
浮點數在計算機中儲存方式
C語言和C#語言中,對於浮點型別的資料採用單精度型別(float)和雙精度型別(double)來儲存,float資料佔用32bit,double資料佔用64bit,我們在宣告一個變數float f= 2.25f的時候,是如何分配記憶體的呢?如果胡亂分配,那世界豈不是亂套了麼,其實不論是float還是double在儲存方式上都是遵從IEEE的規範的,float遵從的是IEEE R32.24 ,而double 遵從的是R64.53。
無論是單精度還是雙精度在儲存中都分為三個部分:
- 符號位(Sign) : 0代表正,1代表為負
- 指數位(Exponent):用於儲存科學計數法中的指數資料,並且採用移位儲存
- 尾數部分(Mantissa):尾數部分
其中float的儲存方式如下圖所示:
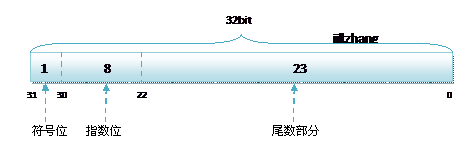
而雙精度的儲存方式為:

| S | E | M | 表示公式 | 偏移量 | |
|
單精度浮點數 |
1(第31位) |
8(30到23位) |
23(22到0位) |
(-1)^S*2(E-127)*1.M |
127 |
|
雙精度浮點數 |
1(第63位) |
11(62到52位) |
52(51到0位) |
(-1)^S*2(E-1023)*1.M |
1023 |
M為尾數,其中單精度數為23位長,雙精度數為52位長。IEEE標準要求浮點數必須是規範的。這意味著尾數的小數點左側必須為1,因此在儲存尾數的時候,可以省略小數點前面這個1,從而騰出一個二進位制位來儲存更多的尾數。這樣實際上用23位長的尾數域表達了24位的尾數。例如對於單精度數而言,二進位制的1001.101(對應於十進位制的9.625)可以表達為1.001101 × 23,所以實際儲存在尾數域中的值為00110100000000000000000,即去掉小數點左側的1,並用0在右側補齊。
根據標準要求,無法精確儲存的值必須向最接近的可儲存的值進行舍入,即不足一半則舍,一半以上(包括一半)則進。不過對於二進位制浮點數而言,還多一條規矩,就是當需要舍入的值剛好是一半時,不是簡單地進,而是在前後兩個等距接近的可儲存的值中,取其中最後一位有效數字為零者。
據以上分析,IEEE 754標準中定義浮點數的表示範圍為:
|
二進位制(Binary) |
十進位制(Decimal) |
|
|
單精度浮點數 |
± (2-2^-23) × 2127 |
~ ± 10^38.53 |
|
雙精度浮點數 |
± (2-2^-52) × 21023 |
~ ± 10^308.25 |
1、當P=0,M=0時,表示0。
2、當P=255,M=0時,表示無窮大,用符號位來確定是正無窮大還是負無窮大。
3、當P=255,M≠0時,表示NaN(Not a Number,不是一個數)。
R32.24和R64.53的儲存方式都是用科學計數法來儲存資料的,比如8.25用十進位制的科學計數法表示就為:8.25*![]() ,而120.5可以表示為:1.205*
,而120.5可以表示為:1.205*![]() ,這些小學的知識就不用多說了吧。而我們傻蛋計算機根本不認識十進位制的資料,他只認識0,1,所以在計算機儲存中,首先要將上面的數更改為二進位制的科學計數法表示,8.25用二進位制表示可表示為1000.01,我靠,不會連這都不會轉換吧?那我估計要沒轍了。120.5用二進位制表示為:1110110.1用二進位制的科學計數法表示1000.01可以表示為1.0001*
,這些小學的知識就不用多說了吧。而我們傻蛋計算機根本不認識十進位制的資料,他只認識0,1,所以在計算機儲存中,首先要將上面的數更改為二進位制的科學計數法表示,8.25用二進位制表示可表示為1000.01,我靠,不會連這都不會轉換吧?那我估計要沒轍了。120.5用二進位制表示為:1110110.1用二進位制的科學計數法表示1000.01可以表示為1.0001*![]() ,1110110.1可以表示為1.1101101*
,1110110.1可以表示為1.1101101*![]() ,任何一個數都的科學計數法表示都為1.xxx*
,任何一個數都的科學計數法表示都為1.xxx*![]() ,尾數部分就可以表示為xxxx,第一位都是1嘛,幹嘛還要表示呀?可以將小數點前面的1省略,所以23bit的尾數部分,可以表示的精度卻變成了24bit,道理就是在這裡,那24bit能精確到小數點後幾位呢,我們知道9的二進位制表示為1001,所以4bit能精確十進位制中的1位小數點,24bit就能使float能精確到小數點後6位,而對於指數部分,因為指數可正可負,8位的指數位能表示的指數範圍就應該為:-127-128了,所以指數部分的儲存採用移位儲存,儲存的資料為元資料+127,下面就看看8.25和120.5在記憶體中真正的儲存方式。
