
Recall || Precision || Average_precision(AP) || Intersection-over-Union(IoU)||NMS
||召回率(Recall)||
||精確率(Precision)||
||平均正確率Average_precision(AP) ||
||交除並(Intersection-over-Union(IoU))||
||非極大值抑制(NMS)||
定義:
True positives : 真陽|True negatives: 真陰 | False positives: 假陽| False negatives: 假陰 |
Precision 與 Recall
Precision其實就是在識別出來的圖片中,True positives所佔的比率: 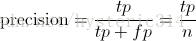
其中的n代表的是(True positives + False positives)
Recall 是True positives與測試集中所有的比值: 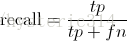
Recall的分母是(True positives + False negatives)
調整閾值
我們可以通過改變閾值,來選擇讓系統識別能出多少個圖片,當然閾值的變化會導致Precision與Recall值發生變化。
下圖為不同閾值條件下,Precision與Recall的變化情況:
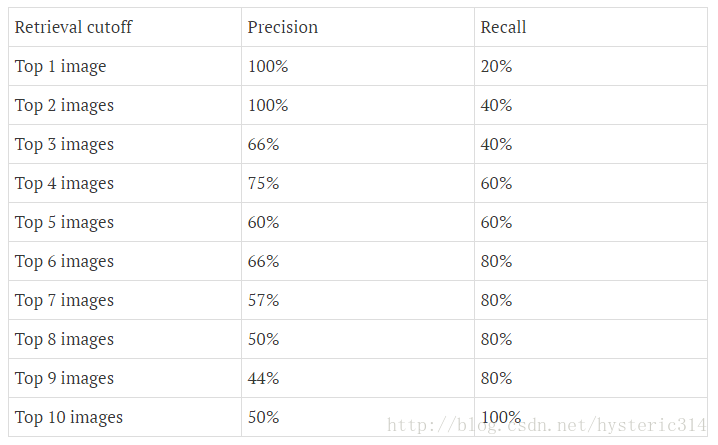
Precision-recall 曲線
如果你想評估一個分類器的效能,一個比較好的方法就是:觀察當閾值變化時,Precision與Recall值的變化情況。如果一個分類器的效能比較好,那麼它應該有如下的表現:讓Recall值增長的同時保持Precision的值在一個很高的水平。而效能比較差的分類器可能會損失很多Precision值才能換來Recall值的提高。通常情況下,文章中都會使用Precision-recall曲線,來顯示出分類器在Precision與Recall之間的權衡。
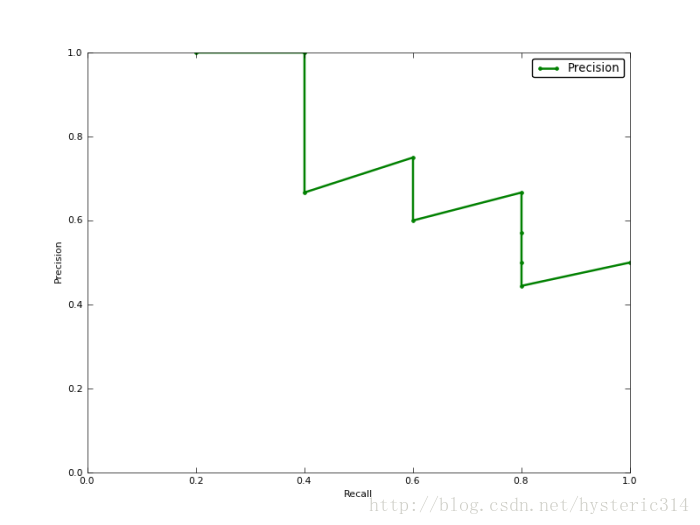
上圖就是分類器的Precision-recall 曲線,在不損失精度的條件下它能達到40%Recall。而當Recall達到100%時,Precision 降低到50%。
Approximated Average precision
相比較與曲線圖,在某些時候還是一個具體的數值能更直觀地表現出分類器的效能。通常情況下都是用 Average Precision來作為這一度量標準,它的公式為: 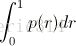
在這一積分中,其中p代表Precision ,r代表Recall,p是一個以r為引數的函式,That is equal to taking the area under the curve.
實際上這一積分極其接近於這一數值:對每一種閾值分別求(Precision值)乘以(Recall值的變化情況),再把所有閾值下求得的乘積值進行累加。公式如下:

在這一公式中,N代表測試集中所有圖片的個數,P(k)表示在能識別出k個圖片的時候Precision的值,而 Delta r(k) 則表示識別圖片個數從k-1變化到k時(通過調整閾值)Recall值的變化情況。
Interpolated average precision
不同於Approximated Average Precision,一些作者選擇另一種度量效能的標準:Interpolated Average Precision。這一新的演算法不再使用P(k),也就是說,不再使用當系統識別出k個圖片的時候Precision的值與Recall變化值相乘。而是使用: 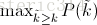
也就是每次使用在所有閾值的Precision中,最大值的那個Precision值與Recall的變化值相乘。公式如下:

下圖的圖片是Approximated Average Precision 與 Interpolated Average Precision相比較。 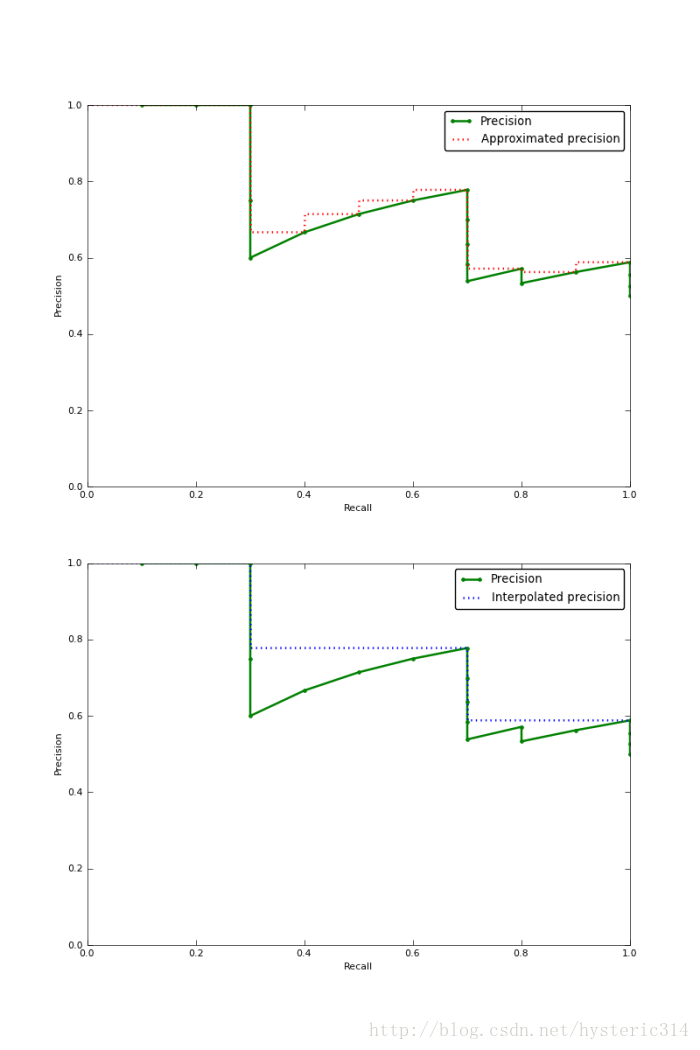
很明顯 Approximated Average Precision與精度曲線挨的很近,而使用Interpolated Average Precision算出的Average Precision值明顯要比Approximated Average Precision的方法算出的要高。
一些很重要的文章都是用Interpolated Average Precision 作為度量方法,並且直接稱算出的值為Average Precision 。PASCAL Visual Objects Challenge從2007年開始就是用這一度量制度,他們認為這一方法能有效地減少Precision-recall 曲線中的抖動。所以在比較文章中Average Precision 值的時候,最好先弄清楚它們使用的是那種度量方式。
IoU
物體檢測需要定位出物體的bounding box,就像下面的圖片一樣,我們不僅要定位出車輛的bounding box 我們還要識別出bounding box 裡面的物體就是車輛。對於bounding box的定位精度,有一個很重要的概念,因為我們演算法不可能百分百跟人工標註的資料完全匹配,因此就存在一個定位精度評價公式:IOU。
IoU這一值,可以理解為系統預測出來的框與原來圖片中標記的框的重合程度。

IOU定義了兩個bounding box的重疊度,如下圖所示:
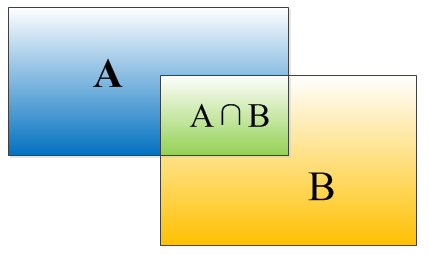
矩形框A、B的一個重合度IOU計算公式為:
IOU=(A∩B)/(A∪B)
即檢測結果Detection Result與 Ground Truth 的交集比上它們的並集,即為檢測的準確率:
如下圖所示:
藍色的框是:GroundTruth
黃色的框是:DetectionResult
綠色的框是:DetectionResult ⋂ GroundTruth
紅色的框是:DetectionResult ⋃ GroundTruth

NMS
主要目的:
在物體檢測非極大值抑制應用十分廣泛,主要目的是為了消除多餘的框,找到最佳的物體檢測的位置。

如上圖中:雖然幾個框都檢測到了人臉,但是我不需要這麼多的框,我需要找到一個最能表達人臉的框。
原理:
非極大值抑制,顧名思義就是把非極大值過濾掉(抑制)。下面是R-CNN中的matlab原始碼
function picks = nms_multiclass(boxes, overlap)
%%boxes為一個m*n的矩陣,其中m為boundingbox的個數,n的前4列為每個boundingbox的座標,格式為
%%(x1,y1,x2,y2);第5:n列為每一類的置信度。overlap為設定值,0.3,0.5 .....
