
正則化對深層神經網路的影響分析
本文是基於吳恩達老師《深度學習》第二週第一課練習題所做,目的在於探究引數初始化對模型精度的影響。
一、資料處理
本文所用第三方庫如下,其中reg_utils 和 testCases_regularization為輔助程式從這裡下載。
import numpy as np
import matplotlib.pyplot as plt
from reg_utils import *
import sklearn
import sklearn.datasets
import scipy.io
from testCases_regularization import *本次課程中使用了一個比較有趣的例子:使用人工智慧的方法為一支足球隊做技術分析,為隊員預測頭球破門率最高的位置。

下圖給出了過去十場比賽中,該隊與對手搶得頭球點的資料集

藍色點表示本隊搶到頭球時隊員所在的位置,紅點表示對手搶到頭球時所在的位置。本文的任務是建立深層神經網路對該資料集進行訓練,為了分析正則化對構建神經網路的作用,我們分別構建無正則化模型、L2正則化模型和dropout模型,並對三者的結果進行對比研究。
二、深層神經網路模型
在該文中已經詳細說明過模型所用到的各函式的意義,再此不再贅述。
def model(X, Y, learning_rate = 0.3, num_iterations = 30000, print_cost = True, lambd = 0,keep_prob = 1): grads = {} costs = [] m = X.shape[1] layers_dims = [X.shape[0], 20, 3, 1] parameters = initialize_parameters(layers_dims) for i in range(0, num_iterations): if keep_prob == 1: a3, cache = forward_propagation(X, parameters) elif keep_prob < 1: a3, cache = forward_propagation_with_dropout(X, parameters) if lambd == 0: cost = compute_cost(a3, Y) else: cost = compute_cost_with_regularization(a3, Y, parameters, lambd) assert(lambd == 0 or keep_prob == 1) if lambd == 0 and keep_prob == 1: grads = backward_propagation(X, Y, cache) elif lambd != 0: grads = backward_propagation_with_regularization(X, Y, cache, lambd) elif keep_prob < 1: grads = backward_propagation_with_dropout(X, Y, cache, keep_prob) parameters = update_parameters(parameters, grads, learning_rate) if print_cost == True and i % 10000 ==0: print("cost after iterations {}:{}".format(i,cost)) if print_cost == True and i % 1000 ==0: costs.append(cost) plt.plot(costs) plt.xlabel("iterations (per 1000)") plt.ylabel("cost") plt.title("Learning rate = " + str(learning_rate)) plt.show() return parameters
三、無正則化模型
我們先測試一下模型沒有正則化和dropout優化的情況下,測試效果是怎樣的
parameters = model(train_X, train_Y)
print("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)cost after iterations 0:0.6557412523481002 cost after iterations 10000:0.16329987525724213 cost after iterations 20000:0.13851642423245572

On the training set:
Accuracy: 0.9478672985781991
On the test set:
Accuracy: 0.915
在訓練集和測試集上的預測精度分別是94.78%,91.5%,訓練集上精度比測試集高3%,看起來有些過擬合,我們打印出邊界曲線看下效果。

圖中可以明顯看出,對於測試集確實有些過擬合,下面我們使用L2正則化和dropout方法,看看如何改善過擬合現象。
四、L2正則化模型
