
【膜拜大神】Tensorflow實現YOLO v3(TF-Slim)
最近我一直在使用Tensorflow中的YOLO v3。我在GitHub上找不到任何適合我需要的實現,因此我決定將這個用PyTorch編寫的程式碼轉換為Tensorflow。與論文一起釋出的YOLO v3的原始配置可以在Darknet GitHub repo中找到。
我想分享我的程式碼,以及我在實現它時遇到的一些問題的解決方案。
我不會過分關注與實施無關的方面。我假設您熟悉CNN,目標檢測,YOLO v3架構等以及Tensorflow和TF-Slim框架。如果沒有,最好從相應的論文/教程開始。我不會解釋每一行的作用,而是提供工作程式碼,並解釋我偶然發現的一些問題。
我的測試環境:Ubuntu 16.04,Tensorflow 1.8.0和CUDA 9.0。
檢視tensorflow版本:

這篇文章的組織結構如下:
1. 配置
2. Darknet-53層的實現
3. 實施YOLO v3檢測層
4. 轉換預先訓練的COCO權重
5. 後處理演算法的實現
6. 總結
1. setup
我想以類似於Tensorflow模型庫中的組織方式來組織程式碼。 我使用TF-Slim,因為它讓我們將諸如啟用函式,批量標準化引數等常見引數定義為全域性變數,從而使得定義神經網路的速度更快。
我們從yolo_v3.py檔案開始,檔案中含有初始化網路的函式以及載入預先訓練的權重的函式。
在檔案頂部的某處新增必要的常量:
_BATCH_NORM_DECAY = 0.9
_BATCH_NORM_EPSILON = 1e-05
_LEAKY_RELU = 0.1YOLO v3將輸入歸一化為0-1。 檢測器中的大多數層在卷積後立即進行batch normalization,使用Leaky ReLU啟用,沒有偏置(biases)。 用slim 定義引數(arg)範圍來處理這種情況是很方便的。 在不使用BN和LReLU的層中,我們需要隱式定義它。
# transpose the inputs to NCHW if data_format == 'NCHW': inputs = tf.transpose(inputs, [0, 3, 1, 2]) # normalize values to range [0..1] inputs = inputs / 255 # set batch norm params batch_norm_params = { 'decay': _BATCH_NORM_DECAY, 'epsilon': _BATCH_NORM_EPSILON, 'scale': True, 'is_training': is_training, 'fused': None, # Use fused batch norm if possible. } # Set activation_fn and parameters for conv2d, batch_norm. with slim.arg_scope([slim.conv2d, slim.batch_norm, _fixed_padding], data_format=data_format, reuse=reuse): with slim.arg_scope([slim.conv2d], normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params, biases_initializer=None, activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU)): with tf.variable_scope('darknet-53'): inputs = darknet53(inputs)
2. Darknet-53的實現
在YOLO v3論文中,作者提出了一種名為Darknet-53的更深層次的特徵提取器架構。 顧名思義,它包含53個卷積層,每個卷後面都有BN層和Leaky ReLU啟用層。 下采樣由帶有stride = 2的conv層完成。
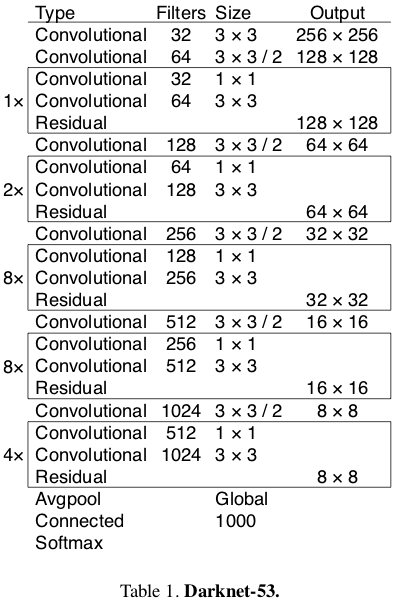
Source: YOLO v3 paper
在定義卷積層之前,我們必須認識到作者是使用固定填充(fixed padding)而不依賴於輸入大小來實現的。 為了實現相同的效果,我們可以使用下面的函式(我稍微修改了這裡的程式碼)。
@tf.contrib.framework.add_arg_scope
def _fixed_padding(inputs, kernel_size, *args, mode='CONSTANT', **kwargs):
"""
Pads the input along the spatial dimensions independently of input size.
Args:
inputs: A tensor of size [batch, channels, height_in, width_in] or
[batch, height_in, width_in, channels] depending on data_format.
kernel_size: The kernel to be used in the conv2d or max_pool2d operation.
Should be a positive integer.
data_format: The input format ('NHWC' or 'NCHW').
mode: The mode for tf.pad.
Returns:
A tensor with the same format as the input with the data either intact
(if kernel_size == 1) or padded (if kernel_size > 1).
"""
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
if kwargs['data_format'] == 'NCHW':
padded_inputs = tf.pad(inputs, [[0, 0], [0, 0],
[pad_beg, pad_end], [pad_beg, pad_end]], mode=mode)
else:
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]], mode=mode)
return padded_inputs_fixed_padding pad沿高度和寬度尺寸輸入適當數量的0元素(當mode ='CONSTANT'時)。 我們稍後也會使用mode ='SYMMETRIC'。
現在我們可以定義_conv2d_fixed_padding函式:
def _conv2d_fixed_padding(inputs, filters, kernel_size, strides=1):
if strides > 1:
inputs = _fixed_padding(inputs, kernel_size)
inputs = slim.conv2d(inputs, filters, kernel_size, stride=strides, padding=('SAME' if strides == 1 else 'VALID'))
return inputsDarknet-53模型由一些塊構建,具有2個卷積層和shortcut connection,然後是下采樣層。 為避免樣板程式碼,我們定義了_darknet_block函式:
def _darknet53_block(inputs, filters):
shortcut = inputs
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = inputs + shortcut
return inputs最後,我們為Darknet-53模型提供了所有必需的構建塊:
def darknet53(inputs):
"""
Builds Darknet-53 model.
"""
inputs = _conv2d_fixed_padding(inputs, 32, 3)
inputs = _conv2d_fixed_padding(inputs, 64, 3, strides=2)
inputs = _darknet53_block(inputs, 32)
inputs = _conv2d_fixed_padding(inputs, 128, 3, strides=2)
for i in range(2):
inputs = _darknet53_block(inputs, 64)
inputs = _conv2d_fixed_padding(inputs, 256, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 128)
inputs = _conv2d_fixed_padding(inputs, 512, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 256)
inputs = _conv2d_fixed_padding(inputs, 1024, 3, strides=2)
for i in range(4):
inputs = _darknet53_block(inputs, 512)
return inputs最初,在最後一個塊之後有全域性平均池化層和softmax層,但YOLO v3均未使用(所以實際上我們有52層而不是53層;))
3. YOLO v3檢測層的實現
直接將Darknet-53提取的特徵輸入到檢測層中。 檢測模組由若干塊構成,每一塊都含有上取樣層、3個具有線性啟用功能的卷積層,從而在3種不同的尺度上進行檢測。 讓我們從編寫輔助函式_yolo_block開始:
def _yolo_block(inputs, filters):
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = _conv2d_fixed_padding(inputs, filters, 1)
route = inputs
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
return route, inputs然後,來自塊中第5層的啟用被轉到另一個卷積層,並進行上取樣,而來自第6層的啟用轉到_detection_layer,(這是我們接下來定義的):
def _detection_layer(inputs, num_classes, anchors, img_size, data_format):
num_anchors = len(anchors)
predictions = slim.conv2d(inputs, num_anchors * (5 + num_classes), 1, stride=1, normalizer_fn=None,
activation_fn=None, biases_initializer=tf.zeros_initializer())
shape = predictions.get_shape().as_list()
grid_size = _get_size(shape, data_format)
dim = grid_size[0] * grid_size[1]
bbox_attrs = 5 + num_classes
if data_format == 'NCHW':
predictions = tf.reshape(predictions, [-1, num_anchors * bbox_attrs, dim])
predictions = tf.transpose(predictions, [0, 2, 1])
predictions = tf.reshape(predictions, [-1, num_anchors * dim, bbox_attrs])
stride = (img_size[0] // grid_size[0], img_size[1] // grid_size[1])
anchors = [(a[0] / stride[0], a[1] / stride[1]) for a in anchors]
box_centers, box_sizes, confidence, classes = tf.split(predictions, [2, 2, 1, num_classes], axis=-1)
box_centers = tf.nn.sigmoid(box_centers)
confidence = tf.nn.sigmoid(confidence)
grid_x = tf.range(grid_size[0], dtype=tf.float32)
grid_y = tf.range(grid_size[1], dtype=tf.float32)
a, b = tf.meshgrid(grid_x, grid_y)
x_offset = tf.reshape(a, (-1, 1))
y_offset = tf.reshape(b, (-1, 1))
x_y_offset = tf.concat([x_offset, y_offset], axis=-1)
x_y_offset = tf.reshape(tf.tile(x_y_offset, [1, num_anchors]), [1, -1, 2])
box_centers = box_centers + x_y_offset
box_centers = box_centers * stride
anchors = tf.tile(anchors, [dim, 1])
box_sizes = tf.exp(box_sizes) * anchors
box_sizes = box_sizes * stride
detections = tf.concat([box_centers, box_sizes, confidence], axis=-1)
classes = tf.nn.sigmoid(classes)
predictions = tf.concat([detections, classes], axis=-1)
return predictions該層根據以下等式完成原始預測。 因為不同尺度上的YOLO v3會檢測到不同大小和寬高比的物件,所以需要anchors引數,這是每個尺度的3個元組(高度,寬度)的列表。 需要為資料集定製anchors(在本教程中,我們將使用COCO資料集的anchors)。 只需在yolo_v3.py檔案的頂部新增此常量即可。
_ANCHORS = [(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373, 326)]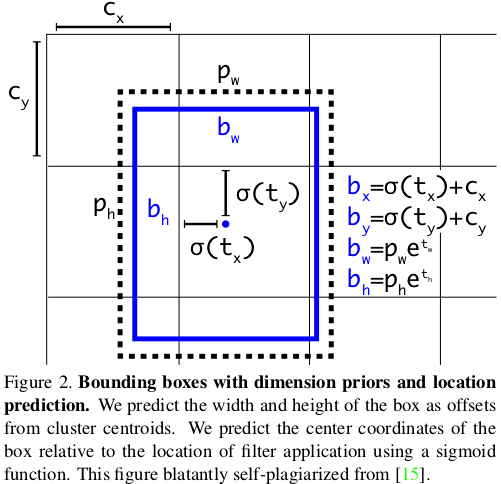
Source: YOLO v3 paper
我們需要一個輔助函式_get_size,它返回輸入的高度和寬度:
def _get_size(shape, data_format):
if len(shape) == 4:
shape = shape[1:]
return shape[1:3] if data_format == 'NCHW' else shape[0:2]如前所述,我們需要實現的YOLO v3最後一個構建塊是上取樣層。 YOLO探測器採用雙線性上取樣方法。 為什麼我們不能只使用Tensorflow API中的標準tf.image.resize_bilinear方法? 原因是,就今天(TF版本1.8.0)而言,所有上取樣方法都使用 constant填充模式。 YOLO作者repo和PyTorch中的標準pad方法是edge (可以在這裡找到填充模式的良好比較)。 這個微小的差異對檢測產生了重大影響(並且花了我幾個小時的除錯時間)。
為了解決這個問題,我們將手動填充1個畫素的輸入,設定mode ='SYMMETRIC',這相當於edge模式。
# we just need to pad with one pixel, so we set kernel_size = 3
inputs = _fixed_padding(inputs, 3, 'NHWC', mode='SYMMETRIC')整個_upsample函式程式碼如下所示:
def _upsample(inputs, out_shape, data_format='NCHW'):
# we need to pad with one pixel, so we set kernel_size = 3
inputs = _fixed_padding(inputs, 3, mode='SYMMETRIC')
# tf.image.resize_bilinear accepts input in format NHWC
if data_format == 'NCHW':
inputs = tf.transpose(inputs, [0, 2, 3, 1])
if data_format == 'NCHW':
height = out_shape[3]
width = out_shape[2]
else:
height = out_shape[2]
width = out_shape[1]
# we padded with 1 pixel from each side and upsample by factor of 2, so new dimensions will be
# greater by 4 pixels after interpolation
new_height = height + 4
new_width = width + 4
inputs = tf.image.resize_bilinear(inputs, (new_height, new_width))
# trim back to desired size
inputs = inputs[:, 2:-2, 2:-2, :]
# back to NCHW if needed
if data_format == 'NCHW':
inputs = tf.transpose(inputs, [0, 3, 1, 2])
inputs = tf.identity(inputs, name='upsampled')
return inputs更新:感謝Srikanth Vidapanakal,我檢查了darknet的原始碼,發現上取樣方法是最近鄰,而不是雙線性。 我們不再需要填充影象了。 已更新的程式碼已在我的repo中。
修改以後的_upsample函式程式碼如下所示:
def _upsample(inputs, out_shape, data_format='NCHW'):
# tf.image.resize_nearest_neighbor accepts input in format NHWC
if data_format == 'NCHW':
inputs = tf.transpose(inputs, [0, 2, 3, 1])
if data_format == 'NCHW':
new_height = out_shape[3]
new_width = out_shape[2]
else:
new_height = out_shape[2]
new_width = out_shape[1]
inputs = tf.image.resize_nearest_neighbor(inputs, (new_height, new_width))
# back to NCHW if needed
if data_format == 'NCHW':
inputs = tf.transpose(inputs, [0, 3, 1, 2])
inputs = tf.identity(inputs, name='upsampled')
return inputs上取樣啟用按通道軸連線來自Darknet-53的啟用。 這就是為什麼我們需要回到darknet53函式並在第4和第5個下采樣層之前,從conv層返回啟用。
def darknet53(inputs):
"""
Builds Darknet-53 model.
"""
inputs = _conv2d_fixed_padding(inputs, 32, 3)
inputs = _conv2d_fixed_padding(inputs, 64, 3, strides=2)
inputs = _darknet53_block(inputs, 32)
inputs = _conv2d_fixed_padding(inputs, 128, 3, strides=2)
for i in range(2):
inputs = _darknet53_block(inputs, 64)
inputs = _conv2d_fixed_padding(inputs, 256, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 128)
route1 = inputs
inputs = _conv2d_fixed_padding(inputs, 512, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 256)
route2 = inputs
inputs = _conv2d_fixed_padding(inputs, 1024, 3, strides=2)
for i in range(4):
inputs = _darknet53_block(inputs, 512)
return route1, route2, inputs現在我們準備定義檢測模組。 讓我們回到yolo_v3函式並在slim的arg範圍中新增以下行:
with tf.variable_scope('darknet-53'):
route_1, route_2, inputs = darknet53(inputs)
with tf.variable_scope('yolo-v3'):
route, inputs = _yolo_block(inputs, 512)
detect_1 = _detection_layer(inputs, num_classes, _ANCHORS[6:9], img_size, data_format)
detect_1 = tf.identity(detect_1, name='detect_1')
inputs = _conv2d_fixed_padding(route, 256, 1)
upsample_size = route_2.get_shape().as_list()
inputs = _upsample(inputs, upsample_size, data_format)
inputs = tf.concat([inputs, route_2], axis=1 if data_format == 'NCHW' else 3)
route, inputs = _yolo_block(inputs, 256)
detect_2 = _detection_layer(inputs, num_classes, _ANCHORS[3:6], img_size, data_format)
detect_2 = tf.identity(detect_2, name='detect_2')
inputs = _conv2d_fixed_padding(route, 128, 1)
upsample_size = route_1.get_shape().as_list()
inputs = _upsample(inputs, upsample_size, data_format)
inputs = tf.concat([inputs, route_1], axis=1 if data_format == 'NCHW' else 3)
_, inputs = _yolo_block(inputs, 128)
detect_3 = _detection_layer(inputs, num_classes, _ANCHORS[0:3], img_size, data_format)
detect_3 = tf.identity(detect_3, name='detect_3')
detections = tf.concat([detect_1, detect_2, detect_3], axis=1)
return detections4.轉換預訓練的權重(COCO)
我們定義了檢測器的架構。 要使用它,我們必須在自己的資料集上訓練或使用預訓練的權重。 在COCO資料集上預先訓練的權重可供公眾使用。 我們可以使用以下命令下載它:
wget https://pjreddie.com/media/files/yolov3.weights這個二進位制檔案的結構如下:
前5個int32值是頭(header)資訊:主要版本號,次要版本號,字版本號和網路在訓練期間看到的影象。在它們之後,有62 001 757個float32值,它們是每個卷積和BN層的權重。重要的是要記住它們按以行主(row-major )的格式進行儲存,這與Tensorflow以列為主(column-major)的格式相反。
那麼,我們應該如何從這個檔案中讀取權重?
我們從第一個卷積層開始。大多數卷積層緊接著是BN層。在這種情況下,我們首先需要讀取4 *num_filters個BN層的權重:gamma,beta,moving mean和moving variance,然後讀取kernel_size [0] * kernel_size [1] * num_filters * input_channels個conv層的權重。
在相反的情況下,當卷積層後面沒有BN層時,我們需要讀取num_filters個偏差權重,而不是讀取BN引數。
讓我們開始編寫load_weights函式的程式碼。它需要2個引數:圖表中的變數列表和二進位制檔案的名稱。
我們首先開啟檔案,跳過前5個int32值並以列表的形式讀取其他內容:
def load_weights(var_list, weights_file):
with open(weights_file, "rb") as fp:
_ = np.fromfile(fp, dtype=np.int32, count=5)
weights = np.fromfile(fp, dtype=np.float32)然後我們將使用兩個指標,第一個 var_list 遍歷迭代變數列表,第二個 weights 遍歷載入的變數權重列表。 我們需要檢查當前處理的層之後的層型別,並讀取適當數量的值。 在程式碼中,i 將迭代var_list,ptr 將迭代weights 。 我們將返回一份tf.assign操作列表。 我只是通過比較它的名稱來檢查層的型別。 (我同意它有點難看,但我不知道有什麼更好的方法。這種方法似乎對我有用。)
ptr = 0
i = 0
assign_ops = []
while i < len(var_list) - 1:
var1 = var_list[i]
var2 = var_list[i + 1]
# do something only if we process conv layer
if 'Conv' in var1.name.split('/')[-2]:
# check type of next layer
if 'BatchNorm' in var2.name.split('/')[-2]:
# load batch norm params
gamma, beta, mean, var = var_list[i + 1:i + 5]
batch_norm_vars = [beta, gamma, mean, var]
for var in batch_norm_vars:
shape = var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(var, var_weights, validate_shape=True))
# we move the pointer by 4, because we loaded 4 variables
i += 4
elif 'Conv' in var2.name.split('/')[-2]:
# load biases
bias = var2
bias_shape = bias.shape.as_list()
bias_params = np.prod(bias_shape)
bias_weights = weights[ptr:ptr + bias_params].reshape(bias_shape)
ptr += bias_params
assign_ops.append(tf.assign(bias, bias_weights, validate_shape=True))
# we loaded 2 variables
i += 1
# we can load weights of conv layer
shape = var1.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape((shape[3], shape[2], shape[0], shape[1]))
# remember to transpose to column-major
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(var1, var_weights, validate_shape=True))
i += 1
return assign_ops就是這樣! 現在我們可以通過執行以下程式碼來恢復模型的權重::
with tf.variable_scope('model'):
model = yolo_v3(inputs, 80)
model_vars = tf.global_variables(scope='model')
assign_ops = load_variables(model_vars, 'yolov3.weights')
sess = tf.Session()
sess.run(assign_ops)為了將來的使用,使用 tf.train.Saver 匯出權重並從檢查點載入可能要容易得多。
5.後處理演算法的實現
我們的模型返回一個下列形狀的張量:
batch_size x 10647 x (num_classes + 5 bounding box attrs)數字10647等於507 +2028 + 8112的和,它們是在每個刻度上檢測到的可能的物件數量。 描述邊界框屬性的5個值代表center_x,center_y,width,height。 在大多數情況下,更容易處理兩點的座標:左上角和右下角。 讓我們將檢測器的輸出轉換為這種格式。
這樣做的函式如下:
def detections_boxes(detections):
center_x, center_y, width, height, attrs = tf.split(detections, [1, 1, 1, 1, -1], axis=-1)
w2 = width / 2
h2 = height / 2
x0 = center_x - w2
y0 = center_y - h2
x1 = center_x + w2
y1 = center_y + h2
boxes = tf.concat([x0, y0, x1, y1], axis=-1)
detections = tf.concat([boxes, attrs], axis=-1)
return detections通常我們的檢測器會多次檢測到同一物體(中心和大小略有不同)。 在大多數情況下,我們不希望保留所有這些僅僅由少量畫素區分的檢測。 該問題的標準解決方案是非極大值抑制。 這裡可以很好地描述這種方法。
為什麼我們不使用Tensorflow API中的 tf.image.non_max_suppression 函式? 主要有兩個原因。 首先,在我看來,每個類執行NMS 要好得多,因為我們可能會遇到來自2個不同類的物件高度重疊,全域性NMS將抑制其中一個框的情況。 其次,有些人抱怨這個功能很慢,因為它尚未優化。
讓我們實現NMS演算法。 首先,我們需要一個函式來計算兩個邊界框的IoU(Intersection over Union):
def _iou(box1, box2):
b1_x0, b1_y0, b1_x1, b1_y1 = box1
b2_x0, b2_y0, b2_x1, b2_y1 = box2
int_x0 = max(b1_x0, b2_x0)
int_y0 = max(b1_y0, b2_y0)
int_x1 = min(b1_x1, b2_x1)
int_y1 = min(b1_y1, b2_y1)
int_area = (int_x1 - int_x0) * (int_y1 - int_y0)
b1_area = (b1_x1 - b1_x0) * (b1_y1 - b1_y0)
b2_area = (b2_x1 - b2_x0) * (b2_y1 - b2_y0)
iou = int_area / (b1_area + b2_area - int_area + 1e-05)
return iou現在我們可以編寫non_max_suppression函式的程式碼。 我使用NumPy庫進行快速向量操作。
def non_max_suppression(predictions_with_boxes, confidence_threshold, iou_threshold=0.4):
"""
Applies Non-max suppression to prediction boxes.
:param predictions_with_boxes: 3D numpy array, first 4 values in 3rd dimension are bbox attrs, 5th is confidence
:param confidence_threshold: the threshold for deciding if prediction is valid
:param iou_threshold: the threshold for deciding if two boxes overlap
:return: dict: class -> [(box, score)]
"""它需要3個引數:來自我們的YOLO v3檢測器的輸出,置信度閾值和IoU閾值。 這個函式的主體如下:
conf_mask = np.expand_dims((predictions_with_boxes[:, :, 4] > confidence_threshold), -1)
predictions = predictions_with_boxes * conf_mask
result = {}
for i, image_pred in enumerate(predictions):
shape = image_pred.shape
non_zero_idxs = np.nonzero(image_pred)
image_pred = image_pred[non_zero_idxs]
image_pred = image_pred.reshape(-1, shape[-1])
bbox_attrs = image_pred[:, :5]
classes = image_pred[:, 5:]
classes = np.argmax(classes, axis=-1)
unique_classes = list(set(classes.reshape(-1)))
for cls in unique_classes:
cls_mask = classes == cls
cls_boxes = bbox_attrs[np.nonzero(cls_mask)]
cls_boxes = cls_boxes[cls_boxes[:, -1].argsort()[::-1]]
cls_scores = cls_boxes[:, -1]
cls_boxes = cls_boxes[:, :-1]
while len(cls_boxes) > 0:
box = cls_boxes[0]
score = cls_scores[0]
if not cls in result:
result[cls] = []
result[cls].append((box, score))
cls_boxes = cls_boxes[1:]
ious = np.array([_iou(box, x) for x in cls_boxes])
iou_mask = ious < iou_threshold
cls_boxes = cls_boxes[np.nonzero(iou_mask)]
cls_scores = cls_scores[np.nonzero(iou_mask)]
return result至此,我們實現了YOLO v3所需的所有功能。
6.總結
在教程repo中,您可以找到用於執行檢測的程式碼和一些演示指令碼。 檢測器可以使用NHWC和NCHW資料格式,因此您可以輕鬆在您的機器上選擇能更快執行的格式。
如果您有任何疑問,請隨時與我聯絡。
我打算編寫本教程的下一部分,其中我將展示如何在自定義資料集上訓練(fine-tune,微調)YOLO v3。
謝謝閱讀。 如果你喜歡它,請通過鼓掌和/或分享來告訴我!:)
如果有什麼疑問,請到作者的github主頁下檢視已有問題的解答,或重新提問。
相關推薦
【膜拜大神】Tensorflow實現YOLO v3(TF-Slim)
最近我一直在使用Tensorflow中的YOLO v3。我在GitHub上找不到任何適合我需要的實現,因此我決定將這個用PyTorch編寫的程式碼轉換為Tensorflow。與論文一起釋出的YOLO v3的原始配置可以在Darknet GitHub repo中找到。 我
【前端】bootstrap4實現導航欄(非nav)
效果展示: html程式碼: <!-- 右側邊欄 --> <div class="list-group"> <button class="list-group-i
【算法專題】卡特蘭數(計數數列)
n-1 映射 點分治 blog -s 方法 .org div n-k Catalan數列:1 1 1 2 5 14 42 132 429 1430 4862 16796 【計數映射思想】 參考:卡特蘭數 — 計數的映射方法的偉大勝利 計數映射:將難以統計的數映射為另一種形式
【劍指offer】Java版代碼(完整版)
從尾到頭打印鏈表 .net 字符串 刪除 ron 代碼下載 逆序 鏈表 撲克 原文地址:https://blog.csdn.net/baiye_xing/article/details/78428561 一、引言 《劍指offer》可謂是程序猿面試的神書了,在面試中幫了我很
【劍指offer】矩陣中的路徑(回溯法)
# -*- coding:utf-8 -*- class Solution: def hasPathCore(self, matrix, rows, cols, row, col, path,
【Swift 2.1】共享檔案操作小結(iOS 8 +)
前言 適用於 iOS 8 + 本地共享檔案列表 宣告 歡迎轉載,但請保留文章原始出處:) 部落格園:http://www.cnblogs.com 農民伯伯: http://over140.cnblogs.com 正文 一、準備 1.1 預設 App 的檔案共
【零基礎向】軟考之路(第一章)計算機系統知識(第三節)
寫在前面: 本系列文章用於記錄本人軟考學習歷程,適用於零基礎人群,每天不定期更新,如果讀者哪裡不理解或者發現哪裡理解的有問題,歡迎評論,一起進步學習,祝大家都能順利通過考試~第三節 資料表示 本節主要是考察進位制轉換,也就是計算能力,需要熟記各個進位制之間的
NGS【1.1.2】測序質量值(Q20 & Q30)
引言 高通量測序每測完一個鹼基,會給出一個相應的測序質量值,用於衡量測序儀的準確度。測序錯誤率是在鹼基識別過程中通過一種判斷髮生錯誤概率的數學模型計算得到的,再根據測序錯誤率與鹼基的測序質量值之間的轉化關係,最終得到測序質量值。 公式 假定鹼基的測序錯誤率為:P
教你用TensorFlow實現神經網路(附程式碼)
來源:雲棲社群 作者:Pavel Surmenok 本文長度為2600字,建議閱讀5分鐘 本文幫助你理解神經網路的應用,並使用TensorFlow解決現實生活中的問題。 如果你一直關注資料科學
【菜鳥系列】SQL Server跨伺服器(跨例項)訪問資料庫
/*** 竟然又一次來寫部落格了~是經理建議我堅持寫部落格的~看了3個月前我的第一篇部落格,也覺得很有必要 囉嗦幾句~ 一眨眼3個月過去了~本人有沒有變得NB一點了呢? 完全沒有!!!而且還變的更菜了~現在看自己寫的部落格已經有點看不懂了~真是太不幸了~ 最近單位做了一款
【龍書答案】第三章解析(未完成)
Exercise 3.3 Problem 3.3.1 Consult the language reference manuals to determine The sets of characters that form the input a
【Spring學習筆記】11 spring aop 程式設計(註解方式)
2018.5.25註解方式比較繁瑣不直觀,瞭解即可1.建立web專案2.引入jar包在原來jar包基礎上引入aop相關的jar包3.日誌檔案log4j.properties4.準備目標物件先建立介面再建立實現類package com.lu.spring.aop.service
【NOIP普及組】2016年模擬考試(11.5)——火柴棒等式
一、火柴棒等式(equation.cpp) 時間限制: 1 Sec 記憶體限制: 128 MB 題目描述 給你n根火柴棍,你可以拼出多少個形如“A+B=C”的等式?等式中的A、B、C是用火柴棍拼
tensorflow實現基於KNN(和CNN)演算法的阿拉伯數字識別(程式碼詳解)
廢話不多說,直接上專案;(大家如果感興趣可以加深度學習程式碼實現群:225215316,或者畢業想做此方向的加畢設討論群:457756921) 首先我們先將具體的數字圖片轉換為向量矩陣形式,儲存在txt檔案下,具體格式如下,其是數字0的矩陣向量形式:整個專案資料
【大話設計模式】——行為型模式總結(一對多)
根據上上一篇部落格的分類,這篇部落格總結一下有一對多關係的模式:職責鏈,中介者,觀察者,迭代器。其實這幾個模式沒什麼大關係,也沒什麼可以比較的,硬是讓我把它們放在了一起。 一、職責鏈(Cha
【PTA 天梯賽】L1-046 整除光棍(除法模擬)
模擬 提示 spa 說明 otto tex esp -o ++ 這裏所謂的“光棍”,並不是指單身汪啦~ 說的是全部由1組成的數字,比如1、11、111、1111等。傳說任何一個光棍都能被一個不以5結尾的奇數整除。比如,111111就可以被13整除。
【資料結構06】二叉平衡樹(AVL樹)
目錄 一、平衡二叉樹定義 二、這貨還是不是平衡二叉樹? 三、平衡因子 四、如何保持平衡二叉樹平衡? 五、平衡二叉樹插入節點的四種情況 六、平衡二叉樹操作的程式碼實現
tensorflow之常用函式(tf.Constant)
轉載:http://blog.sina.com.cn/s/blog_e504f4340102yd4k.html tensorflow中我們會看到這樣一段程式碼: import tensorflow as tf a = tf.constant([1.0, 2
什麽是大數據?大數據有什麽用?【聽大神來分析!】
關系 科學研究 UC 數據倉庫 人才 異構 對數 mapred AR 什麽是大數據大數據技術的戰略意義不在於掌握龐大的數據信息,而在於對這些含有意義的數據進行專業化處理。換而言之,如果把大數據比作一種產業,那麽這種產業實現盈利的關鍵,在於提高對數據的“加工能力”,通過“加工
【TensorFlow實戰】TensorFlow實現經典卷積神經網絡之VGGNet
3*3 一次 卷積神經網絡 有意 研究 而不是 不同等級 帶來 這一 VGGNet VGGNet是牛津大學計算機視覺組與Google DeepMind公司的研究員一起研發的深度卷積神經網絡。VGGNet探索了卷積神經網絡的深度與其性能之間的關系,通過反復堆疊3*3的小型