
Python簡單爬蟲例項
前剛接觸python,看了一下基本語法,照著網上的一篇部落格寫了個很簡單的爬蟲小demo,有興趣的可以看下
實現,將一個網頁中的所有jpg圖片,及網頁中所有.html格式的跳轉連結中的jpg檔案取出來儲存到本地
主要用到一個urllib庫,使用很簡單,用於讀取網頁內容,和直接從網路下載圖片(感覺這個庫很屌的樣子)
還有就是一些正則驗證,用於篩網頁中選想要的內容
直接貼程式碼:
#coding=utf-8
import urllib,threading
import re
x = 0
# 讀取網頁內容
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
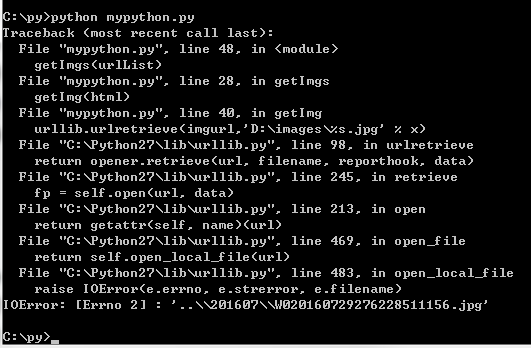
return 然後執行python檔案(這裡有報錯,好像是取出的圖片連結有幾個取不到):
開啟之前指定的資料夾,圖片已經都下載下來了!
相關推薦
Python簡單爬蟲例項
前剛接觸python,看了一下基本語法,照著網上的一篇部落格寫了個很簡單的爬蟲小demo,有興趣的可以看下 實現,將一個網頁中的所有jpg圖片,及網頁中所有.html格式的跳轉連結中的jpg檔案取出來儲存到本地 主要用到一個urllib庫,使用很簡單,用於讀
幾個python簡單爬蟲例項
# coding=utf-8 import requests import re header = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:47.0) Gec
python 簡單爬蟲
.... ror gbk 訪問 req 爬取 exc .cn 所有 使用urllib.request 和re 模塊 1 from urllib.request import * 2 import re #處理網絡訪問 3 #獲取網頁 4 url = ‘https:/
python簡單爬蟲筆記
wow write file except .com 下載 app sina retrieve python模擬遊覽器爬取相關頁面 import urllib.request url="http://blog.51cto.com/itstyle/2146899" #模擬
python簡單爬蟲
url get out res except urlopen 5.0 html_ lse from urllib import request,parse from urllib.error import HTTPError,URLError def get(url,he
Python:爬蟲例項2:爬取貓眼電影——破解字型反爬
字型反爬 字型反爬也就是自定義字型反爬,通過呼叫自定義的字型檔案來渲染網頁中的文字,而網頁中的文字不再是文字,而是相應的字型編碼,通過複製或者簡單的採集是無法採集到編碼後的文字內容的。 現在貌似不少網站都有采用這種反爬機制,我們通過貓眼的實際情況來解釋一下。 下圖的是貓眼網頁
python Scrapy 爬蟲例項
https://www.jianshu.com/p/78f0bc64feb8 1.新建專案 scrapy startproject cnblog 2.pycharm 開啟專案 image.png 3.新建spider image.png 新
簡單爬蟲例項
程式碼工具:jupyter 抓包工具:fiddle 1:搜狗頁面內容爬取 1 import requests 2 3 url='https://www.sogou.com/' 4 response=requests.get( 5 url=url 6 ) 7 text=re
python:簡單爬蟲示例,含分析文件,建庫,程式程式碼
環境:ubantu18.04,mysql5.7,python3.6 1.分析文件 1.1 目標 爬取笑話集-最新兒童笑話大全前三頁的笑話題目,訪問量,發表時間 1.2 URL 第一頁:www.jokeji.cn/list7_1.htm 第三頁:www.jokej
python簡單爬蟲程式碼示例2
目標網站:view-source:http://www.weather.com.cn/weather/101270101.shtml 程式碼: from urllib.request import urlopen from bs4 import Beautifu
Python requests爬蟲例項
作業系統:Windows Python:3.5 歡迎加入學習交流QQ群:657341423 需要用到的庫: requests wxPython docx win32api需要安裝pywin32 解釋: requests這個用來做爬蟲,基本上不用多作解釋 wx
【Python簡單爬蟲設計】對豆瓣TOP100的電影名及簡要的爬取
1.使用Designer建立圖形介面(詳細操作見往期部落格點選開啟連結)對UI控制元件的繫結程式碼片段def __init__(self): QtGui.QMainWindow.__init__(self) pachong.Ui_MainWindow.__in
Python簡單爬蟲專案
專案搭建過程 一、新建python專案 在對應的地址 中 開啟 cmd 輸入:scrapy startproject first 2、在pyCharm 中開啟新建立的專案,建立spider 爬蟲核心檔案ts.py import scrapy from firs
python簡單爬蟲:爬取並統計自己部落格頁面的資訊(一)
1. 什麼是爬蟲 也叫網路爬蟲,簡單來說,爬蟲就是從一個根網站出發,根據某種規則獲得更多的相關網站的url,自動下載這些網頁並自動解析這些網頁的內容,從中獲取需要的資料。例如爬取某種圖片、某類文字資訊等。爬蟲還可以用於編纂搜尋引擎的網路索引。 爬蟲所涉及的知
python簡單爬蟲 多執行緒爬取京東淘寶資訊教程
1,需要準備的工作,電腦已經安裝好python,如果沒裝,可以執行去https://www.python.org/官網下載,初學者可以安裝輕量級的wingide python開發工具,python安裝成功後配置好環境變數,在dos環境使用pip install 模組 將需要用
python 網路爬蟲例項
自己用Python寫了一個抓取百度貼吧裡面的圖片的小例項,程式碼如下: from urllib.request import urlopen from urllib.request import ur
python簡單爬蟲練習
開始學爬蟲了,記錄一下這兩天的瞎鼓搗 抓取一個網頁 先從最簡單的來,指定一個url,把整個網頁程式碼抓下來,這裡就拿csdn的主頁實驗 # -*- coding: UTF-8 -*- from urllib import request url = 'h
python簡單爬蟲程式碼,python入門
python爬取慕課網首頁課程標題與內容介紹 效果圖: 思路: 獲取頁面內容存入html –> 利用正則表示式獲取所有課程塊的div盒子存入everydiv –> 在每個課程
python網路爬蟲例項:Requests+正則表示式爬取貓眼電影TOP100榜
一、前言 最近在看崔慶才先生編寫的《Python3網路爬蟲開發實戰》這本書,學習了requests庫和正則表示式,爬取貓眼電影top100榜單是這本書的第一個例項,主要目的是要掌握requests庫和正則表示式在實際案例中的使用。 二、開發環境 執行平
Python簡單爬蟲爬取多頁圖片
初學爬蟲簡單的爬了爬貼吧圖片 #!/usr/bin/python # coding utf-8 import re import time import urllib def getHtml():