L2範數在神經網路中也成為F範數(弗羅貝尼烏斯範數),在使用L2正則化的同時,cost函式也需要進行相應的修改。

def compute_cost_with_regularization(A3, Y, parameters, lambd):
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = compute_cost(A3, Y)
L2_regularization_cost = (1. / m * lambd / 2) * (np.sum(np.square(W1))+
np.sum(np.square(W2))+
np.sum(np.square(W3)))
cost = cross_entropy_cost + L2_regularization_cost
return costdef backward_propagation_with_regularization(X, Y, cache, lambd):
m = X.shape[1]
(Z1, A1, W1, b1,Z2, A2, W2, b2,Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1. / m * np.dot(dZ3, A2.T) + lambd / m * W3
db3 = 1. / m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2>0))
dW2 = 1. / m * np.dot(dZ2, A1.T) + lambd / m * W2
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1>0))
dW1 = 1. / m * np.dot(dZ1, X.T) + lambd / m * W1
db1 = 1. / m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
我們設lambd = 0.7,執行模型觀察預測效果:
cost after iterations 0:0.6974484493131264
cost after iterations 10000:0.26849188732822393
cost after iterations 20000:0.2680916337127301parameters = model(train_X, train_Y, lambd = 0.7)
print("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
On the training set:
Accuracy: 0.9383886255924171
On the test set:
Accuracy: 0.93此時增加L2正則化後,訓練集和測試集的預測精度分別是93.8%和93%
plt.title("Model with L2-regularization")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x : predict_dec(parameters, x.T),train_X, train_Y)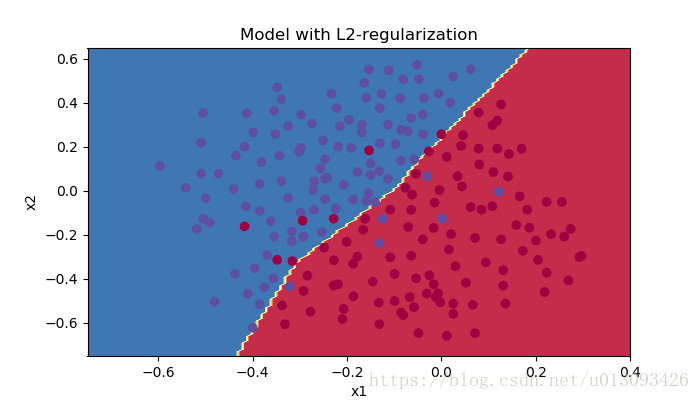
過擬合現象大大改善。
五、dropout模型
dropout的基本原理在每層網路上隨即的讓一些神經元失活,這樣使得網路模型更加簡化,可以改善過擬合現象。dropout作用的網路層通常是W比較複雜的,對於只有少數神經元的層次則不需要作用。增加dropout演算法後,前向傳播和反向傳播的過程都會受到影響。
(1)前向傳播
def forward_propagation_with_dropout(X, parameters, keep_prob=0.5):
np.random.seed(1)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
Z1 = np.dot(W1,X) + b1
A1 = relu(Z1)
D1 = np.random.rand(A1.shape[0], A1.shape[1])
D1 = D1 < keep_prob
A1 = A1 * D1
A1 = A1 / keep_prob
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
D2 = np.random.rand(A2.shape[0], A2.shape[1])
D2 = D2 < keep_prob
A2 = A2 * D2
A2 = A2 / keep_prob
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache(2)反向傳播
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1. / m * np.dot(dZ3, A2.T)
db3 = 1./ m * np.sum(dZ3, axis = 1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
dA2 = dA2 * D2
dA2 = dA2 / keep_prob
dZ2 = np.multiply(dA2, np.int64(A2>0))
dW2 = 1. / m * np.dot(dZ2, A1.T)
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
dA1 = dA1 * D1
dA1 = dA1 / keep_prob
dZ1 = np.multiply(dA1, np.int64(A1>0))
dW1 = 1. / m * np.dot(dZ1, X.T)
db1 = 1. / m * np.sum(dZ1, axis = 1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients我們給定Keep_prob為0.86,即以24%的概率失活各層神經元,呼叫模型如下
parameters = model(train_X, train_Y, keep_prob = 0.86, )
print("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)cost after iterations 0:0.6543912405149825
cost after iterations 10000:0.0610169865749056
cost after iterations 20000:0.060582435798513114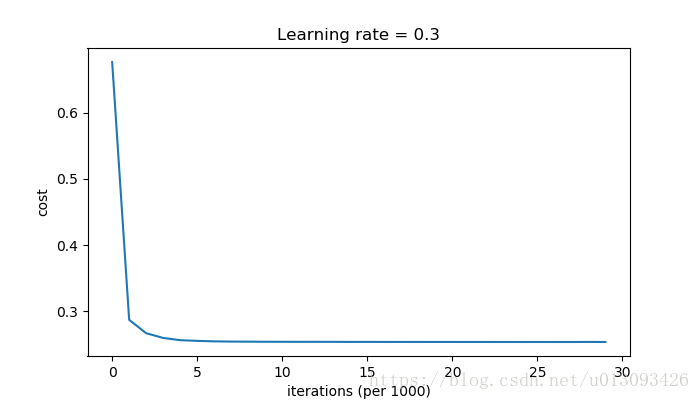
On the train set:
Accuracy: 0.9289099526066351
On the test set:
Accuracy: 0.95該方法在訓練集和測試集上的預測精度分別是92.89%和95,在訓練集上的預測效果更有,過擬合問題得到了很好的解決。
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75,0.40])
axes.set_ylim([-0.75,0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)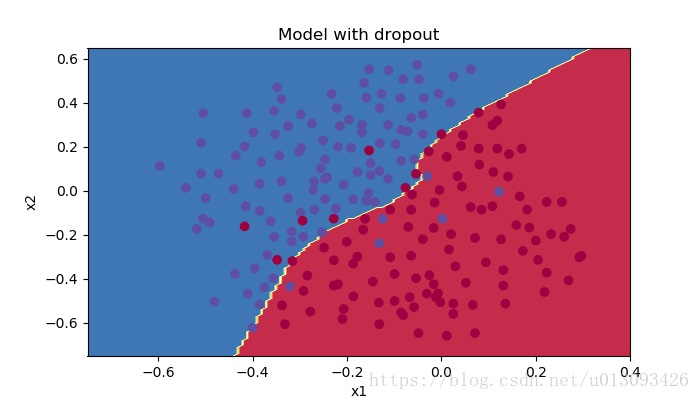
六、總結
正則化可以很好的解決模型過擬合的問題,常見的正則化方式有L2正則化和dropout,但是正則化是以犧牲模型的擬合能力來達到平衡的,因此在對訓練集的擬閤中有所損失。
相關推薦
正則化對深層神經網路的影響分析
本文是基於吳恩達老師《深度學習》第二週第一課練習題所做,目的在於探究引數初始化對模型精度的影響。一、資料處理本文所用第三方庫如下,其中reg_utils 和 testCases_regularization為輔助程式從這裡下載。import numpy as np impor
【GAN ZOO閱讀】模式正則化的生成對抗網路 MODE REGULARIZED GENERATIVE ADVERSARIAL NETWORKS
原文地址: https://arxiv.org/abs/1612.02136 引用之請註明出處。 Tong Che 1,Yanran Li 2 3,Athul Paul Jacob 1,Yoshua Bengio 1,Wenjie Li 2 1 蒙特利爾學習演算法
改善深層神經網路:超引數除錯、正則化以及優化_課程筆記_第一、二、三週
所插入圖片仍然來源於吳恩達老師相關視訊課件。仍然記錄一下一些讓自己思考和關注的地方。 第一週 訓練集與正則化 這周的主要內容為如何配置訓練集、驗證集和測試集;如何處理偏差與方差;降低方差的方法(增加資料量、正則化:L2、dropout等);提升訓練速度的方法:歸一化訓練集;如何合理的初始化權
吳恩達改善深層神經網路引數:超引數除錯、正則化以及優化——優化演算法
機器學習的應用是一個高度依賴經驗的過程,伴隨著大量的迭代過程,你需要訓練大量的模型才能找到合適的那個,優化演算法能夠幫助你快速訓練模型。 難點:機器學習沒有在大資料發揮最大的作用,我們可以利用巨大的資料集來訓練網路,但是在大資料下訓練網路速度很慢; 使用快速的優化演算法大大提高效率
改善深層神經網路:超引數除錯、正則化以及優化 優化演算法 第二週
改善深層神經網路:超引數除錯、正則化以及優化 優化演算法 第二課 1. Mini-batch Batch vs Mini-batch gradient descent Batch就是將所有的訓練資料都放到網路裡面進行訓練,計算量大,硬體要求高。一次訓練只能得到一個梯
吳恩達 改善深層神經網路:超引數除錯、正則化以及優化 第一週
吳恩達 改善深層神經網路:超引數除錯、正則化以及優化 課程筆記 第一週 深度學習裡面的實用層面 1.1 測試集/訓練集/開發集 原始的機器學習裡面訓練集,測試集和開發集一般按照6:2:2的比例來進行劃分。但是傳統的機器學習
改善深層神經網路——超引數除錯、Batch正則化和程式框架(7)
