
壓縮感知重構演算法之壓縮取樣匹配追蹤(CoSaMP)
題目:壓縮感知重構演算法之壓縮取樣匹配追蹤(CoSaMP)
壓縮取樣匹配追蹤(CompressiveSampling MP)是D. Needell繼ROMP之後提出的又一個具有較大影響力的重構演算法。CoSaMP也是對OMP的一種改進,每次迭代選擇多個原子,除了原子的選擇標準之外,它有一點不同於ROMP:ROMP每次迭代已經選擇的原子會一直保留,而CoSaMP每次迭代選擇的原子在下次迭代中可能會被拋棄。
0、符號說明如下:
壓縮觀測y=Φx,其中y為觀測所得向量M×1,x為原訊號N×1(M<<N)。x一般不是稀疏的,但在某個變換域Ψ是稀疏的,即x=Ψθ,其中θ為K稀疏的,即θ
(1) y為觀測所得向量,大小為M×1
(2)x為原訊號,大小為N×1
(3)θ為K稀疏的,是訊號在x在某變換域的稀疏表示
(4) Φ稱為觀測矩陣、測量矩陣、測量基,大小為M×N
(5) Ψ稱為變換矩陣、變換基、稀疏矩陣、稀疏基、正交基字典矩陣,大小為N×N
(6)A稱為測度矩陣、感測矩陣、CS資訊運算元,大小為M×N
上式中,一般有K<<M<<N,後面三個矩陣各個文獻的叫法不一,以後我將Φ稱為測量矩陣、將Ψ稱為稀疏矩陣
注意:這裡的稀疏表示模型為x=Ψθ,所以感測矩陣A=ΦΨ;而有些文獻中稀疏模型為θ=Ψx,而一般Ψ為Hermite矩陣(實矩陣時稱為正交矩陣),所以Ψ-1=ΨH (實矩陣時為Ψ-1=ΨT),即x=ΨHθ,所以感測矩陣A=ΦΨH,例如沙威的OMP例程中就是如此。
1、CoSaMP重構演算法流程:


2、壓縮取樣匹配追蹤(CoSaOMP)Matlab程式碼(CS_CoSaMP.m)
程式碼參考了文獻[5]中的Demo_CS_CoSaMP.m,也可參考文獻[6],或者文獻[7]中的cosamp.m。值得一提的是文獻[5]的所有程式碼都挺不錯的,從程式碼註釋中可以得知作者是ustc的ChengfuHuo,百度一下可知是中國科技大學的霍承富博士,已於2012年6月畢業,博士論文題目是《超光譜遙感影象壓縮技術研究》,向這位學長致敬!(雖然不是一個學校的)
2015-05-13更新:
function [ theta ] = CS_CoSaMP( y,A,K )
%CS_CoSaOMP Summary of this function goes here
%Created by [email protected]@2015-04-29
%Version: 1.1 modified by jbb0523 @2015-05-09
% Detailed explanation goes here
% y = Phi * x
% x = Psi * theta
% y = Phi*Psi * theta
% 令 A = Phi*Psi, 則y=A*theta
% K is the sparsity level
% 現在已知y和A,求theta
% Reference:Needell D,Tropp J A.CoSaMP:Iterative signal recovery from
% incomplete and inaccurate samples[J].Applied and Computation Harmonic
% Analysis,2009,26:301-321.
