
維特比演算法—打字輸入預測
這裡首先說下隱馬爾可夫模型的相關知識。
1. 隱馬爾可夫模型(HMM)
在說隱馬爾可夫模型前還有一個概念叫做“馬爾科夫鏈”,既是在給定當前知識或資訊的情況下,觀察物件過去的歷史狀態對於預測將來是無關的。也可以說在觀察一個系統變化的時候,他的下一個狀態如何的概率只需要觀察和統計當前的狀態即可正確得出。隱馬爾可夫鏈和貝葉斯網路的模型思維有些接近,區別在於隱馬爾可夫的模型更為簡化。而且隱馬爾可夫鏈是一個雙重的隨機過程,不僅狀態轉移之間是一個隨機事件,狀態和輸出之間也是一個隨機過程。
如下圖:
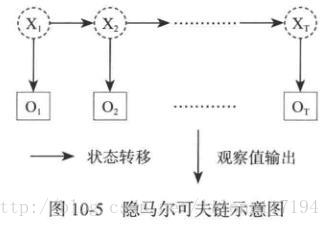
在一個完整的觀察過程中有一些狀態的轉換,如
對於HMM來說,如果前提知道所有的隱含狀態之間的轉換概率和所有隱含狀態到所有可見狀態之間的輸出概率,進行模擬是很容易的。但是往往會缺失一部分資訊,如何應用演算法去估計缺失的資訊,就成為了一個重要的問題。
和HMM模型相關的演算法分為3類,分別解決3種問題。
- 知道隱含狀態數量、轉換概率、根據可見狀態鏈的結果想知道隱含狀態鏈。這個問題在語音識別領域叫做解碼問題,求解這個問題有兩種方法。第一種是求最大最大似然狀態路徑(一串骰子序列,使其產生的觀測結果的概率最大)。第二種解法是求每次擲出的骰子分別是某種骰子的概率。
- 知道隱含狀態數量、轉換概率、根據可見狀態鏈的結果想知道產生結果的概率。這個問題的實際意義在於檢測觀察到的模型是否和已知的模型吻合。如果很多次結果都是對應了比較小的概率,那麼就說明已知的模型很可能是錯的。
- 知道隱含狀態數量、不知道轉換概率、根據可見狀態鏈的結果想反推出轉換概率。這個問題是最重要的,因為是最為常見的。很多時候只有可見結果,不知道HMM模型中的引數,需要從可見結果估計這些引數。
2. 維特比演算法
當馬爾科夫鏈很長時,根據古典概型的分佈特點來計算概率時窮舉的數量太大,就很難得到結果。這時就要用到維特比演算法。維特比演算法就是為了找出可能性最大的隱藏序列,即剛剛提到的第一個問題。這種演算法是一種鏈的可能性問題,現在應用最廣泛的是CDMA和打字提示功能。
維特比演算法的整體思路是尋找上一段資訊和它跟隨的下一段資訊的轉換概率問題。
2.1 打字輸入提示應用

這是常用的搜狗輸入法的示例。在本例中只是考慮最簡單的因素,下面是模擬輸入法的猜測方法給出一個演算法示例,先給出各級轉換矩陣。如下:
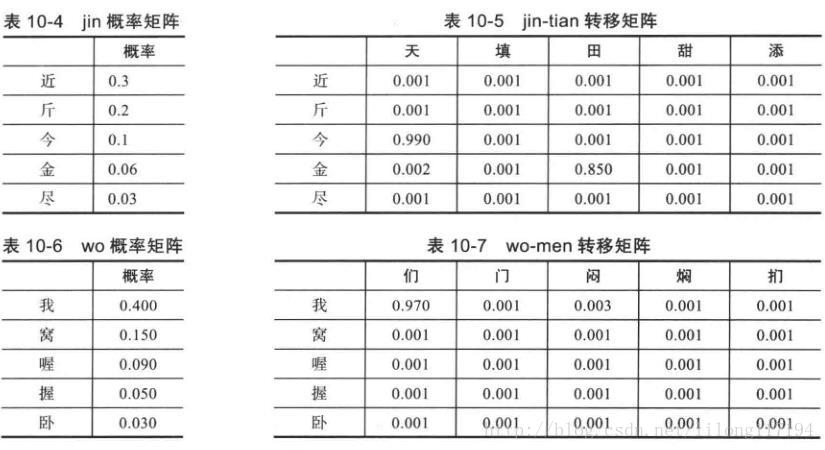
其實這些概率矩陣都是由統計產生,而且每個雙字詞、三字詞等的輸入矩陣都由這種統計產生。在輸入雙字詞漢子拼音時會根據轉移概率表進行計算。多個詞相連就是多個轉移矩陣的概率相乘計算,從而得到概率最大的輸入可能項。
2.2 程式碼:
# coding=utf-8
import numpy as np
jin = ['近', '斤', '今', '金', '盡']
jin_per = [0.3, 0.2, 0.1, 0.06, 0.03] # 單字詞概率矩陣
jintian = ['天', '填', '田', '甜', '添']
jintian_per = [
[0.001, 0.001, 0.001, 0.001, 0.001], # 轉移矩陣
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.990, 0.001, 0.001, 0.001, 0.001],
[0.002, 0.001, 0.850, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001]]
wo = ['我', '窩', '喔', '握', '臥']
wo_per = [0.400, 0.150, 0.090, 0.050, 0.030]
women = ['們', '門', '悶', '燜', '捫']
women_per = [
[0.970, 0.001, 0.003, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001]]
qing = ['請', '晴', '清', '輕', '情']
qing_per = [0.2, 0.12, 0.09, 0.05, 0.02]
qinghua = ['話', '畫', '化', '花', '華']
qinghua_per = [
