
Field-aware Factorization Machines for CTR Prediction簡介與程式碼實現
阿新 • • 發佈:2019-01-14
摘要
FM被廣泛應用在CTR,但是FFM在一些世界範圍的CTR競賽表現好於目前存在的模型。作者實現了相關程式碼,並與一些競爭模型進行了全面的分析。實驗證明FFM在某些分類問題上非常有用。
介紹
FFM
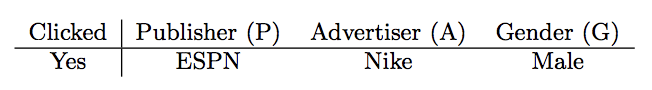
對於這個例子來說,FM的隱向量表示應該為:
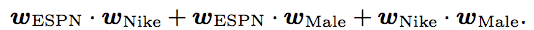
在FM中,每個特徵只有一個隱向量來學習隱性的影響。拿ESPN來做例子, 被用來學習隱性的與Nike和Male的影響,但是因為Nike和Male是屬於不同的領域的,那麼使用同一個 可能不太合適。
在FFM中,每個特徵都有一些隱性的向量,取決於其他特徵的所屬領域。比如對於上述例子,FFM的隱向量表示為:
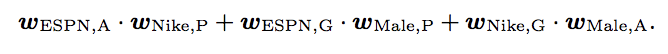
所以其數學模型為:
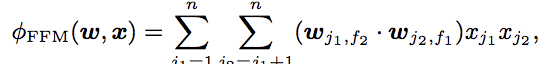

整個演算法步驟:

優化
使用AdaGrad優化方法,自適應優化學習速率,對頻繁變化的引數以更小的步長進行更新,而稀疏的引數以更大的步長進行更新。
梯度:
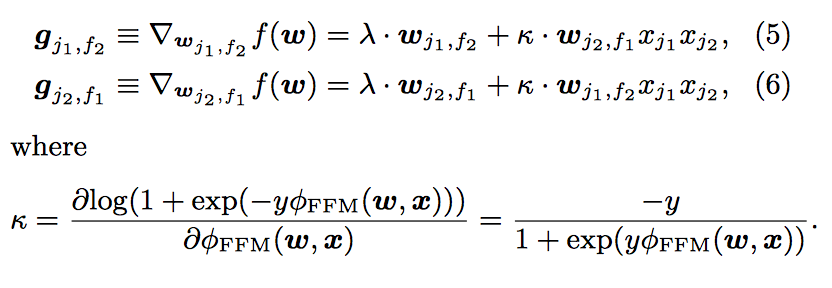
AdaGrad:
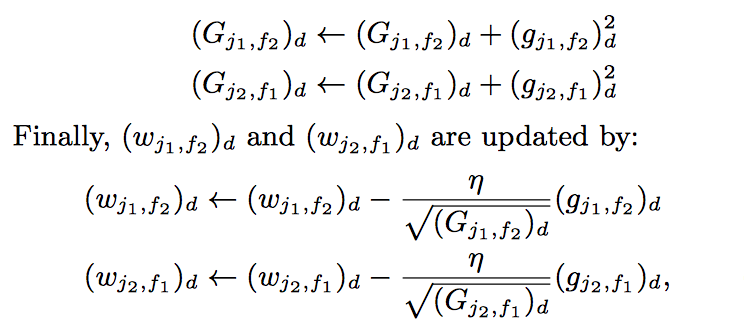
G的初始值為1,避免分母為0,過大
缺陷

僅針對二次項,FM有nk個引數,而FFM有nfk個引數。而且FFM無法利用化簡,所以計算複雜度為 .所以這需要較大的硬體資源來提供運算。
Impact of Parameter
-
k值不需要太大,沒有什麼提升
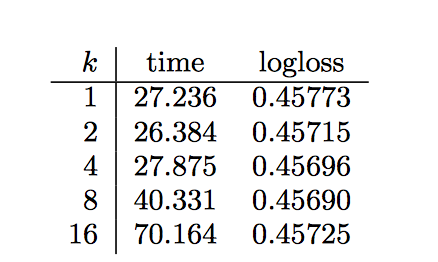
-
和 需要著重調整