[y_rows,y_columns] = size(y);
if y_rows<y_columns
y = y';%y should be a column vector
end
[M,N] = size(A);%感測矩陣A為M*N矩陣
theta = zeros(N,1);%用來儲存恢復的theta(列向量)
Pos_theta = [];%用來迭代過程中儲存A被選擇的列序號
r_n = y;%初始化殘差(residual)為y
for kk=1:K%最多迭代K次
%(1) Identification
product = A'*r_n;%感測矩陣A各列與殘差的內積
[val,pos]=sort(abs(product),'descend');
Js = pos(1:2*K);%選出內積值最大的2K列
%(2) Support Merger
Is = union(Pos_theta,Js);%Pos_theta與Js並集
%(3) Estimation
%At的行數要大於列數,此為最小二乘的基礎(列線性無關)
if length(Is)<=M
At = A(:,Is);%將A的這幾列組成矩陣At
else%At的列數大於行數,列必為線性相關的,At'*At將不可逆
if kk == 1
theta_ls = 0;
end
break;%跳出for迴圈
end
%y=At*theta,以下求theta的最小二乘解(Least Square)
theta_ls = (At'*At)^(-1)*At'*y;%最小二乘解
%(4) Pruning
[val,pos]=sort(abs(theta_ls),'descend');
%(5) Sample Update
Pos_theta = Is(pos(1:K));
theta_ls = theta_ls(pos(1:K));
%At(:,pos(1:K))*theta_ls是y在At(:,pos(1:K))列空間上的正交投影
r_n = y - At(:,pos(1:K))*theta_ls;%更新殘差
if norm(r_n)<1e-6%Repeat the steps until r=0
break;%跳出for迴圈
end
end
theta(Pos_theta)=theta_ls;%恢復出的theta
endfunction [ theta ] = CS_CoSaMP( y,A,K )
%CS_CoSaMP Summary of this function goes here
%Version: 1.0 written by jbb0523 @2015-04-29
% Detailed explanation goes here
% y = Phi * x
% x = Psi * theta
% y = Phi*Psi * theta
% 令 A = Phi*Psi, 則y=A*theta
% K is the sparsity level
% 現在已知y和A,求theta
% Reference:Needell D,Tropp J A.CoSaMP:Iterative signal recovery from
% incomplete and inaccurate samples[J].Applied and Computation Harmonic
% Analysis,2009,26:301-321.
[y_rows,y_columns] = size(y);
if y_rows<y_columns
y = y';%y should be a column vector
end
[M,N] = size(A);%感測矩陣A為M*N矩陣
theta = zeros(N,1);%用來儲存恢復的theta(列向量)
Pos_theta = [];%用來迭代過程中儲存A被選擇的列序號
r_n = y;%初始化殘差(residual)為y
for kk=1:K%最多迭代K次
%(1) Identification
product = A'*r_n;%感測矩陣A各列與殘差的內積
[val,pos]=sort(abs(product),'descend');
Js = pos(1:2*K);%選出內積值最大的2K列
%(2) Support Merger
Is = union(Pos_theta,Js);%Pos_theta與Js並集
%(3) Estimation