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.950],
[0.001, 0.001, 0.850, 0.001, 0.001],
[0.003, 0.001, 0.001, 0.002, 0.001]]
da = ['大', '打', '達', '搭', '噠']
da_per = [0.300, 0.130, 0.120, 0.110, 0.090]
daxue = ['學', '雪', '血', '薛', '穴']
daxue_per = [
[0.800, 0.140, 0.023, 0.004, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001]]
N = 5
# 一個字的預測
def found_from_oneword(oneword_per):
index = []
values = []
a = np.array(oneword_per)
print 'a:',a
print 'argsort(a):',np.argsort(a)[::-1][:N]
for v in np.argsort(a)[::-1][:N]: # 遍歷降序前5的概率索引,
index.append(v)
values.append(oneword_per[v])
return index, values
# 一個詞的預測
def found_from_twoword(oneword_per, twoword_per):
last = 0
for i in range(len(oneword_per)):
#print oneword_per[i],'\n', twoword_per[i]
current = np.multiply(oneword_per[i], twoword_per[i]) # 字概率乘以轉移概率
if i == 0:
last = current
else:
last = np.concatenate((last, current), axis=0) # 字串拼接
#print 'last:',last # 單個字概率矩陣乘以轉移概率矩陣
index = []
values = []
#print np.argsort(last)[::-1][:N]
for v in np.argsort(last)[::-1][:N]: # 概率從大到低的排列(前5個)
index.append([v / 5, v % 5]) # 由陣列的索引值得到其在矩陣中的座標值
values.append(last[v])
print 'index:',index,'\n','values:',values
return index, values
# 字詞的預測
def predict(word):
if word == 'jin':
for i in found_from_oneword(jin_per)[0]: # 遍歷概率索引值
print jin[i] # 輸出排序後的索引對應的值
print '.......................................'
elif word == 'jintian':
for i in found_from_twoword(jin_per, jintian_per)[0]: # 傳入的是概率矩陣和轉移矩陣
print 'i:',i
# jin[i[0]]:片語在矩陣中的第一個字的下標;jintian[i[1]]:在矩陣中的列表示後一個字的下標
print jin[i[0]] + jintian[i[1]]
print '.......................................'
elif word == 'wo':
for i in found_from_oneword(wo_per)[0]:
print wo[i]
print '.......................................'
elif word == 'women':
for i in found_from_twoword(wo_per, women_per)[0]:
print wo[i[0]] + women[i[1]]
print '.......................................'
