
字串匹配演算法之:有限狀態自動機
什麼叫有限狀態自動機
先看一個圖:
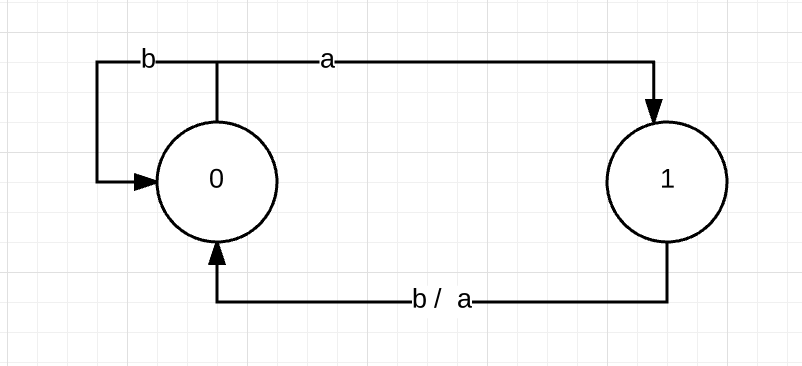
上面這個圖描述的就叫一個有限狀態自動機,圖中兩個圓圈,也叫節點,用於表示狀態,從圖中可以看成,它有兩個狀態,分別叫0和1. 從每個節點出發,都會有若干條邊,當處於某個狀態時,如果輸入的字元跟該節點出發的某條邊的內容一樣,那麼就會引起狀態的轉換。例如,如果當前狀態處於0,輸入是字元a,那麼狀態機就會從狀態0進入狀態1.如果當前狀態是1,輸入字元是b或a,那麼,狀態機就會從狀態1進入狀態0.如果當前所處的狀態,沒有出去的邊可以應對輸入的字元,那麼狀態機便會進入到錯誤狀態。例如,如果當前處於狀態0,輸入字元是c,那麼狀態機就會出錯,因為從狀態0開始,沒有哪條邊對應的字元是c.
狀態機會有一個初始節點,和一個接收節點,以上圖為例,我們可以設定初始節點為0,接收節點為1,當進行一系列的輸入,使得狀態機的狀態不斷變化,只要最後一個輸入使得狀態機處於接收節點,那麼就表明當前輸入可以被狀態機接收。例如對應字串”abaaa”, 從初始節點0開始,狀態機根據該字串的輸入所形成的狀態變化序列為:{0,1,0,1,0,1}。由於最後狀態機處於狀態1,所以該字串可以被狀態機接收。如果輸入的字串是:abbaa, 那麼狀態機的變化序列為:{0,1,0,0,1,0}, 由於最後狀態機處於非接收狀態,因此這個字串被狀態機拒絕。
在程式中,我們一般使用二維表來表示一個狀態機,例如上面的狀態機用二維表來表示如下:
| 輸入 | a | b |
|---|---|---|
| 狀態0 | 1 | 0 |
| 狀態1 | 0 | 0 |
通過查表,我們便可知道狀態機的轉換,例如處於狀態0,輸入字元是a時,我們從表中得到的數值是1,也就是說處於狀態0,輸入是字元a,那麼狀態機將轉入狀態節點1.