%At的行數要大於列數,此為最小二乘的基礎(列線性無關)
if length(Is)<=M
At = A(:,Is);%將A的這幾列組成矩陣At
else%At的列數大於行數,列必為線性相關的,At'*At將不可逆
break;%跳出for迴圈
end
%y=At*theta,以下求theta的最小二乘解(Least Square)
theta_ls = (At'*At)^(-1)*At'*y;%最小二乘解
%(4) Pruning
[val,pos]=sort(abs(theta_ls),'descend');
%(5) Sample Update
Pos_theta = Is(pos(1:K));
theta_ls = theta_ls(pos(1:K));
%At(:,pos(1:K))*theta_ls是y在At(:,pos(1:K))列空間上的正交投影
r_n = y - At(:,pos(1:K))*theta_ls;%更新殘差
if norm(r_n)<1e-6%Repeat the steps until r=0
break;%跳出for迴圈
end
end
theta(Pos_theta)=theta_ls;%恢復出的theta
end在程式主迴圈的(3)Estimation部分增加了以下幾行程式碼,以使函式執行更加穩定:
if kk == 1
theta_ls = 0;
end3、CoSaMP單次重構測試程式碼
以下測試程式碼基本與OMP單次重構測試程式碼一樣。
%壓縮感知重構演算法測試
clear all;close all;clc;
M = 64;%觀測值個數
N = 256;%訊號x的長度
K = 12;%訊號x的稀疏度
Index_K = randperm(N);
x = zeros(N,1);
x(Index_K(1:K)) = 5*randn(K,1);%x為K稀疏的,且位置是隨機的
Psi = eye(N);%x本身是稀疏的,定義稀疏矩陣為單位陣x=Psi*theta
Phi = randn(M,N);%測量矩陣為高斯矩陣
A = Phi * Psi;%感測矩陣
y = Phi * x;%得到觀測向量y
%% 恢復重構訊號x
tic
theta = CS_CoSaMP( y,A,K );
x_r = Psi * theta;% x=Psi * theta
toc
%% 繪圖
figure;
plot(x_r,'k.-');%繪出x的恢復訊號
hold on;
plot(x,'r');%繪出原訊號x
hold off;
legend('Recovery','Original')
fprintf('\n恢復殘差:');
norm(x_r-x)%恢復殘差執行結果如下:(訊號為隨機生成,所以每次結果均不一樣)
1)圖:
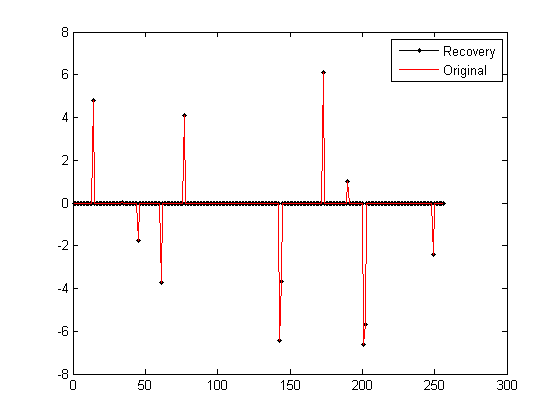
2)Command windows
Elapsedtime is 0.073375 seconds.
恢復殘差:
ans=
7.3248e-015
4、測量數M與重構成功概率關係曲線繪製例程程式碼
以下測試程式碼基本與OMP測量數M與重構成功概率關係曲線繪製程式碼一樣。增加了“fprintf('K=%d,M=%d\n',K,M);”,可以觀察程式執行進度。clear all;close all;clc;
%% 引數配置初始化
CNT = 1000;%對於每組(K,M,N),重複迭代次數
N = 256;%訊號x的長度
Psi = eye(N);%x本身是稀疏的,定義稀疏矩陣為單位陣x=Psi*theta
K_set = [4,12,20,28,36];%訊號x的稀疏度集合
Percentage = zeros(length(K_set),N);%儲存恢復成功概率
%% 主迴圈,遍歷每組(K,M,N)
tic
for kk = 1:length(K_set)
K = K_set(kk);%本次稀疏度
M_set = 2*K:5:N;%M沒必要全部遍歷,每隔5測試一個就可以了
PercentageK = zeros(1,length(M_set));%儲存此稀疏度K下不同M的恢復成功概率
for mm = 1:length(M_set)
M = M_set(mm);%本次觀測值個數
fprintf('K=%d,M=%d\n',K,M);
P = 0;
for cnt = 1:CNT %每個觀測值個數均執行CNT次
