
【代價函式】MSE:均方誤差(L2 loss)
MSE均方誤差(L2 loss)
1.程式碼展示MAE和MSE圖片特性
import tensorflow as tf
import matplotlib.pyplot as plt
sess = tf.Session()
x_val = tf.linspace(-1.,-1.,500)
target = tf.constant(0.)
#計算L2_loss
l2_y_val = tf.square(target - x_val)
l2_y_out = sess.run(l2_y_val)#用這個函式開啟計算圖
#計算L1_loss
l1_y_val = tf.abs(target - x_val)
l1_y_out = sess.run(l1_y_val)#用這個函式開啟計算圖 
2.MSE公式及導數推導
損失函式:
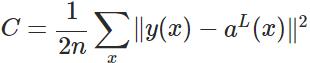
以單個樣本舉例:
 ,a=σ(z), where z=wx+b
,a=σ(z), where z=wx+b 利用SGD演算法優化損失函式,通過梯度下降法改變引數從而最小化損失函式:
對兩個引數權重和偏置進行求偏導(這個過程相對較容易):
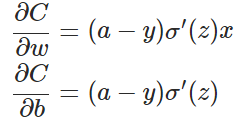
引數更新:
這邊就說一種簡單的更新策略(隨機梯度下降):

3.分析L2 Loss的特點
根據上面的損失函式對權重和偏置求導的公式我們發現:
其中,z表示神經元的輸入,σ表示啟用函式。從以上公式可以看出,w和b的梯度跟啟用函式的梯度成正比,啟用函式的梯度越大,w和b的大小調整得越快,訓練收斂得就越快。但是L2 Loss的這個特點存在的缺陷在於,對於我們常用的sigmoid啟用函式來說,並不是很符合我們的實際需求。
先介紹下sigmoid啟用函式的特性:
sigmoid函式就是損失函式的輸入:a=σ(z) 中的σ()的一種。這是一個啟用函式,該函式的公式,導數以及導數的分佈圖如下圖所示:


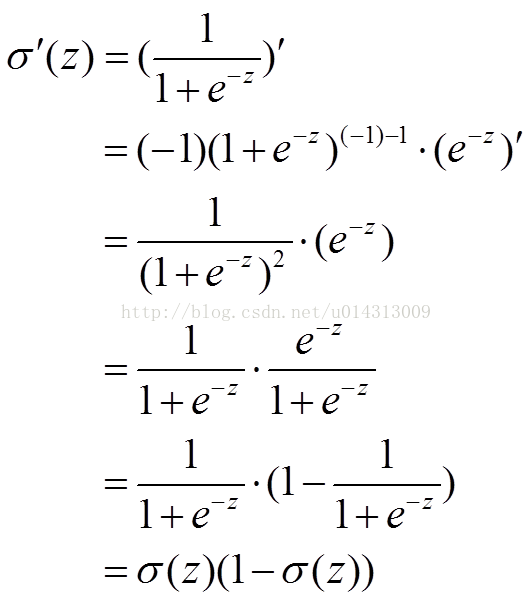

我們可以從sigmoid啟用函式的導數特性圖中發現,當啟用值很大的時候,sigmoid的梯度(就是曲線的斜率)會比較小,權重更新的步幅會比較小,這時候網路正處在誤差較大需要快速調整的階段,而上述特性會導致網路收斂的會比較慢;而當啟用值很小的時候,sigmoid的梯度會比較大,權重更新的步幅也會比較大,這時候網路的預測值正好在真實值的邊緣,太大的步幅也會導致網路的震盪。這我們的期望不符,即:不能像人一樣,錯誤越大,改正的幅度越大,從而學習得越快。而錯誤越小,改正的幅度小一點,從而穩定的越快。而交叉熵損失函式正好可以解決這個問題。
相關推薦
【代價函式】MSE:均方誤差(L2 loss)
MSE均方誤差(L2 loss) 1.程式碼展示MAE和MSE圖片特性 import tensorflow as tf import matplotlib.pyplot as plt sess = tf.Session() x_val = tf.li
迴歸評價指標:均方誤差根(RMSE)和R平方(R2)
做迴歸分析,常用的誤差主要有均方誤差根(RMSE)和R-平方(R2)。 RMSE是預測值與真實值的誤差平方根的均值。這種度量方法很流行(Netflix機器學習比賽的評價方法),是一種定量的權衡方法。 ””’ 均方誤差根 ”’ def rmse(y_te
均方誤差(MSE)根均方誤差(RMSE)平均絕對誤差(MAE)
MSE:Mean Squared Error. 均方誤差是指引數的估計值與引數的真實值之差的平方的期望. MSE可以評價資料的變化程度,MSE越小,說明模型的擬合實驗資料能力強. MSE=1
音訊噪聲抑制(4):普通最小均方誤差(LMS)演算法
引言前面講了基於Weiner濾波器的噪聲抑制方法。維納濾波器有一些假設條件,比如訊號平穩(這就導致解方程算濾波器係數的時候,自相關矩陣與絕對時間無關)、噪聲和有用訊號不相關…其實,這些條件在實際中並不是那麼容易滿足的。因此,用維納濾波器來實現訊號去噪,效果不是特別理想。於是就
均方誤差(MSE)
均方誤差(Mean Squared Error, MSE) 在相同測量條件下進行的測量稱為等精度測量,例如在同樣的條件下,用同一個遊標卡尺測量銅棒的直徑若干次,這就是等精度測量。對於等精度測量來說,還有一種更好的表示誤差的方法,就是標準誤差。 標準誤差定義為各測量值誤
神經網路經典損失函式-交叉熵和均方誤差
在神經網路中,如何判斷一個輸出向量和期望的向量有多接近呢?交叉熵(cross entropy)是常用的方法之一,刻畫了兩個概率分佈之間的距離,是分類問題中使用較多的一種損失函式。 給定兩個概率分佈p和q,通過q來表示p的交叉熵為: 如何將神經網路前向傳播
【HDU 5305】Friends 多校第二場(雙向DFS)
tor typedef type clu name article using ring eof 依據題意的話最多32條邊,直接暴力的話 2 ^ 32肯定超時了。我們能夠分兩次搜索時間復雜度降低為 2 * 2 ^ 16 唯一須要註意的就是對眼下狀態的哈希處理。 我採用
【蘿蔔學院】產品經理實戰訓練營課程(67課)完整版
產品經理 註意 pan 百度網盤 思考 洞察力 職場 修煉 為什麽 課程大致目錄:第1課時 產品經理入門自我修煉必備第2課時 產品6問第3課時 產品要關註的用戶體驗設計原則和能力第4課時 敏銳的洞察力及碎片時間的利用第5課時 日常生活的思考及分享從自己開始第6課時 市場分析
【敏捷開發】經驗構件庫-Java版(exp-libs)
完整原文(含原始碼):http://exp-blog.com/2018/09/22/pid-2382/ (轉載請註明出處,僅供分享學習,嚴禁用於商業用途) 環境 簡介 此構件庫為本人多年程式設計總結提煉而成,把常用的功能模組作為原子API
【遊戲開發】directx遊戲專案——第一部分(未完)
目的: 編寫啟動渲染系統的程式碼,用於初始化Direct3D,將螢幕清屏為指定的顏色以及關閉系統。 main.h標頭檔案 //main.h #ifndef _UGP_MAIN_H_ #define _UGP_MAIN_H_ #include "StrandedE
【資料結構】鏈式棧的實現(C語言)
棧的鏈式儲存稱為鏈式棧,鏈式棧是一種特殊的單鏈表,它的插入和刪除規定在單鏈表的同一端進行。鏈式棧的棧頂指標一般用top表示。(個人理解:相當於只對單鏈表的第一個結點進行操作) 鏈式棧要掌握以下基本操作: 1、建立一個空鏈式棧 2、判斷鏈式棧是否為空 3、讀鏈式棧的
【JavaScript高階】1、基礎總結深入(資料型別)
一、資料型別 1. 資料型別分類 * 基本(值)型別 * String: 任意字串 * Number: 任意的數字 * boolean: true/false
【程式設計3】二叉樹遍歷(LeetCode.102)
文章目錄 一、二叉樹的層次遍歷 1、題目描述——LeetCode.102 2、分析 3、實現 二、二叉樹(Binary Tree) 1、相關概念
【程式設計2】單鏈表+單鏈表反轉(LeetCode. 206)
文章目錄 一、連結串列 二、單鏈表 1、基本概念 (1)單鏈表 (2)頭指標——必有元素 (3)頭結點——非必需元素 (4)尾結點 2、查詢操作
【CSS筆記】— 使用calc()計算寬高(vm/vh)
【CSS筆記】— 使用calc()計算寬高(vm/vh) calc()是什麼? 簡單來說就是CSS3中新增的一個函式,calculate(計算)的縮寫。用於動態計算寬/高,你可以使用calc()給元素的各個屬性設定值【margin、border、padding、font-size】等, calc()語法
【解決辦法】pandas畫出時序資料(股票資料)橫軸不是時間
簡述 遇到了這個問題,被坑了很久。 首先我們要假設我們一直認為index是時間資料。然後我們發現沒有看到橫軸為時間 (如果不是的這麼認為的話,就記得先把index設定為時間資料) 可能性 遇到這個問題有很多種可能。 讀取的時候,時間所在的列沒有被設定為inde
【自學筆記】0基礎自學機器學習 (第一天)
--概述-- 2016年,阿爾法狗大戰李世石引起軒然大波,題主得知之後,感覺非常酷炫,於是開始關注各種人工智慧的新聞,如車聯網,無人駕駛,智慧推薦,智慧醫療等相關內容,但是苦於沒時間去學習,一直沒能觸及。這次,有大量的時間,我覺得要有所行動了。挑戰
【自學筆記】0基礎自學機器學習 (第二天)
定義:機器學習是人工智慧的一個分支領域,主要關於構造和研究可以從資料中學習的系統。 小不忍則亂大謀,不可急功近利,工欲善其事,必先利其器,得能吃苦。 &
【Android開發】wifi開關與wifi連線(密碼連線)
過放蕩不羈的生活,容易得像順水推舟,但是要結識良朋益友,卻難如登天。—— 巴爾扎克 本文demo來自網路,找了好久找到的,後面自己做了些許修改,這裡對原始碼解析,愧於忘記哪裡出來了,感謝作者! 接下來就記錄一下wifi開發的一些學習心得,這邊先看幾張效果圖吧!
【CCF CSP】 201412-2 Z字形掃描(100分)
試題編號:201412-2 試題名稱:Z字形掃描 時間限制:2.0s 記憶體限制:256.0MB 問題描述:問題描述 在影象編碼的演算法中,需要將一