一個文字匹配流程的描述
接下來我們看看一個文字的匹配流程,假定要查詢的字串為P=”ababaca”, 被查詢的文字為T=”abababacaba”. 一次讀入T的一個字元,用S表示當前讀入的T的字元,一開始讀入一個字元,於是S=a.然後看看,從P開始,連續幾個字元所構成的字串可以成為S的字尾,由於當前S只有一個字元a,於是從P開始,連續1個字元所形成的字串”a”,可以作為S的字尾。把這個字串的長度記為k,於是此時k 等於1. 繼續從T中讀入字元,於是S=”ab”, 此時,從P開始,連續兩個字元所構成的字串”ab”可以作為S的字尾,於是k = 2.反覆這麼操作,於是便有以下序列:
- S=a, k = 1, P[1] 是S的字尾
- S=ab, k = 2, P[1,2] 是S的字尾
- S=aba, k = 3, P[1,2,3]是S的字尾
- S=abab, k= 4, P[1,2,3,4]是S的字尾
- S=ababa, k = 5, P[1,2,3,4,5]是S的字尾
- S=ababab, k = 4, P[1,2,3,4]是S的字尾
- S=abababa, k = 5, P[1,2,3,4,5]是S的字尾
- S=abababac, k = 6, P[1,2,3,4,5,6]是S的字尾
- S=abababaca, k = 7, P[1,2,3,4,5,6,7]是S的字尾
- S=abababacab, k =2, P[1,2] 是S的字尾
- S=abababacaba, k = 3, P[1,2,3] 是S的字尾。
注意看第9步,P的長度是7,整個字串P成為了字串S的字尾,而此時的S是文字T的字首,這不就表明文字T含有字串P了嗎。在每一個步驟中,我們都需要從P的第一個字元開始,看看最多能連續讀取幾個字元,使得他們能成為S的字尾,假設P的字元個數為m, 那麼這個讀取過程最多需要讀取m個字元,於是複雜度為O(m). 如果有某種辦法,使得我們一次就可以知道從P開始,連續讀取幾個字元就可以構成S 的字尾,假設文字T含有n個字元,那麼我們就可以在O(n)的時間內判斷,T是否含有字串P.因為上面的步驟最多可以執行n次。
於是當前問題變成,構造一個方法,使得一次執行便能知道從P開始,連續讀取幾個字元能使,得這幾個字元構成的字串是S的字尾。這個方法,就需要上面我們提到的有限狀態自動機。
用於字串匹配的自動機
假定字串P和文字T只由a,b兩個字元組成,也就是字符集為
| 輸入 | a | b | c |
|---|---|---|---|
| 狀態0 | 1 | 0 | 0 |
| 狀態1 | 1 | 2 | 0 |
| 狀態2 | 3 | 0 | 0 |
| 狀態3 | 1 | 4 | 0 |
| 狀態4 | 5 | 0 | 0 |
| 狀態5 | 1 | 4 | 6 |
| 狀態6 | 7 | 0 | 0 |
| 狀態7 | 1 | 2 | 0 |
利用上面的狀態機,依次讀入T的字元,如果狀態機跳轉到狀態q,那就表明從P的第一個字元開始,連續讀取q個字元,所形成的字串可以構成是S的字尾,也就是說,當我們的狀態機跳轉到狀態7時,我們就可以得知文字T,包含字串P.
我們走一遍這個過程,首先狀態機處於狀態0,讀入T[0]=a, S= a, 查表可知進入狀態1,讀入T[1]=b, S=ab, 查表可知,進入狀態2,讀入T[2]=a,查表可知進入狀態3,讀入T[3]=b, S=abab,查表可知進入狀態4,讀入T[4]=a,S=ababa,查表可知進入狀態5,讀入T[5]=b,S=ababab,查表可知進入狀態4,讀入T[6]=a, S=abababa,查表可知進入狀態5,讀入T[7]=c,S=abababac,查表可知進入狀態6,讀入T[8]=a,S=abababaca,查表可知進入狀態7,此時,我們可以得出結論,文字T包含有字串P.