,尾數部分就可以表示為xxxx,第一位都是1嘛,幹嘛還要表示呀?可以將小數點前面的1省略,所以23bit的尾數部分,可以表示的精度卻變成了24bit,道理就是在這裡,那24bit能精確到小數點後幾位呢,我們知道9的二進位制表示為1001,所以4bit能精確十進位制中的1位小數點,24bit就能使float能精確到小數點後6位,而對於指數部分,因為指數可正可負,8位的指數位能表示的指數範圍就應該為:-127-128了,所以指數部分的儲存採用移位儲存,儲存的資料為元資料+127,下面就看看8.25和120.5在記憶體中真正的儲存方式。
首先看下8.25,用二進位制的科學計數法表示為:1.0001*![]()
按照上面的儲存方式,符號位為:0,表示為正,指數位為:3+127=130 ,位數部分為,故8.25的儲存方式如下圖所示:
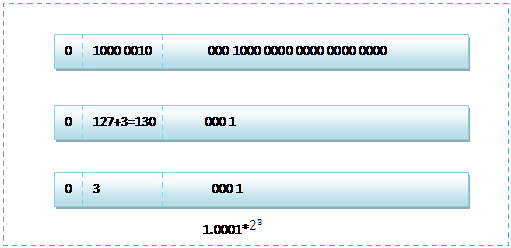
而單精度浮點數120.5的儲存方式如下圖所示:
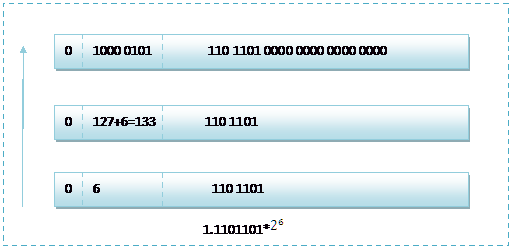
那麼如果給出記憶體中一段資料,並且告訴你是單精度儲存的話,你如何知道該資料的十進位制數值呢?其實就是對上面的反推過程,比如給出如下記憶體資料:0100001011101101000000000000,首先我們現將該資料分段,0 10000 0101 110 1101 0000 0000 0000 0000,在記憶體中的儲存就為下圖所示:
![]()
根據我們的計算方式,可以計算出,這樣一組資料表示為:1.1101101*![]() =120.5
=120.5
而雙精度浮點數的儲存和單精度的儲存大同小異,不同的是指數部分和尾數部分的位數。所以這裡不再詳細的介紹雙精度的儲存方式了,只將120.5的最後儲存方式圖給出,大家可以仔細想想為何是這樣子的
![]()
下面我就這個基礎知識點來解決一個我們的一個疑惑,請看下面一段程式,注意觀察輸出結果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能輸出的結果讓大家疑惑不解,單精度的2.2轉換為雙精度後,精確到小數點後13位後變為了2.2000000476837,而單精度的2.25轉換為雙精度後,變為了2.2500000000000,為何2.2在轉換後的數值更改了而2.25卻沒有更改呢?很奇怪吧?其實通過上面關於兩種儲存結果的介紹,我們已經大概能找到答案。首先我們看看2.25的單精度儲存方式,很簡單 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的雙精度表示為:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,這樣2.25在進行強制轉換的時候,數值是不會變的,而我們再看看2.2呢,2.2用科學計數法表示應該為:將十進位制的小數轉換為二進位制的小數的方法為將小數*2,取整數部分,所以0.282=0.4,所以二進位制小數第一位為0.4的整數部分0,0.4×2=0.8,第二位為0,0.8*2=1.6,第三位為1,0.6×2 = 1.2,第四位為1,0.2*2=0.4,第五位為0,這樣永遠也不可能乘到=1.0,得到的二進位制是一個無限迴圈的排列 00110011001100110011... ,對於單精度資料來說,尾數只能表示24bit的精度,所以2.2的float儲存為:
![]()
但是這樣儲存方式,換算成十進位制的值,卻不會是2.2的,應為十進位制在轉換為二進位制的時候可能會不準確,如2.2,而double型別的資料也存在同樣的問題,所以在浮點數表示中會產生些許的誤差,在單精度轉換為雙精度的時候,也會存在誤差的問題,對於能夠用二進位制表示的十進位制資料,如2.25,這個誤差就會不存在,所以會出現上面比較奇怪的輸出結果。
相關推薦
浮點數在計算機中儲存方式
C語言和C#語言中,對於浮點型別的資料採用單精度型別(float)和雙精度型別(double)來儲存,float資料佔用32bit,double資料佔用64bit,我們在宣告一個變數float f= 2.25f的時候,是如何分配記憶體的呢?如果胡亂分配,那世界豈不是亂套
浮點數在計算機中儲存的方式
浮點數在計算機中的儲存 1996年6月4日,歐洲最新的無人駕駛火箭Ariane5初次航行時,發射後僅37秒,火箭偏離了它的飛行路徑,解體並且爆炸。火箭上載有價值5億美元的通訊衛星。科學家們進行調查之後,原來只是因為小小的浮點數導致這場災難性的後果,白白地損失了
浮點數除法中零的問題