x1 = boxes(:,1);%所有boundingbox的x1座標
y1 = boxes(:,2);%所有boundingbox的y1座標
x2 = boxes(:,3);%所有boundingbox的x2座標
y2 = boxes(:,4);%所有boundingbox的y2座標area = (x2-x1+1) .* (y2-y1+1); %每個%所有boundingbox的面積picks = cell(size(boxes, 2)-4, 1);%為每一類預定義一個將要保留的cell
for iS = 5:size(boxes, 2)%每一類單獨進行
s = boxes(:,iS);
[~, I] = sort(s);%置信度從低到高排序
pick = s*0;
counter = 1;
while ~isempty(I)
last = length(I);
i = I(last);
pick(counter) = i;%無條件保留每類得分最高的boundingbox
counter = counter + 1;
xx1 = max(x1(i), x1(I(1:last-1)));
yy1 = max(y1(i), y1(I(1:last-1)));
xx2 = min(x2(i), x2(I(1:last-1)));
yy2 = min(y2(i), y2(I(1:last-1)));
w = max(0.0, xx2-xx1+1);
h = max(0.0, yy2-yy1+1);
inter = w.*h;
o = inter ./ (area(i) + area(I(1:last-1)) - inter);%計算得分最高的那個boundingbox和其餘的boundingbox的交集面積
I = I(o<=overlap);%保留交集小於一定閾值的boundingbox
end
pick = pick(1:(counter-1));
picks{iS-4} = pick;%保留每一類的boundingbox
end相關推薦
Recall || Precision || Average_precision(AP) || Intersection-over-Union(IoU)||NMS
||召回率(Recall)|| ||精確率(Precision)|| ||平均正確率Average_precision(AP) || ||交除並(Intersection-over-Union(IoU))|| ||非極大值抑制(NMS)|| 定義: True
【YOLO學習】召回率(Recall),精確率(Precision),平均正確率(Average_precision(AP) ),交除並(Intersection-over-Union(IoU))
摘要 在訓練YOLO v2的過程中,系統會顯示出一些評價訓練效果的值,如Recall,IoU等等。為了怕以後忘了,現在把自己對這幾種度量方式的理解記錄一下。 這一文章首先假設一個測試集,然後圍繞這一測試集來介紹這幾種度量方式的計算方法。 大雁與飛機
目標檢測中IOU的介紹(Intersection over Union)
IOU的輸入 1 ground-truth的bounding box 2 預測的bounding box IOU的輸出 輸出為值在[0,1]之間的數字 IOU = 兩個矩形交集的面積/兩個矩形的並集面積 Reference: https://www.