Index_K = randperm(N);
x = zeros(N,1);
x(Index_K(1:K)) = 5*randn(K,1);%x為K稀疏的,且位置是隨機的
Phi = randn(M,N)/sqrt(M);%測量矩陣為高斯矩陣
A = Phi * Psi;%感測矩陣
y = Phi * x;%得到觀測向量y
theta = CS_CoSaMP(y,A,K);%恢復重構訊號theta
x_r = Psi * theta;% x=Psi * theta
if norm(x_r-x)<1e-6%如果殘差小於1e-6則認為恢復成功
P = P + 1;
end
end
PercentageK(mm) = P/CNT*100;%計算恢復概率
end
Percentage(kk,1:length(M_set)) = PercentageK;
end
toc
save CoSaMPMtoPercentage1000 %執行一次不容易,把變數全部儲存下來
%% 繪圖
S = ['-ks';'-ko';'-kd';'-kv';'-k*'];
figure;
for kk = 1:length(K_set)
K = K_set(kk);
M_set = 2*K:5:N;
L_Mset = length(M_set);
plot(M_set,Percentage(kk,1:L_Mset),S(kk,:));%繪出x的恢復訊號
hold on;
end本程式在聯想ThinkPadE430C筆記本(4GBDDR3記憶體,i5-3210)上執行共耗時1102.325890秒,程式中將所有資料均通過“save CoSaMPMtoPercentage1000”儲存了下來,以後可以再對資料進行分析,只需“load CoSaMPMtoPercentage1000”即可。
本程式執行結果:
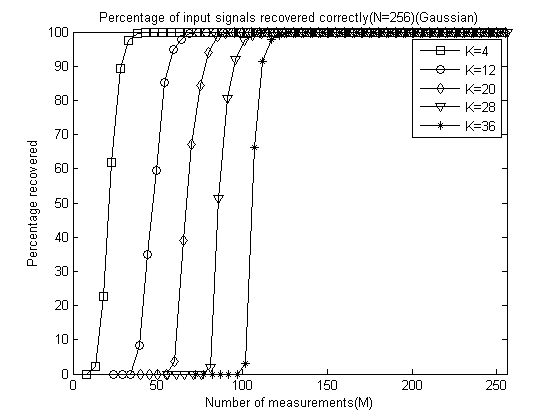
5、結語
有關CoSaMP的原始引用文獻共有四個版本,分別如參考文獻[1][2][3][4],可依據連結下載,其中[1]和[2]基本一致,本人主要看的是文獻[2]。
有關CoSaMP的演算法流程,可參見參考文獻[2]:

這個流程中的其它部分都可以看懂,就是那句“b|Tc←0”很不明白,“Tc”到底是指的什麼呢?現在看來應該是T的補集(complementary set),向量b的元素序號為全集,子集T對應的元素等於最小二乘解,補集對應的元素為零。
有關演算法流程中的“注3”提到的迭代次數,在文獻[2]中多處有提及,不過面向的問題不同,可以文獻[2]中搜索“Iteration Count”,以下給出三處:
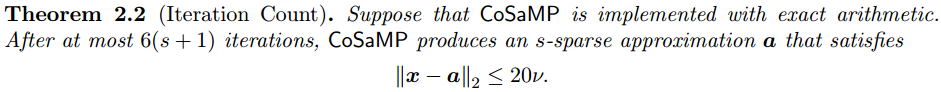
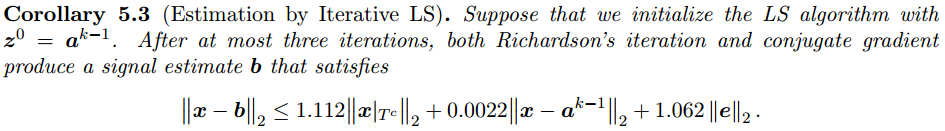
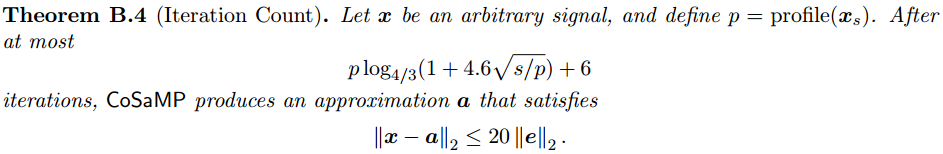
文獻[8]的3.4節提到“設演算法的迭代步長為K,候選集中最多有3K個原子,每次最多剔除K個原子,以保證支撐集中有2K個原子”,對這個觀點我保留意見,我認為應該是“每次最多剔除2K個原子,以保證支撐集中有K個原子”。
參考文獻:
[1]D. Needell, J.A. Tropp, CoSaMP: Iterative signal recovery from incomplete andinaccurate samples, ACM Technical Report 2008-01, California Institute ofTechnology, Pasadena, 2008.
(http://authors.library.caltech.edu/27169/)
[2]D. Needell, J.A. Tropp.CoSaMP: Iterative signal recoveryfrom incomplete and inaccurate samples.http://arxiv.org/pdf/0803.2392v2.pdf
[3] D. Needell, J.A. Tropp.CoSaMP:Iterativesignal recovery from incomplete and inaccurate samples[J].Appliedand Computation Harmonic Analysis,2009,26:301-321.
(http://www.sciencedirect.com/science/article/pii/S1063520308000638)
[4]D.Needell, J.A. Tropp.CoSaMP: Iterative signal recoveryfrom incomplete and inaccurate samples[J]. Communications of theACM,2010,53(12):93-100.
(http://dl.acm.org/citation.cfm?id=1859229)
[5]Li Zeng. CS_Reconstruction.http://www.pudn.com/downloads518/sourcecode/math/detail2151378.html
[6]wanghui.csmp. http://www.pudn.com/downloads252/sourcecode/others/detail1168584.html
[7]付自傑.cs_matlab. http://www.pudn.com/downloads641/sourcecode/math/detail2595379.html
[8]楊真真,楊震,孫林慧.訊號壓縮重構的正交匹配追蹤類演算法綜述[J]. 訊號處理,2013,29(4):486-496.
相關推薦
壓縮感知重構演算法之壓縮取樣匹配追蹤(CoSaMP)
題目:壓縮感知重構演算法之壓縮取樣匹配追蹤(CoSaMP) 壓縮取樣匹配追蹤(CompressiveSampling MP)是D. Needell繼ROMP之後提出的又一個具有較大影響力的重構演算法。CoSaMP也是對OMP的一種改進,每次迭代選擇多個原子,除了原子的選擇
壓縮感知重構演算法之IRLS演算法python實現
IRLS(iteratively reweighted least squares)演算法 (本文給出的程式碼未進行優化,只是為了說明演算法流程 ,所以執行速度不是很快) IRLS(iteratively reweighted least squar
壓縮感知重構演算法之OLS演算法python實現
Orthogonal Least Squares (OLS)演算法流程 實驗 要利用python實現,電腦必須安裝以下程式 python (本文用的python版本為3.5.1) numpy python包(本文用
壓縮感知重構演算法之OMP演算法python實現
本文主要簡單介紹了利用python程式碼實現壓縮感知的過程。 壓縮感知簡介 【具體可以參考這篇文章】 假設一維訊號x長度為N,稀疏度為K。Φ 為大小M×N矩陣(M<<N)。y=Φ×x為長度M的一維測量值。壓縮感知問題就是已知測量值y和測
壓縮感知重構演算法之CoSaMP演算法python實現
演算法流程 演算法分析 python程式碼 要利用python實現,電腦必須安裝以下程式 python (本文用的python版本為3.5.1) numpy python包(本文用的版本為1.10.4) scipy python
[轉]壓縮感知重構算法之分段正交匹配追蹤(StOMP)
參數配置 組成 jaf second red [1] figure nor 拉伸 分段正交匹配追蹤(StagewiseOMP)或者翻譯為逐步正交匹配追蹤,它是OMP另一種改進算法,每次叠代可以選擇多個原子。此算法的輸入參數中沒有信號稀疏度K,因此相比於ROMP及CoSaMP
深度學習模型壓縮與加速演算法之SqueezeNet和ShuffleNet
自從AlexNet一舉奪得ILSVRC 2012 ImageNet影象分類競賽的冠軍後,卷積神經網路(CNN)的熱潮便席捲了整個計算機視覺領域。CNN模型火速替代了傳統人工設計(hand-crafted)特徵和分類器,不僅提供了一種端到端的處理方法,還大幅度地重新整理了各個影
壓縮感知測量矩陣之有限等距性質(Restricted Isometry Property, RIP)
題目:壓縮感知測量矩陣之有限等距性質(Restricted Isometry Property,RIP) 閱讀壓縮感知的文獻,RIP絕對是一個擡頭不見低頭見的英文簡寫,也就是有限等距
資料結構與演算法之美-字串匹配(上)
BF (Brute Force) 暴力/樸素匹配演算法 主串和模式串 我們在字串 A 中查詢字串 B,那字串 A 就是主串,字串 B 就是模式串。 我們把主串的長度記作 n,模式串的長度記作 m。因為我們是在主串中查詢模式串,所以 n>m。 BF演算法思想 在主串中,檢查起始位置分別