程式碼實現
import java.util.HashMap;
public class StringAutomaton {
private HashMap<Integer, HashMap<Character, Integer>> jumpTable = new HashMap<Integer, HashMap<Character, Integer>>();
String P = "";
private final int alphaSize = 3;
public StringAutomaton(String p) {
this.P = p;
makeJumpTable();
}
private void makeJumpTable() {
int m = P.length();
for (int q = 0; q <= m; q++) {
for (int k = 0; k < alphaSize; k++) {
char c = (char)('a' + k);
String Pq = P.substring(0, q) + c;
int nextState = findSuffix(Pq);
System.out.println("from state " + q + " receive input char " + c + " jump to state " + nextState);
HashMap<Character, Integer> map = jumpTable.get(q);
if (map == null) {
map = new HashMap<Character, Integer>();
}
map.put(c, nextState);
jumpTable.put(q, map);
}
}
}
private int findSuffix(String Pq) {
int suffixLen = 0;
int k = 0;
while(k < Pq.length() && k < P.length()) {
int i = 0;
for (i = 0; i <= k; i++) {
if (Pq.charAt(Pq.length() - 1 - k + i) != P.charAt(i)) {
break;
}
}
if (i - 1 == k) {
suffixLen = k+1;
}
k++;
}
return suffixLen;
}
public int match(String T) {
Integer q = 0;
System.out.println("Begin matching...");
for (int n = 0; n <= T.length(); n++) {
HashMap<Character, Integer> map = jumpTable.get(q);
int oldState = q;
q = map.get(T.charAt(n));
if (q == null) {
return -1;
}
System.out.println("In state " + oldState + " receive input " + T.charAt(n) + " jump to state " + q);
if (q == P.length()) {
return q;
}
}
return -1;
}
}
程式碼中,makeJumpTable呼叫用來構建跳轉表,findSuffix用來查詢最大的數值K, 使得P[1…k] 是字串
match依靠跳轉表來判斷,輸入的字串T是否包含字串P,如果T的最後一個字元輸入狀態機後,從跳轉表得到的狀態的值等於P的長度m,那麼表明T包含字串P.具體的程式除錯過程請參看視訊。
我們只給出了演算法的實現流程,演算法的數學原理比較複雜,我們將在下一節詳解。
相關推薦
字串匹配演算法之:有限狀態自動機
什麼叫有限狀態自動機 先看一個圖: 上面這個圖描述的就叫一個有限狀態自動機,圖中兩個圓圈,也叫節點,用於表示狀態,從圖中可以看成,它有兩個狀態,分別叫0和1. 從每個節點出發,都會有若干條邊,當處於某個狀態時,如果輸入的字元跟該節點出發的某條邊的
多模字串匹配演算法之AC自動機—原理與實現
簡介: 本文是博主自身對AC自動機的原理的一些理解和看法,主要以舉例的方式講解,同時又配以相應的圖片。程式碼實現部分也予以明確的註釋,希望給大家不一樣的感受。AC自動機主要用於多模式字串的匹配,本質上是KMP演算法的樹形擴充套件。這篇文章主要介紹AC自動機的工作原理,並在此
字串匹配演算法之KMP演算法詳情
package demo; /* 字串匹配演算法 */ public class StringKMP { //找出從第一個字元開始 子串T在主串S的第一個位置 如果沒有則返回-1 public static int index(String S, String T)
字串匹配演算法之KMP總結
字串匹配有很多方法,比如暴力,雜湊等等,還有一種廣為人知的演算法 − − −
字串匹配演算法之Sunday演算法
1 import java.util.HashMap; 2 import java.util.LinkedList; 3 import java.util.List; 4 import java.util.Map; 5 6 /** 7 * @author Scott 8
字串匹配演算法SMA 總結之四:自動機演算法