目標識別(object detection)中的 IoU(Intersection over Union)
首先直觀上來看 IoU 的計算公式: 由上述圖示可知,IoU 的計算綜合考慮了交集和並集,如何使得 IoU 最大,需要滿足,更大的重疊區域,更小的不重疊的區域。 兩個矩形窗格分別表示: 左上點、右下點的座標聯合標識了一塊
IoU(Intersection-over-Union)
交併比 (intersection over union) 即為兩個區域的交集與並集的比值。 例如有兩個區域 C 與 G,如下圖表示: 那麼 IoU 的值定義為: IoU=C∩GC∪GIoU=\fra
Intersection over Union(IoU) algorithms
IoU演算法可用與評估兩個多維度資料的相似度,舉一個實際應用,做CV,物件檢測,我們需要評估模型的識別準確率,不同於二元類問題,普通的評估演算法不合適,於是用到了這個演算法,這個演算法簡單易懂,評估效果也不錯。 這裡主要討論如何計算並評估兩個矩形相交程度。有空再訓練一個物件檢測器,來試試水。。
深度學習中IU、IoU(Intersection over Union)的概念理解以及python程式實現
Intersection over Union是一種測量在特定資料集中檢測相應物體準確度的一個標準。我們可以在很多物體檢測挑戰中,例如PASCAL VOC challenge中看多很多使用該標準的做法。 通常我們在 HOG + Linear SVM objec
IoU:Intersection over Union
#傳入的是真值標籤和預測標籤 def bbox_iou(bbox_a, bbox_b): print bbox_a.shape print bbox_b.shape if bbox_a.shape[1] != 4 or bbox_b.shape
【深度學習】深度學習中IU、IoU(Intersection over Union)的概念理解以及python程式實現
IoU(Intersection over Union) Intersection over Union是一種測量在特定資料集中檢測相應物體準確度的一個標準。我們可以在很多物體檢測挑戰中,例如PASCAL VOC challenge中看多很多使用該標準的做法。 通常我們
評價訓練效果的值——精準度(precision)、召回率(recall)、準確率(accuracy)、交除並(IoU)
每次談到這些值得時候都很混亂,這邊通俗的講解出來,然而目前mAP還沒弄明白,後續弄明白再貼出來。。。。 TP是正樣本預測為正樣本 FP是負樣本預測為正樣本 FN是本為正,錯誤的認為是負樣本 TN是本為負,正確的認為是負樣本 precision就是在識別出來的圖片中(
SparkCore運算元(例項)之---- 交集、差集、並集(intersection, subtract, union, distinct, subtractByKey)
1. 交集 intersecion 1.1 原始碼 /** * Return the intersection of this RDD and another one. The output will not contain any duplicate
C之 struct 和 union(十)
C語言 struct union 在 C 語言中我們經常會使用到 struct 和 union,那麽它們兩個各自有何特點呢?今天我們就一探究竟。 我們先來介紹下 struct 。它可以看做是變量的集合,那麽一個空的結構體占多大內存呢?這是一個有趣的問題,按照理論分析,
無線AP如何區分來賓(流動)用戶和正常用戶?
上網 .com 人員 流動 公網 安全 現在 無線網 直接 現在大部分局域網都提供了無線上網的功能。無線主要用於滿足以下幾種需求:無線辦公的需要,比如無線pos機等辦公設備。員工無線上網的需要。來賓、客人的無線上網。這樣就帶來了相關的安全性問題:來賓有可能通過無線接入到企業
oracle分析函式row_number() over()使用(2)
row_number() over ([partition by col1] order by col2) ) as 別名表示根據col1分組,在分組內部根據 col2排序而這個“別名”的值就表示每組內部排序後的順序編號(組內連續的唯一的),[partition by col1] 可省略。 以Scott/ti
hive union (all)
多表合併,欄位名必須匹配 union all 需放於子查詢中,合併後的表要有別名 union 去掉重複的 union all 不去重 eg: select * from (select age, name from test1 union all select age,
目標定位和檢測系列:交併比(IOU)和非極大值抑制(NMS)的python與C/C++實現
Python實現 交併比(Intersection over Union)和非極大值抑制是(Non-Maximum Suppression)是目標檢測任務中非常重要的兩個概念。例如在用訓練好的模型進行測試時,網路會預測出一系列的候選框。這時候我們會用NMS來移除一些多餘的候選框。即移除一些IOU
目標定位和檢測系列(3):交併比(IOU)和非極大值抑制(NMS)的python實現
交併比(Intersection over Union)和非極大值抑制是(Non-Maximum Suppression)是目標檢測任務中非常重要的兩個概念。例如在用訓練好的模型進行測試時,網路會預測出一系列的候選框。這時候我們會用NMS來移除一些多餘的候選框。
(轉載)準確率(accuracy),精確率(Precision),召回率(Recall)和綜合評價指標(F1-Measure )-絕對讓你完全搞懂這些概念
自然語言處理(ML),機器學習(NLP),資訊檢索(IR)等領域,評估(evaluation)是一個必要的工作,而其評價指標往往有如下幾點:準確率(accuracy),精確率(Precision),召回率(Recall)和F1-Measure。 本文將簡單介紹其中幾個概念。中文中這幾個評價指標翻譯各有不同,
吳恩達機器學習(九)Precision、Recall、F-score、TPR、FPR、TNR、FNR、AUC、Accuracy
目錄 0. 前言 學習完吳恩達老師機器學習課程的機器學習系統設計,簡單的做個筆記。文中部分描述屬於個人消化後的理解,僅供參考。 如果這篇文章對你有一點小小的幫助,請給個關注喔~我會非常開心的~ 0. 前言 針對二分類的結果,對模型進行評估,通常有以下
準確率(accuracy),精確率(Precision),召回率(Recall)和綜合評價指標(F1-Measure )
自然語言處理(ML),機器學習(NLP),資訊檢索(IR)等領域,評估(evaluation)是一個必要的工作,而其評價指標往往有如下幾點:準確率(accuracy),精確率(Precision),召回率(Recall)和F1-Measure。 本文將簡單介紹其中幾個概念。