機器學習筆記(1) 感知機演算法 之 實戰篇
我們在上篇筆記中介紹了感知機的理論知識,討論了感知機的由來、工作原理、求解策略、收斂性。這篇筆記中,我們親自動手寫程式碼,使用感知機演算法解決實際問題。 先從一個最簡單的問題開始,用感知機演算法解決OR邏輯的分類。 import numpy as np import matplotlib.pyplot as
視頻編碼技術---壓縮感知編碼---匹配跟蹤算法
tro 三維空間 編碼 步驟 時間 理解 最大 理論 一個 轉自https://blog.csdn.net/rainbow0210/article/details/53386695 壓縮感知近些年在學術界非常火熱,在信號處理領域取得了很多非常不錯的成果。 博主最近的項目涉及
形象易懂講解演算法II——壓縮感知
作者:咚懂咚懂咚 連結:https://zhuanlan.zhihu.com/p/22445302 來源:知乎 著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。 之前曾經寫過一篇關於小波變換的回答(能不能通俗的講解下傅立葉分析和小波分析之間的關係? - 咚懂咚懂咚的回答),得到很多贊,十分
取樣、過取樣和壓縮感知
連結:https://www.zhihu.com/question/20475750/answer/15249347,http://tiejunlab.com/viewthread.php?action=printable&tid=577 取樣定理是取樣過程
“魔術”重構:壓縮感知——"Magic" Reconstruction: Compressed Sensing
By Cleve Moler 評:本文是Mathworks 公司的首席科學家Cleve Moler寫的一個科普材料。這裡作者說明了採用L1規範是可以恢復原型號的,而採用L2規範則不可以恢復原型號。 When I first heard about co
程式設計師需要了解的硬核知識之壓縮演算法
此篇文章是《程式設計師需要了解的硬核知識》第五篇文章,歷史文章請戳 程式設計師需要了解的硬核知識之記憶體 程式設計師需要了解的硬核知識之CPU 程式設計師需要了解的硬核知識之二進位制 程式設計師需要了解的硬核知識之磁碟 之前的文章更多的介紹了計算機的硬體知識,會有一些難度,本篇文章的門檻會低一些,一起來看一下
【Redis源代碼剖析】 - Redis內置數據結構之壓縮字典zipmap
ordering struct 包裝 字符串長度 哈希 append 解決 註意 指針 原創作品,轉載請標明:http://blog.csdn.net/Xiejingfa/article/details/51111230 今天為大家帶來Redis中zi
+++++++btrfs、壓縮/解壓縮和編程之if和for總結
linuxbtrfsfilesystem device balance subvolume創建、掛載、子卷的掛載、創建、向btrfs中添加或移除設備、重新均衡數據<btrfs系統不支持,網上摘錄,以後再修改....>1、父卷可直接格式化、掛載及同LVM邏輯卷一樣可以動態的擴展和縮減2、原生RAID
Linux命令之壓縮
linux gzip bzip2 壓縮1.壓縮的概念1)壓縮的目的在網絡傳遞文件時,可以先將文件壓縮,然後傳遞壓縮後的文件,從而減少網絡帶寬接收者接受文件後,解壓即可2)壓縮的類型有損壓縮和無損壓縮a)有損壓縮如MP4視頻文件,即使壓縮過程中減少了很多幀數據,對觀看者而言也沒有影響。當然MP
gulp教程之壓縮合並css,js
配置 分享 ava png 命令行 end 文件名 所有 gulp package.json如果你熟悉 npm 則可以利用 package.json 保存所有 npm install --save-dev gulp-xxx 模塊依賴和模塊版本。在命令行輸入 npm ini
(十三)Centos之壓縮和解壓縮
tar.bz2 lsd 文件 例如 src zip2 anaconda 我們 system 一、常用壓縮格式 常用壓縮格式:.zip .gz .bz2 常用壓縮格式:.tar.gz .tar.bz2 二、zip格式壓縮 壓縮文件:zip壓縮文件名 源文件 壓縮目錄: