
Tensorflow實現簡單的影象分類器
阿新 • • 發佈:2019-02-09
一個簡單的Tensorflow圖片分類器,資料集是iris資料集。兩個指令碼premade_estimator.py分類器指令碼、iris_data.py處理資料的指令碼。
#iris_data.py 下載資料集,並且處理資料集
import pandas as pd
import tensorflow as tf
# iris資料集的下載URL
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
TEST_URL = "http://download.tensorflow.org/data/iris_test.csv" Premade_estimator.py指令碼分析如下
"""An Example of a DNNClassifier for the Iris dataset."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import tensorflow as tf
import iris_data
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', default=100, type=int, help='batch size')
parser.add_argument('--train_steps', default=1000, type=int,
help='number of training steps')
def main(argv):
args = parser.parse_args(argv[1:])
# Fetch the data
(train_x, train_y), (test_x, test_y) = iris_data.load_data()
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
# Build 2 hidden layer DNN with 10, 10 units respectively.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y,
args.batch_size),
steps=args.train_steps)
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y,
args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:iris_data.eval_input_fn(predict_x,
labels=None,
batch_size=args.batch_size))
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')
for pred_dict, expec in zip(predictions, expected):
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(iris_data.SPECIES[class_id],
100 * probability, expec))
if __name__ == '__main__':
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run(main)執行premade_estimator.py指令碼,可以得到如下的結果
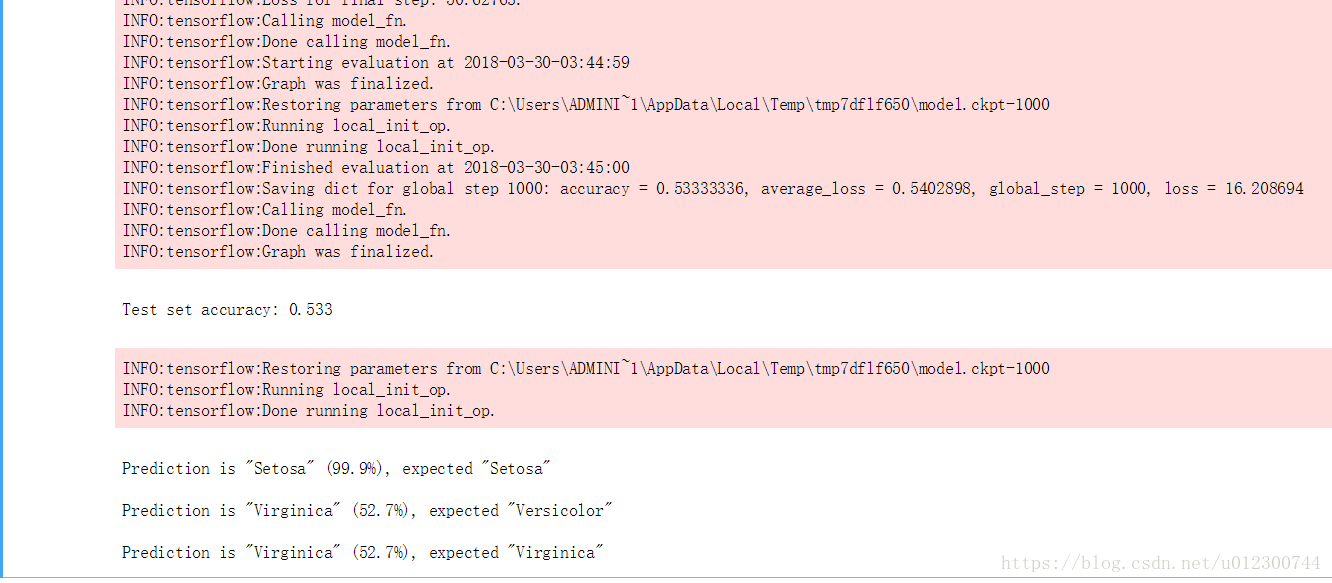
可以看出訓練出的模型對predict_x中的三種影象做出了很好的分類。