elif word == 'jintianwo':
index1, values1 = found_from_oneword(wo_per)
print 'index1, values1:', index1, '\n',values1 # 先得到'wo'的排序
index2, values2 = found_from_twoword(jin_per, jintian_per) # 再得到'jintian'排序
print 'index2, values2:', index2, '\n',values2
last = np.multiply(values1, values1) # 得到'jintian'和'wo'的最大概率乘積
for i in np.argsort(last)[::-1][:N]:
print jin[index2[i][0]], jintian[index2[i][1]], wo[i]
print '.......................................'
elif word == 'jintianwomen':
index1, values1 = found_from_twoword(jin_per, jintian_per) # 得到'jintian'的排序
index2, values2 = found_from_twoword(wo_per, women_per) # 得到'women'的排序
last = np.multiply(values1, values1) # 得到'jintian'和'women'相乘的排序
for i in np.argsort(last)[::-1][:N]:
print jin[index1[i][0]], jintian[index1[i][1]], wo[index2[i][0]], women[index2[i][1]]
print '.......................................'
else:
pass
if __name__ == '__main__':
predict('jin')
# 近
# 斤
# 今
# 金
# 盡
predict('jintian')
# 今天
# 金田
# 近天
# 近填
# 近田
predict('wo')
# 近
# 斤
# 今
# 金
# 盡
predict('women')
# 我們
# 我悶
# 我門
# 我燜
# 我捫
predict('jintianwo')
# 今 天 我
# 金 田 窩
# 近 天 喔
# 近 填 握
# 近 田 臥
predict('jintianwomen')
# 今 天 我 們
# 金 田 我 悶
# 近 田 我 捫
# 近 填 我 燜
# 近 天 我 門執行結果:
a: [ 0.3 0.2 0.1 0.06 0.03]
argsort(a): [0 1 2 3 4]
近
斤
今
金
盡
.......................................
index: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
values: [0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
i: [2, 0]
今天
i: [3, 2]
金田
i: [0, 0]
近天
i: [0, 1]
近填
i: [0, 2]
近田
.......................................
a: [ 0.4 0.15 0.09 0.05 0.03]
argsort(a): [0 1 2 3 4]
我
窩
喔
握
臥
.......................................
index: [[0, 0], [0, 2], [0, 1], [0, 3], [0, 4]]
values: [0.38800000000000001, 0.0012000000000000001, 0.00040000000000000002, 0.00040000000000000002, 0.00040000000000000002]
我們
我悶
我門
我燜
我捫
.......................................
a: [ 0.4 0.15 0.09 0.05 0.03]
argsort(a): [0 1 2 3 4]
index1, values1: [0, 1, 2, 3, 4]
[0.4, 0.15, 0.09, 0.05, 0.03]
index: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
values: [0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
index2, values2: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
[0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
今 天 我
金 田 窩
近 天 喔
近 填 握
近 田 臥
.......................................
index: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
values: [0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
index: [[0, 0], [0, 2], [0, 1], [0, 3], [0, 4]]
