
為什麼演算法漸進複雜度中對數的底數總為2
在分析各種演算法時,經常看到O(log2n)或O(nlog2n)這樣的漸進複雜度。不知有沒有同學困惑過,為什麼演算法的漸進複雜度中的對數都是以2為底?為什麼沒有見過O(nlog3n)這樣的漸進複雜度?本文解釋這個問題。
三分式歸併排序的時間複雜度
先看一個小例子。
大多數人應該對歸併排序(merge sort)很熟悉,它的漸進複雜度為O(nlog2n)。那麼如果我們將歸併排序改為均分成三份而不是兩份,其演算法時間複雜度是否有變化呢?
遞迴分析
下面通過遞迴分析對三分式歸併排序的時間複雜度進行分析。因為不管是三分還是二分,對於總共n個數據來說,一遍合併的複雜度為O
T(n)=3T(n/3)+O(n)
如果把這個遞迴式的遞迴樹畫出來,很容易得到T(n)=O(nlog3n)。如下圖所示:
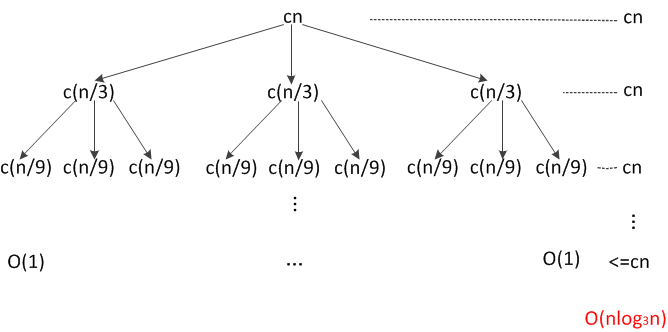
對數的陷阱
那麼這是否意味著三分式歸併排序在時間複雜度上要優於二分式的歸併排序呢?因為直覺上nlog3n比nlog2n要優一些。
實際上三分式歸併排序的時間複雜度確實是T(n)=O(nlog3n),而且同時也是T(n)=O(nlog2n)。
這看起來似乎是矛盾的,n
logab=logcblogca
其中a和c均大於0且不等於1。
根據換底公式可以得出:
log3n=log2nlog23
所以nlog3n比nlog2n只差一個常係數1log23。因此,從漸進時間複雜度看,三分式歸併並不比二分式歸併更優,當然還是有個常係數的差別的。
更一般的:
logan=log2nlog2a
因此對於大於1的a來說,都與O(log2n)差一個常係數而已,因此為了簡便,一般都用O(log2n)表示對數的漸進複雜度,這就解決了本文初始的疑問。當然,以任何大於1的a為底數都是沒有問題的。
from: http://blog.codinglabs.org/articles/why-logarithm-base-of-asymptotic-time-complexity-always-two.html
相關推薦
為什麼演算法漸進複雜度中對數的底數總為2
在分析各種演算法時,經常看到O(log2n)O(log2n)或O(nlog2n)O(nlog2n)這樣的漸進複雜度。不知有沒有同學困惑過,為什麼演算法的漸進複雜度中的對數都是以2為底?為什麼沒有見過O(nlog3n)O(nlog3n)這樣的漸進複雜度?本文解釋這個問
演算法時間複雜度中O(logN)的底數是多少
經常在演算法書籍中看到logN的身影,那麼這個對數的底數是多少呢? Weiss 在他的著作《資料結構與演算法分析》中曾指出:在電腦科學中,除非有特殊的說明,否則所有的對數都是以2為底的。 不過無論底數是什麼,log級別的漸進意義是一樣的。也就是說該演算法的時
演算法初級01——認識時間複雜度、對數器、 master公式計算時間複雜度、小和問題和逆序對問題
雖然以前學過,再次回顧還是有別樣的收穫~ 認識時間複雜度 常數時間的操作:一個操作如果和資料量沒有關係,每次都是固定時間內完成的操作,叫做常數操作。 時間複雜度為一個演算法流程中,常數運算元量的指標。常用O(讀作big O)來表示。具體來說,在常數運算元量的表示式中,
設任意n個整數存放於陣列A[1..n]中,試編寫演算法,將所有正數排在所有負數前面(要求:演算法時間複雜度為O(n))。
注意陣列的實際長度 #include <iostream> using namespace std; void sort(int A[],int n) { int i=0;//陣列的頭下標 int j,x; j=n-1;//陣列的尾下標 while
刪除連結串列中的某個數,演算法時間複雜度是O(n)
import java.util.Scanner; /** * */ /** * @author jueying: * @version 建立時間:2018-10-29 下午04:05:03 * 類說明 */ /** * @author jueying
在一個含有空格字元的字串中加入XXX,演算法時間複雜度為O(N)
import java.util.Scanner; /** * */ /** * @author jueying: * @version 建立時間:2018-10-18 下午10:54:54 * 類說明 */ /** * @author jueying
時間複雜度中的log(n)底數到底是多少
其實這裡的底數對於研究程式執行效率不重要,寫程式碼時要考慮的是資料規模n對程式執行效率的影響,常數部分則忽略,同樣的,如果不同時間複雜度的倍數關係為常數,那也可以近似認為兩者為同一量級的時間複雜度。 現在來看看為什麼底數具體為多少不重要? 讀者只需要掌握(依稀記得)中學數學知識
資料結構與演算法的分析 —— 漸進複雜度(三個記號)
對於某些問題,一些演算法更適合於用小規模的輸入,而另一些則相反。幸運的是,在評價演算法執行效率時,我們往往可以忽略掉其處理小規模問題時的能力差異,轉而關注其在處理大規模資料時的表現。道理是顯見的,處理大規模的問題時,效率的些許差異都將對實際執行效率產生巨大的影響
演算法分析基礎---漸進複雜度
Notation Name[13] Description Formal Definition Limit Definition[16][17][18][13][11] Small O; Small Oh is dominated by asympt
時間複雜度中O(log n) Log的底數是多少
其實這裡的底數對於研究程式執行效率不重要,寫程式碼時要考慮的是資料規模n對程式執行效率的影響,常數部分則忽略,同樣的,如果不同時間複雜度的倍數關係為常數,那也可以近似認為兩者為同一量級的時間複雜度。 現在來看看為什麼底數具體為多少不重要? 讀者只需要掌握(依稀記得)中學數學
考研中的演算法時間複雜度分析
1.常用的時間複雜度比較關係為O(1) <= O(log2(n)) <= O(n) <= O(nlog2(n)) <= O(n2) <= O(n3) ..... <=O(nk) <= O(2(n))2.具體步驟 1)確定演算法中
資料結構與演算法之複雜度分析篇
一、內容 最好情況時間複雜度、最壞情況時間複雜度、平均情況時間複雜度、均攤時間複雜度。 二、為什麼要引入這幾個概念? 有助於我們可以更加全面地表示一段程式碼的執行效率,同樣一段
演算法妙應用-演算法的複雜度
0、什麼是演算法的複雜度? 對於任何一個程式來說,都可以從三個方面進行分析,分別是 輸入、處理、輸出,也即 IPO(Input、Process、Output),這種分析方法對硬體和軟體程式都是適用的。 資料的來源(Input):可以是硬體感測器收集的,也可以是從網上爬取的...。資料的輸
2.資料結構和演算法——演算法時間複雜度
定義 在進行演算法分析時,語句總的執行次數T(n)時關於問題規模n的函式,進而分析T(n)隨n的變化情況並確定T(n)的數量級。演算法的時間複雜度,也就是演算法的時間度量,記作:T(n) = O(f(n))。它表示歲問題規模n的增大,稱作演算法的漸進時間複雜度,簡稱為時間複雜度
堆排序優化與幾個排序演算法時間複雜度
我們通常所說的堆是指二叉堆,二叉堆又稱完全二叉樹或者叫近似完全二叉樹。二叉堆又分為最大堆和最小堆。 堆排序(Heapsort)是指利用堆這種資料結構所設計的一種排序演算法,它是選擇排序的一種。可以利用陣列的特點快速定位指定索引的元素。陣列可以根據索引直接獲取元素,時間複雜度為O(1),也就是常量,因此對於取
常用資料結構與演算法時間複雜度求解
1.0 資料結構的相關概念 2.0 一些基本演算法的時間複雜度 O(1): int x=1; O(n): for(int i = 0; i < n; i++){ printf("%d",i); } O(lo
第一章作業2-演算法時間複雜度和空間複雜度
1-1 演算法分析的兩個主要方面是時間複雜度和空間複雜度的分析。 (1分) T 1-2 N^2logN和NlogN^2具有相同的增長速度。 (2分) F: N^2logN較快 ,取對數對增長影響還是蠻大的,畢竟裸的logn函式後期增長
演算法 - 空間複雜度 時間複雜度
關於演算法空間複雜度的問題 ‘演算法空間複雜度’,別以為這個東西多麼高大上,我保證你看完這篇文章就能明白。 最近在啃演算法,發現非常有趣。在我學習的過程中發現了一個問題,那就是空間複雜度的問題,它絕對是效率的殺手。 關於空間複雜度的介紹(摘自百度) 空間複雜度(Sp
演算法時間複雜度
時間複雜度 演算法複雜度分為時間複雜度和空間複雜度。其作用: 時間複雜度是指執行演算法所需要的計算工作量;而空間複雜度是指執行這個演算法所需要的記憶體空間。(演算法的複雜性體現在執行該演算法時的計算機所需資源的多少上,計算機資源最重要的是時間和空間(即暫存器)資
演算法筆記-複雜度分析1
演算法複雜度分析 是什麼 什麼是演算法複雜度分析? 通過時間和空間兩個維度來評估演算法和資料結構的效能。 用時間複雜度 (時間漸進複雜度) 和空間複雜度 (空間漸進複雜度)兩個概念來描述效能問題,統稱複雜度。 演算法複雜度描述的是演算法執行時間以及佔用空間與資料規模的關聯關係 演算法複