Early Stopping
防止過擬合

程式碼
import tensorflow as tf
import numpy as np
import os
input_x_size = 20
field_size = 2
vector_dimension = 3
# 使用SGD,每一個樣本進行依次梯度下降,更新引數
batch_size = 1
all_data_size = 1000
alpha = 0.01
MODEL_SAVE_PATH = "TFModel"
MODEL_NAME = "FFM"
def createTwoDimensionWeight(input_x_size,field_size,vector_dimension): #初始化w2
weights = tf.truncated_normal([input_x_size,field_size,vector_dimension]) #預設生成均值為0,標準差為1的[input_x_size,field_size,vector_dimension]維度的張量
tf_weights = tf.Variable(weights)
return tf_weights
def computation(input_x,input_x_field,TwoWeights):
thirdValue=tf.Variable(0.0,dtype=tf.float32)
input_shape=input_x_size
for i in range(input_shape-1):
featureIndex1 = i #對應每個x1的特徵序號
fieldIndex1 = int(input_x_field[i]) #對應特徵x1的field序號
for j in range(i + 1, input_shape):
featureIndex2 = j #對應每個x2的特徵序號
fieldIndex2 = int(input_x_field[j]) #對應特徵x2的field序號
vectorLeft = tf.convert_to_tensor([[featureIndex1, fieldIndex2, i] for i in range(vector_dimension)]) #轉換成張量
weightLeft = tf.gather_nd(TwoWeights, vectorLeft) #取對應位置的值,只不過是在張量上
weightLeftAfterCut = tf.squeeze(weightLeft) #消除維度為1的shape
vectorRight = tf.convert_to_tensor([[featureIndex2, fieldIndex1, i] for i in range(vector_dimension)])
weightRight = tf.gather_nd(TwoWeights, vectorRight)
weightRightAfterCut = tf.squeeze(weightRight)
tempValue = tf.reduce_sum(tf.multiply(weightLeftAfterCut, weightRightAfterCut))
indices2 = [i]
indices3 = [j]
xi = tf.squeeze(tf.gather_nd(input_x, indices2))
xj = tf.squeeze(tf.gather_nd(input_x, indices3))
product = tf.reduce_sum(tf.multiply(xi, xj))
secondItemVal = tf.multiply(tempValue, product)
tf.assign(thirdValue, tf.add(thirdValue, secondItemVal))
return thirdValue
def gen_data():
labels = [-1,1]
y = [np.random.choice(labels,1)[0]for _ in range(all_data_size)] #表示在【-1,1】中選擇一個數,後面加【0】是為了取值,而不是保持array型別
x_field = [i // 10 for i in range(input_x_size)]
x = np.random.randint(0,2,size=(all_data_size,input_x_size))
return x,y,x_field
if __name__=='__main__':
global_step = tf.Variable(0, trainable=False)
trainx, trainy, trainx_field = gen_data()
input_x = tf.placeholder(tf.float32, [input_x_size])
input_y = tf.placeholder(tf.float32)
lambda_v = tf.constant(0.001, name='lambda_v')
weight = createTwoDimensionWeight(input_x_size, # 建立二次項的權重變數
field_size,
vector_dimension) # n * f * k
y_ = computation(input_x, trainx_field, weight)
l2_norm = tf.reduce_sum(tf.multiply(lambda_v, tf.pow(weight, 2)))
loss = tf.log(1 + tf.exp(-input_y * y_)) + l2_norm
train_step = tf.train.AdagradOptimizer(learning_rate=alpha,initial_accumulator_value=1).minimize(loss)
saver = tf.train.Saver(max_to_keep=1) #只保留最後的一個模型
max_acc=100000
is_train=False
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for j in range(10):
if is_train:
for t in range(all_data_size):
input_x_batch = trainx[t]
input_y_batch = trainy[t]
predict_loss, _, steps = sess.run([loss, train_step,global_step],
feed_dict={input_x: input_x_batch, input_y: input_y_batch})
print("After {step} training step(s) , loss on training batch is {predict_loss} "
.format(step=steps, predict_loss=predict_loss))
global_step+=1
if predict_loss<max_acc:
max_acc=predict_loss
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=steps)
else:
model_file = tf.train.latest_checkpoint(MODEL_SAVE_PATH+'/')
saver.restore(sess, model_file)
for t in range(all_data_size):
val_loss, yhat = sess.run([loss, y_], feed_dict={input_x: trainx[t],input_y: trainy[t]})
print("loss on training batch is {predict_loss} ,prediction is {yhat},real y is {y}"
.format(predict_loss=val_loss,yhat=yhat,y=trainy[t]))
上述程式碼在重新匯入model以後,執行的所得到的yhat均不變,可能有一些問題,但是總體思路應該是沒錯的,如果有大佬能幫忙解決一下這個問題就更好了。