values: [0.38800000000000001, 0.0012000000000000001, 0.00040000000000000002, 0.00040000000000000002, 0.00040000000000000002]
今 天 我 們
金 田 我 悶
近 田 我 捫
近 填 我 燜
近 天 我 門
.......................................從執行結果可以看出其實就是通過統計得到的概率矩陣和轉移矩陣的乘積之後的排序計算。
3. 筆記
3.1 for v in np.argsort(a)[::-1][:N]的用法:
In [7]: a=array([1, 2, 3])
In [8]: a
Out[8]: array([1, 2, 3])
In [9]: a[::-1]
Out[9]: array([3, 2, 1])
In [10]: a[::-1][:3]
Out[10]: array([3, 2, 1])3.2 last = np.concatenate((last, current), axis=0)的使用:
>>> import numpy as np
>>> a = np.array([[1, 2], [3, 4]])
>>> a
array([[1, 2],
[3, 4]])
>>> b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])參考:《白話大資料與機器學習》
相關推薦
維特比演算法—打字輸入預測
這裡首先說下隱馬爾可夫模型的相關知識。 1. 隱馬爾可夫模型(HMM) 在說隱馬爾可夫模型前還有一個概念叫做“馬爾科夫鏈”,既是在給定當前知識或資訊的情況下,觀察物件過去的歷史狀態對於預測將來是無關的。也可以說在觀察一個系統變化的時候,他的下一個狀態如何
隱馬爾科夫模型(前向後向演算法、鮑姆-韋爾奇演算法、維特比演算法)
概率圖模型是一類用圖來表達變數相關關係的概率模型。它以圖為表示工具,最常見的是用一個結點表示一個或一組隨機變數,結點之間的變表是變數間的概率相關關係。根據邊的性質不同,可以將概率圖模型分為兩類:一類是使用有向無環圖表示變數間的依賴關係,稱為有向圖模型或貝葉斯網;另一類是使用無向圖表示變數間的相關關係,稱為無
HMM維特比演算法
維特比演算法 利用動態規劃求解概率最大的路徑,一條路徑一個狀態序列。 動態規劃求解最優路徑專責:如果最優路徑在某時刻t 通過節點i,那麼這條路徑從節點 i 到終點的部分路徑,在節點 i 到終點的路徑中,必須是最優的。 通過這種原理就可以從t=1時刻開始,不斷向後遞推到下
hmm前後向演算法 隱馬爾科夫模型HMM(三)鮑姆-韋爾奇演算法求解HMM引數 隱馬爾科夫模型HMM(四)維特比演算法解碼隱藏狀態序列 隱馬爾科夫模型HMM(一)HMM模型
跟醫生就醫推導過程是一樣的 隱馬爾科夫模型HMM(一)HMM模型 隱馬爾科夫模型HMM(二)前向後向演算法評估觀察序列概率 隱馬爾科夫模型HMM(三)鮑姆-韋爾奇演算法求解HMM引數 隱馬爾科夫模型HMM(四)維特比演算法解碼隱藏狀態序列 在隱馬爾科夫模型HMM(一)
自然語言處理 HMM 維特比演算法(Viterbi Algorithm) 例項轉載
給大家推薦一個講解HMM比較詳細入門的內容: wiki上一個比較好的HMM例子 這是另外一個例子,結合分詞舉例的HMM: 這是詳細講解維位元演算法的系列文章,維特比演算法(Viterbi Algorithm) HMM學習最佳範例六:維特比演算法 來自52nlp
HMM學習筆記(三):動態規劃與維特比演算法
學習隱馬爾可夫模型(HMM),主要就是學習三個問題:概率計算問題,學習問題和預測問題。在前面講了概率計算問題:前後向演算法推導,Baum-Welch演算法。最後在這裡講最後的一個問題,預測問題。 預測問題:給定HMM引數
隱馬爾可夫模型(五)——隱馬爾可夫模型的解碼問題(維特比演算法)
#include <stdio.h> #include <stdlib.h> #include <string.h> int main() { float trans_p[3][3] = {{0.5,0.2,0.3},{0.3,0.5,0.2},{0
隱馬爾科夫模型(HMMs)之五:維特比演算法及前向後向演算法
維特比演算法(Viterbi Algorithm) 找到可能性最大的隱藏序列 通常我們都有一個特定的HMM,然後根據一個可觀察序列去找到最可能生成這個可觀察序列的隱藏序列。 1.窮舉搜尋 我們可以在下圖中看到每個狀態和觀察的關係。 通過計算所有可能的隱藏序列的概率,
動態規劃之隱含馬爾可夫模型(HMM)和維特比演算法(Viterbi Algorithm)
動態規劃之(HMM)和(Viterbi Algorithm) 1. 實際問題 HMM-韋小寶的骰子 • 兩種骰子,開始以2/5的概率出千。 – 正常A:以1/6的概率出現每個點 – 不正常B: 5,6出現概率為3/10,其它為1/10 • 出千的
維特比演算法——尋找最可能的隱藏狀態序列
原文標題為:維特比演算法:本質上是一個動態規劃演算法 尋找最可能的隱藏狀態序列(Finding most probable sequence of hidden states) 對於一個特殊的隱馬爾科夫模型(HMM)及一個相應的觀察序列,我們常常希望能找到
中文 NLP(3) -- 四大概率演算法模型之 隱馬爾科夫模型 HMM 和 維特比演算法 Viterbi
之前說過,基於NLP處理的演算法思想目前主要有兩大流派:統計論流派和深度學習流派。而在統計論中,常用的 4 大概率模型分別是 樸素貝葉斯模型,隱馬爾科夫模型,最大熵模型和條件隨機場模型。 對於樸素貝葉斯模型,前面已經多次打過交道,原理也相對簡單。這裡解析第二大模型 -- 隱
Viterbi(維特比)演算法在CRF(條件隨機場)中是如何起作用的?
之前我們介紹過BERT+CRF來進行命名實體識別,並對其中的BERT和CRF的概念和作用做了相關的介紹,然對於CRF中的最優的標籤序列的計算原理,我們只提到了維特比演算法,並沒有做進一步的解釋,本文將對維特比演算法做一個通俗的講解,以便大家更好的理解CRF為什麼能夠得到最優的標籤序列。 通過閱讀本文你將能
詳解隱馬爾可夫模型(HMM)中的維特比演算法
筆記轉載於GitHub專案:https://github.com/NLP-LOVE/Introduction-NLP 4. 隱馬爾可夫模型與序列標註 第3章的n元語法模型從詞語接續的流暢度出發,為全切分詞網中的二元接續打分,進而利用維特比演算法求解似然概率最大的路徑。這種詞語級別的模型無法應對 OOV(Out
HMM-維特比演算法理解與實現(python)
[HMM-前向後向演算法理解與實現(python)](https://www.cnblogs.com/gongyanzh/p/12880387.html) [HMM-維特比演算法理解與實現(python)]() --- ### 解碼問題 - 給定觀測序列 $O=O_1O_2...O_T$,模型 $\lamb
Java實現:拋開jieba等工具,寫HMM+維特比演算法進行詞性標註
一、前言:詞性標註 二、經典維特比演算法(Viterbi) 三、演算法實現 四、完整程式碼 五、效果演示: 六、總結 一、前言:詞性標註 詞性標註(Part-Of-Speech tagging, POS tagging),是語料庫語言學中將語料庫中單詞的詞性按其含義和上下文內容進行標記的文字資料處理技術
隱馬爾科夫模型(HMM)與維特比(Viterbi)演算法通俗理解
隱馬爾科夫模型:https://blog.csdn.net/stdcoutzyx/article/details/8522078 維特比演算法:https://blog.csdn.net/athemeroy/article/details/79339546 隱含馬爾可夫模型並不是俄
自然語言處理之維特比(Viterbi)演算法
維特比演算法 (Viterbi algorithm) 是機器學習中應用非常廣泛的動態規劃演算法,在求解隱馬爾科夫、條件隨機場的預測以及seq2seq模型概率計算等問題中均用到了該演算法。實際上,維特比演算法不僅是很多自然語言處理的解碼演算法,也是現代數字通訊中使用最頻繁的演
HMM條件下的 前向算法 和 維特比解碼
popu max trac ble -s 序列 最大 可能 content 一、隱馬爾科夫HMM如果: 有且僅僅有3種天氣:0晴天。1陰天。2雨天 各種天氣間的隔天轉化概率mp: mp[3][3] 晴天 陰天 雨天
維特比算法基礎
mage 解碼 post 短路徑 接下來 符號 方法 公式 狀態 維特比算法基礎 維特比算法是一個特殊,但應用最廣的動態規劃算法。利用動態規劃,可以解決任何一個圖中的最短路徑問題。而維特比算法是針對一個特殊的圖--籬笆網絡(Lattice)的有向圖最短路徑問題而提出的。它之
《數學之美》——維特比和他維特比算法
數學 模型 狀態 inf 一個 alt 技術 劃算 spa 維特比乍法是一個特殊但應用最廣的動態規劃算法,可以解決任何一個圖中的最短路徑問題。 這個算法是針對一個特殊的圖——籬笆網絡的有向圖的最短路徑提出的。 這個算法之所以重要,是因為凡是使用隱含馬爾科夫模型描述的問題都可