自動機匹配演算法常使用連結串列表示,這裡使用陣列,佔用的空間太大了些, 有時間詳細說說 #include <iostream> using namespace std; const int alphabet_len=128; //construct an a
演算法-字串匹配(String Matching)-(2)-有限自動機
該演算法通過構建有限自動機進行字串匹配,此文基本上是對[2]的 32章的Digest 1. 有限自動機的定義[2] P564: A finite automaton M is a 5-tuple (Q, q0, A, Σ, δ), where Q is a f
【學渣】字元匹配之有限狀態自動機--應用在爬蟲程式中匹配網址
關於自動機的原理的文章已經有很多了,我就不再多說了,我覺得很多部落格都寫的很好 我就寫一下在網址匹配方面的應用吧 其實很多人大都會選擇正則表示式 如果是有規律的匹配,應該有一個狀態轉移函式,但是我沒有為下圖找到規律,所以就用了最蠢的方法 如果是連續的輸入,比如ababab
演算法: Boyer-Moore字串匹配演算法
Boyer-Moore演算法不僅效率高,而且構思巧妙,容易理解。1977年,德克薩斯大學的Robert S. Boyer教授和J Strother Moore教授發明了這種演算法。 下面,我根據Moore教授自己的例子來解釋這種演算法。 1. 假定字串為"HERE IS A SIM
KMP演算法:O(n)線性時間字串匹配演算法
KMP演算法包括兩個子程式。其中KMP-MATCHER指字串匹配子程式,COMPUTE-PREFIX則為部分匹配表NEXT[]生成程式。《演算法導論》一書中有一句話,我認為說的非常透徹:“這兩個程式有很多相似之處,因為它們都是一個字串對模式P的匹配:KMP-MATCHER是文字T針對模式P的
字串匹配演算法(二)窮舉與自動機
Rob Pike, 最偉大的C 語言大師之一, 在《Notes on C Programming》中闡述了一個原則:花哨的演算法比簡單演算法更容易出bug、更難實現,儘量使用簡單的演算法配合簡單的資料結構。而Ken Thompson——Unix 最初版本的設計者和實現者,禪宗偈語般地對Pike 的這一原則作了
面試演算法之字串匹配演算法,Rabin-Karp演算法詳解
既然談論到字串相關演算法,那麼字串匹配是根本繞不過去的坎。在面試中,面試官可能會要你寫或談談字串的匹配演算法,也就是給定兩個字串,s 和 t, s是要查詢的字串,t是被查詢的文字,要求你給出一個演算法,找到s在t中第一次出現的位置,假定s為 acd, t為a
Sunday演算法:最快的字串匹配演算法
之前被KMP的next陣列搞的頭昏腦脹說不上也是比較煩人的,今天看到還有這麼有趣而且高效的演算法(比KMP還快),看來有必要
【Codeforces 506E】Mr.Kitayuta’s Gift&&【BZOJ 4214】黃昏下的禮物 dp轉有限狀態自動機+矩陣乘法優化
合數 現在 子序列 pri blue gre () div while 神題……胡亂講述一下思維過程……首先,讀懂題.然後,轉化問題為構造一個長度為|T|+n的字符串,使其內含有T這個子序列.之後,想到一個簡單的dp.
雙目立體視覺匹配演算法之視差圖disparity計算——SAD演算法、SGBM演算法
一、SAD演算法 1.演算法原理 SAD(Sum of absolute differences)是一種影象匹配演算法。基本思想:差的絕對值之和。此演算法常用於影象塊匹配,將每個畫素對應數值之差的絕對值求和,據此評估兩個影象塊的相似度。該演
字串匹配演算法的分析【轉】
轉自:https://www.cnblogs.com/adinosaur/p/6002978.html 問題描述 字串匹配問題可以歸納為如下的問題:在長度為n的文字T[1...n]中,查詢一個長度為m的模式P[1...m]。並且假設T,P中的元素都來自一個有限字母集合Ʃ。如果存在位移s,其中0≤s≤n-m
非確定有限狀態自動機的構建-NFA的定義和實現
保留版權,轉載需註明出處(http://blog.csdn.net/panjunbiao)。 非確定有限狀態自動機(Nondeterministic Finite Automata,NFA)由以下元素組成: 一個有限的狀態集合S 一個輸入符號集合Sigma,並且架設空字元eps
逆向最大匹配演算法之python實現
1.執行環境 python 3.6.4 2.思路 大致思路與正向相同,可參考我的上一篇部落格。 3.程式碼實現 import codecs #獲得分詞字典,儲存為字典形式 f1 = codecs.open('./corpus/WordList.txt', 'r', encodi
字串匹配演算法實現
KMP演算法 1 void Next(char *src,int n,int *next) 2 { 3 int j,k; 4 j=0; 5 k=-1; 6 next[0] = -1; 7 while(j<n-1) 8 { 9 if(k==-1 || src[j] == src[
樸素字串匹配演算法
最簡單的字串匹配方法,傳說中的在特殊情況的暴力求解: 虛擬碼: naive_string_matcher(t,p): n=len(t) m=len(p) for s =0 to n-m: if p[1..m]==t[s+1..s+m]: