
用caffe 搭建簡單的二分類網路
一、將自己的圖片資料生成lmdb格式的資料(caffe可以接收的資料格式)
1、在caffe/data中建立資料夾 myself,在myself中建立子資料夾 train 和 val
2、在train資料夾中建立cat和bird資料夾,分別從網上下載50張貓和50張鳥存放在相應的資料夾下
3、命名圖片為cat1.jpeg ……cat50.jpeg和 bird1.jpeg……bird50.jpeg。
命名好以後是這樣子滴:
4、重新下載10張貓和10張鳥存放在val資料夾下為測試用,並重新命名
5、在myself資料夾下,建立train.txt,test.txt以及val.txt檔案,最後的結構是這個樣子的:
(有些檔案是以後測試用的請自動忽略)
train.txt內容:
cat/cat1.jpeg 0
cat/cat2.jpeg 0
。。。。。。
cat/cat50.jpeg 0
bird/bird1.jpeg 1
bird/bird2.jpeg 1
。。。。。。
bird/bird50.jpeg 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
0和1是貓和鳥的類別標號。
test.txt內容:
cat3.jpeg 0
bird5.jpeg 0
bird4.jpeg 0
cat4.jpeg 0
cat9.jpeg 0
bird2.jpeg 0
cat8.jpeg 0
bird10.jpeg 0
cat5.jpeg 0
bird7.jpeg 0
bird9.jpeg - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
val.txt內容:
cat3.jpeg 0
bird5.jpeg 1
bird4.jpeg 1
cat4.jpeg 0
cat9.jpeg 0
bird2.jpeg 1
cat8.jpeg 0
bird10.jpeg 1
cat5.jpeg 0
bird7.jpeg 1
bird9.jpeg 1
cat1.jpeg 0
cat10.jpeg - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
6、將所有下載的圖片都歸一化為256*256大小
批量改變圖片的尺寸,終端輸入 :
for i in caffe/data/myself/train/cat/*.jpeg; do convert -resize 256x256! $i $i; done
- 1
- 2
7、在caffe/examples下建立myself資料夾存放一些網路搭建程式,將imagenet的create_imagenet.sh複製到該資料夾下進行修改,主要修改幾個目錄,執行該sh檔案(目的是將之前設定好的貓和鳥資料生成相應的lmbd格式的資料)
create_imagenet.sh檔案修改後為:
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
# N.B. set the path to the imagenet train + val data dirs
set -e
EXAMPLE=/home/coco/caffe/examples/myself #生成的lmdb資料的存放地址
DATA=/home/coco/caffe/data/myself #原始資料資料夾的存放地址
TOOLS=/home/coco/caffe/build/tools #資料格式轉換工具的存放地址
TRAIN_DATA_ROOT=/home/coco/caffe/data/myself/train/ #訓練資料的存放地址
VAL_DATA_ROOT=/home/coco/caffe/data/myself/val/ #校驗資料的存放地址
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/imagenet_train_lmdb1
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/val.txt \
$EXAMPLE/imagenet_val_lmdb1
echo "Done."- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
此時在caffe/examples/myself資料夾下會得到 imagenet_train_lmdb和imagenet_val_lmdb資料夾。
二、計算影象的均值
模型需要我們從每張圖片減去均值,所以我們必須獲得訓練的均值,用tools/compute_image_mean.cpp實現,這個cpp是一個很好的例子去熟悉如何操作多個元件。直接複製imagenet的./make_imagenet_mean到caffe/examples/myself下進行修改即可。
#!/usr/bin/env sh
# Compute the mean image from the imagenet training lmdb
# N.B. this is available in data/ilsvrc12
EXAMPLE=/home/coco/caffe/examples/myself
DATA=/home/coco/caffe/data/myself
TOOLS=/home/coco/caffe/build/tools
$TOOLS</span>/compute_image_mean.bin <span class="hljs-variable">$EXAMPLE/imagenet_train_lmdb \
$DATA/imagenet_mean.binaryproto
echo "Done."- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可能會報錯:
coco@coco-OMEN-by-HP-Laptop:~/caffe/examples/myself$ ./make_imagenet_mean.shF1008 15:47:15.137737 13163 compute_image_mean.cpp:77] Check failed: size_in_datum == data_size (213180 vs. 196608) Incorrect data field size 213180
- 1
- 2
原因:上一步生成lmdb檔案時,圖片歸一化沒有成功,更改myself資料夾下的create_imagenet.sh檔案,將 RESIZE=false改為RESIZE=true
三、網路定義
這一部分比較簡單,主要是修改一些路徑即可
從/home/coco/caffe/models/bvlc_reference_caffenet資料夾下複製train_val.prototxt,solver.prototxt檔案到examples/myself資料夾下,並進行路徑的修改。
部分程式碼如下:主要是修改訓練資料和測試資料的來源以及均值檔案的來源
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "/home/coco/caffe/data/myself/imagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "/home/coco/caffe/examples/myself/imagenet_train_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "/home/coco/caffe/data/myself/imagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "/home/coco/caffe/examples/myself/imagenet_val_lmdb"
batch_size: 50
backend: LMDB
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
注意:路徑的名稱儘量寫絕對地址,寫全稱,防止執行時報錯。
Solver.prototxt的內容如下:
net: "/home/coco/caffe/examples/myself/train_val.prototxt"
test_iter: 1000
test_interval: 1000
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "/home/coco/caffe/examples/myself/snapshot" //快照的存放地址
solver_mode: GPU- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
四、訓練
在myself資料夾下編寫train_mynet.sh檔案,內容如下:
#!/usr/bin/env sh
set -e
/home/coco/caffe/build/tools/caffe train \
--solver=/home/coco/caffe/examples/myself/solver.prototxt [email protected]- 1
- 2
- 3
- 4
- 5
執行此sh檔案即可。
終端最終的輸出結果:
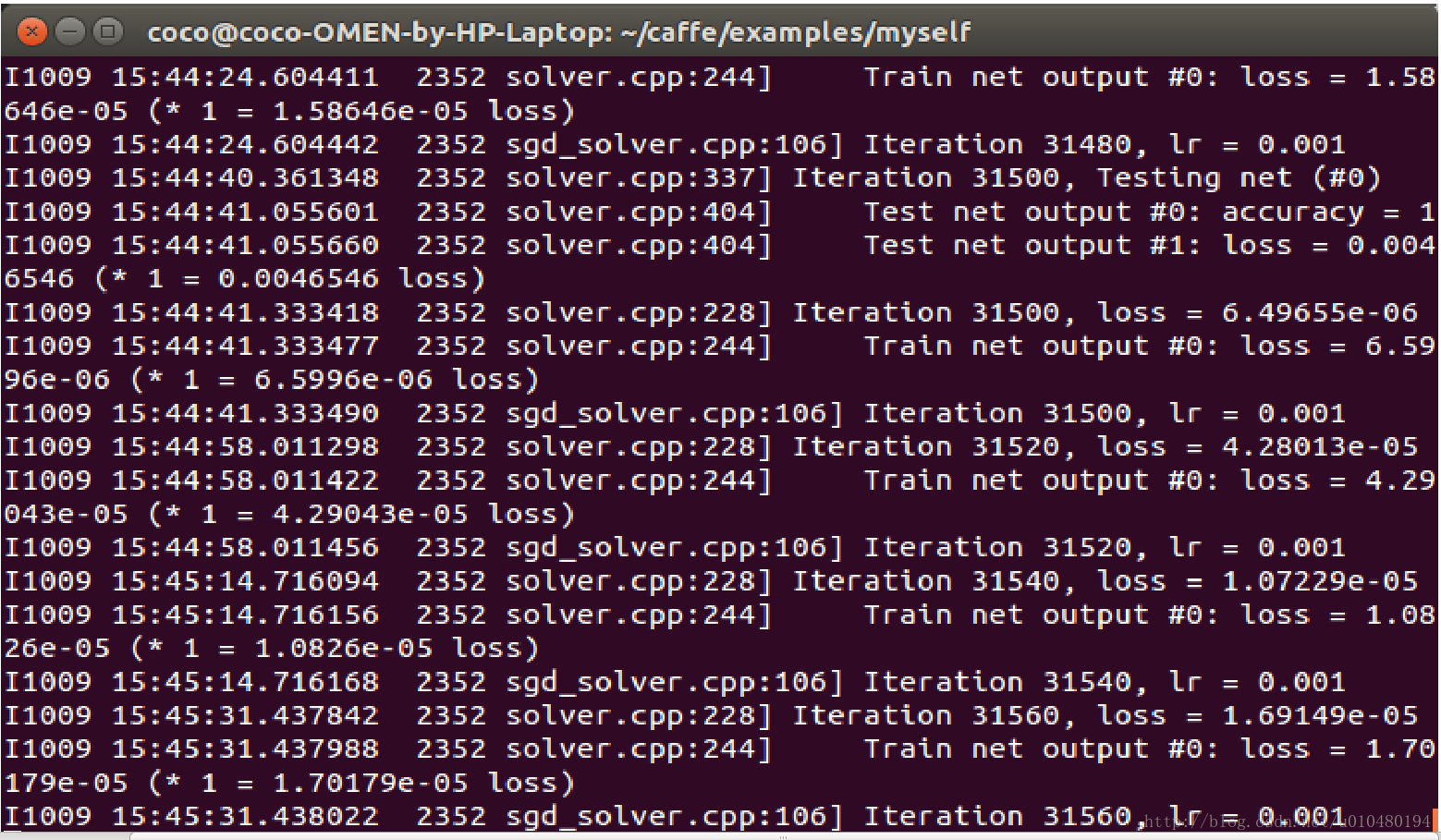
注意:由於樣本量很小,理論上很短的時間內就可以收斂。可能是caffe沒有收斂的功能,最終會迭代到最大的迭代次數才可以結束整個訓練過程。觀察test過程中accuarucy很早就已經為1了,所以最大的迭代次數可以不必設定成很大的值。
用上面搭建的網路完成測試吧
在caffe/examples/myself/testtxt資料夾下已經寫好了所有的需要測試的檔案,檔案目錄如下:
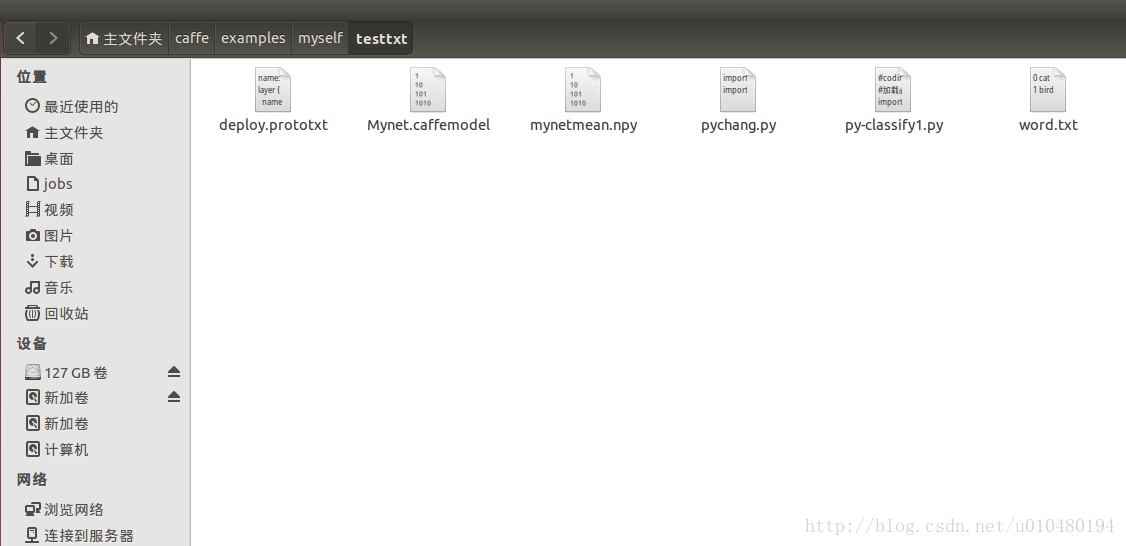
1.deploy.prototxt檔案編寫
直接從models資料夾裡面考過來,更改一些小細節
layer {
name:"fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param {
num_output: 2 //需要更改的地方,輸出的分類數量是2,因為此時我們只有兩類貓和鳥
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、Mynet.caffemodel
caffe模型,存放的是一些模型的引數,直接用之前訓練過程結果即可。複製貼上過來並改名稱。
3、mynetmean.npy均值檔案,用來對測試資料去均值的,可以加快測試的速度。
該檔案是從caffe/data/myself/imagenet_mean.binary檔案轉化過來的,轉化的方法是:
終端輸入:
python pychang.py
- 1
- 2
pychang.py是寫好的python格式的轉化工具
4、word.txt檔案,是分類檔案,裡面儲存了分的類別數,內容如下:
0 cat
1 bird- 1
- 2
5、py-classify.py是python版本的最終用來執行的分類檔案
檔案裡面的一些內容主要是依託前面寫的檔案內容如下:
#coding=utf-8
#載入必要的庫
import numpy as np
import sys,os
#設定當前目錄
caffe_root = '/home/coco/caffe/'
sys.path.insert(0, caffe_root + 'python')
import caffe
os.chdir(caffe_root)
net_file=caffe_root + 'examples/myself/testtxt/deploy.prototxt'
caffe_model=caffe_root + 'examples/myself/testtxt/Mynet.caffemodel'
mean_file=caffe_root + 'examples/myself/testtxt/mynetmean.npy'
net = caffe.Net(net_file,caffe_model,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
00
im=caffe.io.load_image(caffe_root+'data/myself/train/bird/bird19.jpeg')//這裡表示你要測試的圖片的地址
net.blobs['data'].data[...] = transformer.preprocess('data',im)
out = net.forward()
imagenet_labels_filename = caffe_root + 'examples/myself/testtxt/word.txt'
labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t')
top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
for i in np.arange(top_k.size):
print top_k[i], labels[top_k[i]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
終端最終的執行結果如下:

第一個輸出的是bird第二個才是cat,證明圖片bird19.jpeg更像bird一些,測試正確。
相關推薦
用caffe 搭建簡單的二分類網路
一、將自己的圖片資料生成lmdb格式的資料(caffe可以接收的資料格式) 1、在caffe/data中建立資料夾 myself,在myself中建立子資
搭建簡單圖片分類的卷積神經網路(二)-- CNN模型與訓練
一、首先,簡單來說CNN卷積神經網路與BP神經網路主要區別在於: 1、網路的層數的多少(我這裡的CNN是比較簡單的,層數較少,真正應用的話,層數是很多的)。 2、CNN名稱來說,具有卷積運算的特點,對於大型的圖片或者數量多的圖片,卷積運算可以大量提高計算效能,而BP神經網路大都為全連線層,計
搭建簡單圖片分類的卷積神經網路(三)-- 模型的測試和運用
兩個功能都在同一個檔案中 一、新建Disimage.py檔案 import tensorflow as tf from PIL import Image import os import numpy as np import matplotlib.pyplot as plt from Get
搭建簡單圖片分類的卷積神經網路(一)-- 訓練模型的圖片資料預處理
一、訓練之前資料的預處理主要包括兩個方面 1、將圖片資料統一格式,以標籤來命名並存到train資料夾中(假設原始圖片按類別存到資料夾中)。 2、對命名好的圖片進行訓練集和測試集的劃分以及圖片資料化。 先對整個專案檔案進行說明: 專案資料夾
用Tensorflow搭建第一個神經網路
簡述 搭建這個神經網路 其實是從一個層到10層再到10層的這樣的一個神經網路。(畫圖醜。。。求諒解。。就別私戳了) 解析 初始的輸入的矩陣為:[[1],300個,[-1]] 大致這樣的 在增加一層的那個函式中,最為經典的地方是,偏置(biases)的第一個
獨家 | 手把手教你用Python建立簡單的神經網路(附程式碼)
作者:Michael J.Garbade 翻譯:陳之炎 校對:丁楠雅 本文共2000字,建議閱讀9分鐘。本文將為你演示如何建立一個神經網路,帶你深入瞭解神經網路的工作方式。 瞭解神經網路工作方式的最佳途徑莫過於親自建立一個神經網路,本文將演示如何做到這一點。
keras實現基於vgg16的貓-狗二分類網路
import keras from keras.models import Sequential from keras.layers import Dense,MaxPooling2D,Input,Flatten,Convolution2D,Dropout from kera
用nodeJS搭建簡單的靜態服務
靜態資源服務 1、可以指定多個目錄作為靜態資源的跟路徑 2、可以指定虛擬路徑 這裡用express框架去搭建 const express = require('express
手把手教你用Python建立簡單的神經網路!
資料 : 瞭解神經網路如何工作的最佳方法是學習如何從頭開始構建神經網路(而不是採用任何庫)。 在本文中,我們將演示如何利用Python程式語言建立一個簡單的神經網路。 問題 如下是一個展示問題的表格。
tensorflow學習之訓練自己的CNN模型(簡單二分類)
本文借鑑已有cat-vs-dog模型,在此模型上進行修改。該模型可在以下網址下載,後續將對模型進行解析及進一步修改。https://download.csdn.net/download/twinkle_star1314/10414568。今天先對模型進行分析:一、模
區塊鏈--用nodejs實現簡單的P2P網路
最近學習了200行程式碼實現一個簡單的區塊鏈https://github.com/lhartikk/naivechain初步學習nodejs,實現P2P網路的簡單模式,添加了多點資訊同步更新。節點功能實現: var initHttpServer = () =>{//控制
用vlc搭建簡單流媒體伺服器(UDP和TCP方式)
這段時間用到了流媒體資料傳輸的TCP和UDP方式,感覺vlc可以做這方面的demo,這裡總結下,也方便我以後查閱。 簡介 VLC不僅僅是個播放器,也可以作為流媒體伺服器使用。這個網上有相關的資料,我就不多說了。 宣告下本文用的VLC版本:2.0.3 用VLC搭建基於UDP的流媒體伺服器 流媒體伺服器大
用nginx搭建簡單的檔案下載伺服器
1,sudo gedit /etc/nginx/conf.d/file_server.conf,內容如下: server { listen 80; #埠 server_name localhost; #服務名
用vlc搭建簡單流媒體伺服器(UDP和TCP方式)-轉 rtsp很慢才能顯示
這段時間用到了流媒體資料傳輸的TCP和UDP方式,感覺vlc可以做這方面的demo,這裡總結下,也方便我以後查閱。 簡介 VLC不僅僅是個播放器,也可以作為流媒體伺服器使用。這個網上有相關的資料,我就不多說了。 宣告下本文用的VLC版本:2.0.3 用VLC搭建基於UDP的流媒體伺服器 流媒體伺服
知識圖譜—知識儲存—僅用neo4j搭建簡單的金融知識圖譜
一、任務描述 本文章旨在用neo4j構建一個簡單的金融領域的知識圖譜,挖掘“高管—上市企業—行業/概念”之間的關係。關於具體的任務描述可下載我百度網盤的連結。連結:https://pan.baidu.com/s/1jLl9LnnHL4gaboUYXrYEDg
用vlc搭建簡單流媒體伺服器(UDP方式)
簡介 VLC不僅僅是個播放器,也可以作為流媒體伺服器使用。這個網上有相關的資料,我就不多說了。 宣告下本文用的VLC版本:2.0.3 用VLC搭建基於UDP的流媒體伺服器 流媒體伺服器大多數是基於UDP的,這個在VLC中也有好幾種實現,我這裡只列出我用到的幾個。
keras快速搭建神經網路進行電影文字評論二分類
在本次部落格中,將討論英語文字分類問題,可同樣適用於文字情感分類,屬性分類等文字二分類問題。 1、資料準備 &nbs
【Python】搭建你的第一個簡單的神經網路_準備篇_NN&DL學習筆記(二)
前言 本文為《Neural Network and Deep Learning》學習筆記(二),可以轉載但請標明原文地址。 本人剛剛入門、筆記簡陋不足、多有謬誤,而原書精妙易懂、不長篇幅常有柳暗花明之處,故推薦閱讀原書。 《Neural Network and Deep Learning
深度學習二:使用TensorFlow搭建簡單的全連線神經網路
深度學習二:使用TensorFlow搭建簡單的全連線神經網路 學習《TensorFlow實戰Google深度學習框架》一書 在前一篇部落格中,學習了使用python搭建簡單的全連線神經網路 深度學習一:搭建簡單的全連線神經網路 這裡繼續學習使用TensorFlow來搭建全連線神經
利用TensorFlow訓練簡單的二分類神經網路模型
利用TensorFlow實現《神經網路與機器學習》一書中4.7模式分類練習 具體問題是將如下圖所示雙月牙資料集分類。 使用到的工具: python3.5 tensorflow1.2.1 n