算,這個整體還是比較符合人民的認知的。按照這個理論的話,上面的計算便可以簡化,因為:
以上就是一個簡單的三階馬爾可夫鏈,也就是三元語言模型,屬於二階馬爾科夫假設。


3.n-gram 模型應用舉例
- 拼音轉漢字
P(PinYin) = ta shi yan jiu sheng wu de
那麼對應的可能的漢語是:
那麼究竟應該要翻譯為哪一個句子才是對的,假設我們次用2元語言模型,其實就是在求每一個句子出現的概率。
;