
樸素貝葉斯演算法 & 應用例項
一、樸素貝葉斯演算法介紹
樸素貝葉斯,之所以稱為樸素,是因為其中引入了幾個假設(不用擔心,下文會提及)。而正因為這幾個假設的引入,使得模型簡單易理解,同時如果訓練得當,往往能收穫不錯的分類效果,因此這個系列以naive bayes開頭和大家見面。
因為樸素貝葉斯是貝葉斯決策理論的一部分,所以我們先快速瞭解一下貝葉斯決策理論。
假設有一個數據集,由兩類組成(簡化問題),對於每個樣本的分類,我們都已經知曉。資料分佈如下圖(圖取自MLiA):
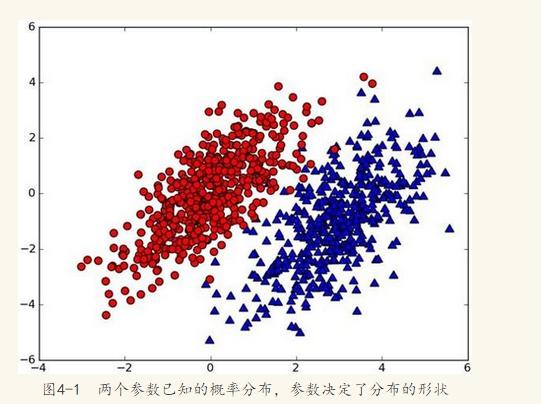
現在出現一個新的點new_point (x,y),其分類未知。我們可以用p1(x,y)表示資料點(x,y)屬於紅色一類的概率,同時也可以用p2(x,y)
我們提出這樣的規則:
如果p1(x,y) > p2(x,y),則(x,y)為紅色一類。
如果p1(x,y) <p2(x,y), 則(x,y)為藍色一類。
換人類的語言來描述這一規則:選擇概率高的一類作為新點的分類。這就是貝葉斯決策理論的核心思想,即選擇具有最高概率的決策。
用條件概率的方式定義這一貝葉斯分類準則:
如果p(red|x,y) > p(blue|x,y), 則(x,y)屬於紅色一類。
如果p(red|x,y) < p(blue|x,y), 則(x,y)屬於藍色一類。
也就是說,在出現一個需要分類的新點時,我們只需要計算這個點的
max(p(c1 | x,y),p(c2 | x,y),p(c3 | x,y)...p(cn| x,y))。其對於的最大概率標籤,就是這個新點的分類啦。
那麼問題來了,對於分類i 如何求解p(ci| x,y)?
沒錯,就是貝葉斯公式:
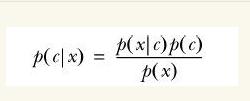
公式暫不推導,先描述這個轉換的重要性。紅色、藍色分類是為了幫助理解,這裡要換成多維度說法了,也就是第二部分的例項:判斷一條微信朋友圈是不是廣告。
前置條件是:我們已經擁有了一個平日廣大使用者的朋友圈內容庫,這些朋友圈當中,如果真的是在做廣告的,會被“熱心網友”打上“廣告”的標籤,我們要做的是把所有內容分成一個一個詞,每個詞對應一個維度,構建一個高維度空間 (別擔心,這裡未出現向量計算)。
當出現一條新的朋友圈new_post,我們也將其分詞,然後投放到朋友圈詞庫空間裡。
這裡的X表示多個特徵(詞)x1,x2,x3...組成的特徵向量。
P(ad|x)表示:已知朋友圈內容而這條朋友圈是廣告的概率。
利用貝葉斯公式,進行轉換:
P(ad|X) = p(X|ad) p(ad) / p(X)
P(not-ad | X) = p(X|not-ad)p(not-ad) / p(X)
比較上面兩個概率的大小,如果p(ad|X) > p(not-ad|X),則這條朋友圈被劃分為廣告,反之則不是廣告。
看到這兒,實際問題已經轉為數學公式了。
看公式推導 (公式圖片引用):
樸素貝葉斯分類的正式定義如下:
1、設 為一個待分類項,而每個a為x的一個特徵屬性。
為一個待分類項,而每個a為x的一個特徵屬性。
2、有類別集合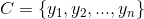 。
。
3、計算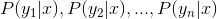 。
。
4、如果 ,則
,則  。
。
那麼現在的關鍵就是如何計算第3步中的各個條件概率。我們可以這麼做:
1、找到一個已知分類的待分類項集合,這個集合叫做訓練樣本集。
2、統計得到在各類別下各個特徵屬性的條件概率估計。即。
3、如果各個特徵屬性是條件獨立的,則根據貝葉斯定理有如下推導:
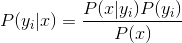
因為分母對於所有類別為常數,因為我們只要將分子最大化皆可。又因為各特徵屬性是條件獨立的,所以有:
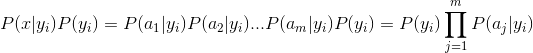
這裡要引入樸素貝葉斯假設了。如果認為每個詞都是獨立的特徵,那麼朋友圈內容向量可以展開為分詞(x1,x2,x3...xn),因此有了下面的公式推導:
P(ad|X) = p(X|ad)p(ad) = p(x1, x2, x3, x4...xn | ad) p(ad)
假設所有詞相互條件獨立,則進一步拆分:
P(ad|X) = p(x1|ad)p(x2|ad)p(x3|ad)...p(xn|ad) p(ad)
雖然現實中,一條朋友圈內容中,相互之間的詞不會是相對獨立的,因為我們的自然語言是講究上下文的╮(╯▽╰)╭,不過這也是樸素貝葉斯的樸素所在,簡單的看待問題。
看公式p(ad|X)=p(x1|ad)p(x2|ad)p(x3|ad)...p(xn|ad) p(ad)
至此,P(xi|ad)很容易求解,P(ad)為詞庫中廣告朋友圈佔所有朋友圈(訓練集)的概率。我們的問題也就迎刃而解了。
二、構造一個文字廣告過濾器。
到這裡,應該已經有心急的讀者掀桌而起了,搗鼓半天,沒有應用。 (╯‵□′)╯︵┻━┻
"Talk is cheap, show me the code."