目錄 1.超引數除錯 深度神經網路需要除錯的超引數(Hyperparameters)較多,包括: α:學習因子 β:動量梯度下降因子 :Adam演算法引數 #layers:神經網路層數
【deeplearning.ai】第二門課:提升深層神經網路——正則化的程式設計作業
正則化的程式設計作業,包括無正則化情況、L2正則化、Dropout的程式設計實現,程式設計中用到的相關理論和公式請參考上一篇博文。 問題描述:原問題是判斷足球運動員是否頭球,在此省略問題背景,其實就是二分類問題。有以下型別的資料,藍點為一類,紅點為一類 匯入需要的擴充套件包
吳恩達《深度學習-改善深層神經網路》3--超引數除錯、正則化以及優化
1. 系統組織超參除錯Tuning process1)深度神經網路的超參有學習速率、層數、隱藏層單元數、mini-batch大小、學習速率衰減、β(優化演算法)等。其重要性各不相同,按重要性分類的話: 第一類:最重要的引數就是學習速率α 第二類:隱藏層單元數、min
《吳恩達深度學習工程師系列課程之——改善深層神經網路:超引數除錯、正則化以及優化》學習筆記
本課程分為三週內容: 深度學習的使用層面 優化演算法 超引數除錯、Batch正則化和程式框架 WEEK1 深度學習的使用層面 1.建立神經網路時選擇: 神經網路層數 每層隱藏單元的個數 學習率為多少 各層採用的啟用函式為哪些 2
改善深層神經網路第一週-Regularization(正則化)
RegularizationWelcome to the second assignment of this week. Deep Learning models have so much flexibility and capacity that overfitting c
吳恩達deeplearning.ai課程《改善深層神經網路:超引數除錯、正則化以及優化》____學習筆記(第一週)
____tz_zs學習筆記第一週 深度學習的實用層面(Practical aspects of Deep Learning)我們將學習如何有效運作神經網路(超引數調優、如何構建資料以及如何確保優化演算法快速執行)設定ML應用(Setting up your ML applic
第2次課改善深層神經網路:超引數優化、正則化以及優化
1. 除錯處理 超引數重要性排序 學習速率(learning rate)α 動量權重β=0.9,隱藏層節點數,mini-batch size 層數,learning rate decay Adam優化演算法的引數β1=0.9,β2=0.999,ϵ=10
深層神經網路引數初始化方式對訓練精度的影響
本文是基於吳恩達老師《深度學習》第二週第一課練習題所做,目的在於探究引數初始化對模型精度的影響。文中所用到的輔助程式在這裡。一、資料處理本文所用第三方庫如下,其中init_utils為輔助程式包含構建神經網路的函式。import numpy as np import matp
吳恩達deep learning筆記第二課 改善深層神經網路:超引數除錯、正則化以及優化
學習吳恩達DL.ai第二週視訊筆記。 1.深度學習實用層面 在訓練集和驗證集來自相同分佈的前提下,觀察訓練集的錯誤率和驗證集的錯誤率來判斷過擬合(high variance高方差)還是欠擬合(high bias高偏差). 比如訓練集錯誤率1%,驗證集11%則過擬合(
【機器學習】神經網路DNN的正則化
和普通的機器學習演算法一樣,DNN也會遇到過擬合的問題,需要考慮泛化,之前在【Keras】MLP多層感知機中提到了過擬合、欠擬合等處理方法的問題,正則化是常用的手段之一,這裡我們就對DNN的正則化方法做一個總結。 1. DNN的L1&L2正則化 想到正則化,我們首先想到的就是L1正則化和L2正則化
神經網路正則化方法
正則化方法:防止過擬合,提高泛化能力 在訓練資料不夠多時,或者overtraining時,常常會導致overfitting(過擬合)。其直觀的表現如下圖所示,隨著訓練過程的進行,模型複雜度增加,在training data上的error漸漸減小,但是在驗證集上的error卻
神經網路損失函式中的正則化項L1和L2
轉自:https://blog.csdn.net/dcrmg/article/details/80229189 神經網路中損失函式後一般會加一個額外的正則項L1或L2,也成為L1範數和L2範數。正則項可以看做是損失函式的懲罰項,用來對損失函式中的係數做一些限制
神經網路優化演算法二(正則化、滑動平均模型)
1、神經網路進一步優化——過擬合與正則化 過擬合,指的是當一個模型過為複雜後,它可以很好的“記憶”每一個訓練資料中隨機噪音的部分而忘了要去“學習”訓練資料中通用的趨勢。舉一個極端的例子,如果一個模型中的引數比訓練資料的總數還多,那麼只要訓練資料不衝突,這個模型完全可以記住所有訓練資料
3. DNN神經網路的正則化
1. DNN神經網路的前向傳播(FeedForward) 2. DNN神經網路的反向更新(BP) 3. DNN神經網路的正則化 1. 前言 和普通的機器學習演算法一樣,DNN也會遇到過擬合的問題,需要考慮泛化,這裡我們就對DNN的正則化方法做一個總結。 2. DNN的L1和L2正則化 想到正則化,