邏輯均在程式碼註釋中,因為用python編寫,和虛擬碼沒啥兩樣,而且我也懶得畫圖……


1 #encoding:UTF-8 2 ''' 3 Author: marco lin 4 Date: 2015-08-28 5 ''' 6 7 from numpy import * 8 import pickle 9 import jieba 10 import time 11 12 stop_word = [] 13 ''' 14 停用詞集, 包含“啊,嗎,嗯”一類的無實意詞彙以及標點符號 15 ''' 16 def loadStopword(): 17 fr = open('stopword.txt', 'r') 18 lines = fr.readlines() 19 for line in lines: 20 stop_word.append(line.strip().decode('utf-8')) 21 fr.close() 22 23 ''' 24 建立詞集 25 params: 26 documentSet 為訓練文件集 27 return:詞集, 作為詞袋空間 28 ''' 29 def createVocabList(documentSet): 30 vocabSet = set([]) 31 for document in documentSet: 32 vocabSet = vocabSet | set(document) #union of the two sets 33 return list(vocabSet) 34 35 ''' 36 載入資料 37 ''' 38 def loadData(): 39 return None 40 41 ''' 42 文字處理,如果是未處理文字,則先分詞(jieba分詞),再去除停用詞 43 ''' 44 def textParse(bigString, load_from_file=True): #input is big string, #output is word list 45 if load_from_file: 46 listOfWord = bigString.split('/ ') 47 listOfWord = [x for x in listOfWord if x != ' '] 48 return listOfWord 49 else: 50 cutted = jieba.cut(bigString, cut_all=False) 51 listOfWord = [] 52 for word in cutted: 53 if word not in stop_word: 54 listOfWord.append(word) 55 return [word.encode('utf-8') for word in listOfWord] 56 57 ''' 58 交叉訓練 59 ''' 60 CLASS_AD = 1 61 CLASS_NOT_AD = 0 62 63 def testClassify(): 64 listADDoc = [] 65 listNotADDoc = [] 66 listAllDoc = [] 67 listClasses = [] 68 69 print "----loading document list----" 70 71 #兩千個標註為廣告的文件 72 for i in range(1, 1001): 73 wordList = textParse(open('subject/subject_ad/%d.txt' % i).read()) 74 listAllDoc.append(wordList) 75 listClasses.append(CLASS_AD) 76 #兩千個標註為非廣告的文件 77 for i in range(1, 1001): 78 wordList = textParse(open('subject/subject_notad/%d.txt' % i).read()) 79 listAllDoc.append(wordList) 80 listClasses.append(CLASS_NOT_AD) 81 82 print "----creating vocab list----" 83 #構建詞袋模型 84 listVocab = createVocabList(listAllDoc) 85 86 docNum = len(listAllDoc) 87 testSetNum = int(docNum * 0.1); 88 89 trainingIndexSet = range(docNum) # 建立與所有文件等長的空資料集(索引) 90 testSet = [] # 空測試集 91 92 # 隨機索引,用作測試集, 同時將隨機的索引從訓練集中剔除 93 for i in range(testSetNum): 94 randIndex = int(random.uniform(0, len(trainingIndexSet))) 95 testSet.append(trainingIndexSet[randIndex]) 96 del(trainingIndexSet[randIndex]) 97 98 trainMatrix = [] 99 trainClasses = [] 100 101 for docIndex in trainingIndexSet: 102 trainMatrix.append(bagOfWords2VecMN(listVocab, listAllDoc[docIndex])) 103 trainClasses.append(listClasses[docIndex]) 104 105 print "----traning begin----" 106 pADV, pNotADV, pClassAD = trainNaiveBayes(array(trainMatrix), array(trainClasses)) 107 108 print "----traning complete----" 109 print "pADV:", pADV 110 print "pNotADV:", pNotADV 111 print "pClassAD:", pClassAD 112 print "ad: %d, not ad:%d" % (CLASS_AD, CLASS_NOT_AD) 113 114 args = dict() 115 args['pADV'] = pADV 116 args['pNotADV'] = pNotADV 117 args['pClassAD'] = pClassAD 118 119 fw = open("args.pkl", "wb") 120 pickle.dump(args, fw, 2) 121 fw.close() 122 123 fw = open("vocab.pkl", "wb") 124 pickle.dump(listVocab, fw, 2) 125 fw.close() 126 127 errorCount = 0 128 for docIndex in testSet: 129 vecWord = bagOfWords2VecMN(listVocab, listAllDoc[docIndex]) 130 if classifyNaiveBayes(array(vecWord), pADV, pNotADV, pClassAD) != listClasses[docIndex]: 131 errorCount += 1 132 doc = ' '.join(listAllDoc[docIndex]) 133 print "classfication error", doc.decode('utf-8', "ignore").encode('gbk') 134 print 'the error rate is: ', float(errorCount) / len(testSet) 135 136 # 分類方法(這邊只做二類處理) 137 def classifyNaiveBayes(vec2Classify, pADVec, pNotADVec, pClass1): 138 pIsAD = sum(vec2Classify * pADVec) + log(pClass1) #element-wise mult 139 pIsNotAD = sum(vec2Classify * pNotADVec) + log(1.0 - pClass1) 140 141 if pIsAD > pIsNotAD: 142 return CLASS_AD 143 else: 144 return CLASS_NOT_AD 145 146 ''' 147 訓練 148 params: 149 tranMatrix 由測試文件轉化成的詞空間向量 所組成的 測試矩陣 150 tranClasses 上述測試文件對應的分類標籤 151 ''' 152 def trainNaiveBayes(trainMatrix, trainClasses): 153 numTrainDocs = len(trainMatrix) 154 numWords = len(trainMatrix[0]) #計算矩陣列數, 等於每個向量的維數 155 numIsAD = len(filter(lambda x: x == CLASS_AD, trainClasses)) 156 pClassAD = numIsAD / float(numTrainDocs) 157 pADNum = ones(numWords); pNotADNum = ones(numWords) 158 pADDenom = 2.0; pNotADDenom = 2.0 159 160 for i in range(numTrainDocs): 161 if trainClasses[i] == CLASS_AD: 162 pADNum += trainMatrix[i] 163 pADDenom += sum(trainMatrix[i]) 164 else: 165 pNotADNum += trainMatrix[i] 166 pNotADDenom += sum(trainMatrix[i]) 167 168 pADVect = log(pADNum / pADDenom) 169 pNotADVect = log(pNotADNum / pNotADDenom) 170 171 return pADVect, pNotADVect, pClassAD 172 173 ''' 174 將輸入轉化為向量,其所在空間維度為 len(listVocab) 175 params: 176 listVocab-詞集 177 inputSet-分詞後的文字,儲存於set 178 ''' 179 def bagOfWords2VecMN(listVocab, inputSet): 180 returnVec = [0]*len(listVocab) 181 for word in inputSet: 182 if word in listVocab: 183 returnVec[listVocab.index(word)] += 1 184 return returnVec 185 186 ''' 187 讀取儲存的模型,做分類操作 188 ''' 189 def adClassify(text): 190 fr = open("args.pkl", "rb") 191 args = pickle.load(fr) 192 pADV = args['pADV'] 193 pNotADV = args['pNotADV'] 194 pClassAD = args['pClassAD'] 195 fr.close() 196 197 fr = open("vocab.pkl", "rb") 198 listVocab = pickle.load(fr) 199 fr.close() 200 201 if len(listVocab) == 0: 202 print "got no args" 203 return 204 205 text = textParse(text, False) 206 vecWord = bagOfWords2VecMN(listVocab, text) 207 class_type = classifyNaiveBayes(array(vecWord), pADV, pNotADV, pClassAD) 208 209 print "classfication type:%d" % class_type 210 211 212 if __name__ == "__main__": 213 loadStopword() 214 while True: 215 opcode = raw_input("input 1 for training, 2 for ad classify: ") 216 if opcode.strip() == "1": 217 begtime = time.time() 218 testClassify() 219 print "cost time total:", time.time() - begtime 220 else: 221 text = raw_input("input the text:") 222 adClassify(text) 223
程式碼測試效果:
1、訓練。
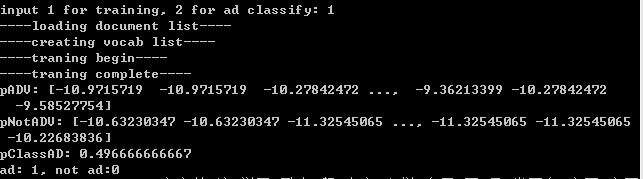

2、例項測試。
分類為1則歸為廣告,0為普通文字。

p.s.
此分類器的準確率,其實是比較依賴於訓練語料的,機器學習演算法就和純潔的小孩一樣,取決於其成長(訓練)條件,“吃的是草擠的是奶”,但,“不是所有的牛奶,都叫特侖蘇”。
轉自:http://www.cnblogs.com/marc01in/p/4775440.html
相關推薦
樸素貝葉斯演算法 & 應用例項
一、樸素貝葉斯演算法介紹 樸素貝葉斯,之所以稱為樸素,是因為其中引入了幾個假設(不用擔心,下文會提及)。而正因為這幾個假設的引入,使得模型簡單易理解,同時如果訓練得當,往往能收穫不錯的分類效果,因此這個系列以naive bayes開頭和大家見面。 因為樸素貝葉斯是貝葉
樸素貝葉斯演算法應用——垃圾簡訊分類
理解貝葉斯公式其實就只要掌握:1、條件概率的定義;2、乘法原理 P (
R語言之樸素貝葉斯演算法應用
樸素貝葉斯演算法在R語言中的應用,對應klaR包中的NaiveBayes()方法。問題描述:主要通過樸素貝葉斯演算法對於測試資料集中的nmkat屬性值進行預測,我們使用的資料是KKNN包中的自帶資料m
資料探勘十大演算法(九):樸素貝葉斯原理、例項與Python實現
一、條件概率的定義與貝葉斯公式 二、樸素貝葉斯分類演算法 樸素貝葉斯是一種有監督的分類演算法,可以進行二分類,或者多分類。一個數據集例項如下圖所示: 現在有一個新的樣本, X = (年齡:<=30, 收入:中, 是否學生:是, 信譽:中),目標是利用樸素貝
sk-learn例項-用樸素貝葉斯演算法(Naive Bayes)對文字進行分類
簡介 樸素貝葉斯(Naive Bayes)是一個非常簡單,但是實用性很強的分類模型,與基於線性假設的模型(線性分類器和支援向量機分類器)不同,樸素貝葉斯分類器的構造基礎是貝葉斯理論。 抽象一些的說,樸素貝葉斯分類器會單獨考量每一維度特徵被分類的條件概率,進而綜合這些概率並對其所在的特
樸素貝葉斯演算法的程式碼例項實現(python)
本文由本人原創,僅作為自己的學習記錄 資料:假設下面是課程資料,課程資料分為,價格A,課時B,銷量C 價格A 課時B 銷量C 低 多 高 高 中 高 低 少 高 低 中 低 中 中
小白python學習——機器學習篇——樸素貝葉斯演算法
一.大概思路: 1.找出資料集合,所有一個單詞的集合,不重複,各個文件。 2.把每個文件換成0,1模型,出現的是1,就可以得到矩陣長度一樣的各個文件。 3.計算出3個概率,一是侮辱性的文件概率,二是侮辱性文件中各個詞出現的概率,三是非侮辱性文件中各個詞出現的概率。 4.二、三計算方法
樸素貝葉斯演算法原理
(作者:陳玓玏) 1. 損失函式 假設我們使用0-1損失函式,函式表示式如下: Y Y Y為真實
機器學習——樸素貝葉斯演算法
概率定義為一件事情發生的可能性 概率分為聯合概率和條件概率 聯合概率:包含多個條件,且所有條件同時成立的概率 記作:P(A,B) P(A,B)=P(A)P(B) 條件概率:就是事件A在另外一個事件B已經發生的條件概率 記作:P(A|B)
機器學習實踐(九)—sklearn之樸素貝葉斯演算法
一、樸素貝葉斯演算法 什麼是樸素貝葉斯分類方法 屬於哪個類別概率大,就判斷屬於哪個類別 概率基礎 概率定義為一件事情發生的可能性 P(X) : 取值在[0, 1] 聯合概率、條件概率與相互獨立
樸素貝葉斯演算法優化與 sklearn 實現
1. 引言 上一篇日誌中,我們主要介紹了貝葉斯演算法,並提供了 python 實踐: 樸素貝葉斯演算法的推導與實踐 但執行上一篇日誌中的示例,我們發現出現了下面的結果: ['love', 'my', 'dalmation'] 屬於非侮辱類 ['stu
樸素貝葉斯演算法的推導與實踐
1. 概述 在此前的文章中,我們介紹了用於分類的演算法: k 近鄰演算法 決策樹的構建演算法 – ID3 與 C4.5 演算法 但是,有時我們無法非常明確地得到分類,例如當資料量非常大時,計算每個樣本與預測樣本之間的距
機器學習——樸素貝葉斯演算法Python實現
簡介 這裡參考《統計學習方法》李航編進行學習總結。詳細演算法介紹參見書籍,這裡只說明關鍵內容。 即 條件獨立下:p{X=x|Y=y}=p{X1=x1|Y=y} * p{X2=x2|Y=y} *...* p{Xn=xn|Y=y} (4.4)等價於p{Y=ck|X=x
第3章 樸素貝葉斯演算法 (二 演算法實戰)
3.6樸素貝葉斯實踐 3.6.1樸素貝葉斯之微博評論篩選 以微博評論為例。為了不影響微博的發展,我們要遮蔽低俗的言論,所以要構建一個快速過濾器,如果某條評論使用了負面或者侮辱性等低俗的語言,那麼就將該留言標誌為內容不當。過濾這類內容是一個很常見的需求。對此問題建
機器學習樸素貝葉斯演算法
樸素貝葉斯屬於監督學習的生成模型,實現簡單,沒有迭代,學習效率高,在大樣本量下會有較好表現。但因為假設太強——特徵條件獨立,在輸入向量的特徵條件有關聯的場景下,並不適用。 樸素貝葉斯演算法:主要思路是通過聯合概率建模,運用貝葉斯定理求解後驗概率;將後驗概率最大者對應的類別作
【ML學習筆記】樸素貝葉斯演算法的demo(機器學習實戰例子)
礙於這學期課程的緊迫,現在需要儘快從課本上掌握一些ML演算法,我本不想經過danger zone,現在看來卻只能儘快進入danger zone,數學理論上的缺陷只能後面找時間彌補了。 如果你在讀這篇文章,希望你不要走像我一樣的道路,此舉實在是出於無奈,儘量不要去做一個心
貝葉斯演算法及例項python實現
目錄 計算過程: 貝葉斯簡介: 貝葉斯(約1701-1761) Thomas Bayes,英國數學家 貝葉斯方法源於他生前為解決一個“逆概”問題寫的一篇文章。 貝葉斯要解決的問題: 正向概率:假設袋子裡面有N個白球,M個黑球,你
樸素貝葉斯演算法的python實現
import numpy as np import re #詞表到向量的轉換函式 def loadDataSet(): postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please']
2.樸素貝葉斯演算法
樸素貝葉斯程式碼(原理很簡單) 直接上程式碼 import numpy as np from collections import Counter,defaultdict class Nbayes: def __init__(self): self
樸素貝葉斯演算法-My way of ML7
預備知識 聯合概率:包含多個條件,所有條件同時成立概率P(A,B)=P(A)P(B) 條件概率:事件A發生在事件B發生的條件之下的概率。所有的特徵值無關的時候才能適用條件概率 樸素貝葉斯的前提是: 特徵條件獨立,哈哈,這也是她被叫做樸素的原因,因為特徵之間很難獨