1如果除法運算子的兩個運算數都是整數,則除數不可以為0,否則會引發除零異常。 如:int a = 3/0; //將會出現異常 2如果除法運演算法的兩個運算數有1個浮點數,或者有兩個浮點數,則運算結果也是浮點數。而且此時允許除數為0、或者除數為0.0,得
浮點數的記憶體儲存
今天我們來探討一下浮點數的記憶體存儲存! 先來看一個例子: int main() { int a = 9; float *p = (float*)&a; printf("%d\n", a);//以有符號十進位制整形方式列印 printf("%f\n", *p);//以有符號十
浮點數(實數)中單精度與雙精度區別
#在記憶體中儲存格式的區別: folat單精度:1位訊號(0為正1為負),8位1位元組為指數,最後23位為小數部分 ##double雙精度:1位訊號(0為正1為負),11位為指數,最後23位為小數部分 從儲存的不同可以看出單精度在長度上已經小雙精度一倍,當對資料型別的精度要求不高(±3X
計算機中儲存、網路傳輸計量單位
目錄 1.儲存單位 1.1.位 1.2.位元組 1.3.字 1.4.兩種計量單位 1.5.硬碟縮水原因 2.網路傳輸單位 2.1.服務商單位 2.2.軟體單位 2.3.解釋20M寬頻實際下載速度 1.儲存單位 1.1.位 英文bit,又稱“
java浮點數除法中零的問題
1,浮點數除法中零的問題 1.1如果除法運算子的兩個運算數都是整數,則除數不可以為0,否則會引發除零異常。 如:int a = 3/0; //將會出現異常 1.2如果除法運演算法的兩個運算
計算機中儲存單位的認識與理解
計算機上的資訊儲存單位與日常生活中計算單位存在很大的差別,易於導致相關概念的混淆,而且認識這些對測試計算機效能具有很重要的意義。 一. 計算機資訊儲存單位 計算機資訊用二進位制的形式表示常用的單位有 位、字以及位元組。它也是儲存器儲存資訊的最小單位,通常
JavaScript數據在內存中儲存方式
tac null string 其中 num light 包括 變量 基本數據類型 詳情來源於個本人博客: https://shengchangwei.github.io/al-data/ > Js的數據類型包括兩種: 基本數據類型:String、Boolea
浮點數在計算機中的儲存方式
C語言和 C#語言中,對於浮點型的資料採用單精度型別(float)和雙精度型別(double)來儲存: float 資料佔用 32bit; double 資料佔用 64bit; 我們在宣告一個變數 float f = 2.25f 的時候,是如何分配記憶體的呢? 其實不
浮點數在計算機記憶體中的儲存方式。
浮點數在計算機記憶體中的儲存方式 整數在計算機記憶體中是以其二進位制的原碼,補碼和反碼來表示的,其中正數的
計算機中浮點數的儲存方式
參考網址:http://blog.chinaunix.net/uid-28458801-id-3507427.html 根據國際標準IEEE 754,任意一個二進位制浮點數V可以表示成下面的形式: V = (-1)^s×M×2^E (1)(-1)^s表示符號位,當s
【C語言中的細節問題】C/C++浮點數在記憶體中的儲存方式
C/C++浮點數在記憶體中的儲存方式 本文轉載自:https://www.cnblogs.com/dolphin0520/archive/2011/10/02/2198280.html 任何資料在記憶體中都是以二進位制
C語言中浮點數在內存中的存儲方式
大端 部分 由於 包含 指數 類型 計算機 data- trac 關於多字節數據類型在內存中的存儲問題 //////////////////////////////////////////////////////////////// int ,short 各
[算法]浮點數在內存中的存儲方式
www. sig 後者 mage 工具 32bit alt iss bits float型變量占用32bit,即4個byte的內存空間 我們先來看下浮點數二進制表達的三個組成部分。 三個主要成分是: Sign(1bit):表示浮點數是正數還是負數。0表示正數,1表示負數
c/c++浮點數在內存中存儲方式
十進制 .html 但是 指針 單元 sin namespace short space 轉自:https://www.cnblogs.com/dolphin0520/archive/2011/10/02/2198280.html 任何數據在內存中都是以二進制的形式存儲的,
浮點數在記憶體中的儲存
浮點數在記憶體中的儲存 浮點數家族:float,double,long double型別. 同一個數為啥差別這麼大?想知道為神馬?請讀下文。 詳細解讀: 1.根據國際標準IEEE(電氣和電子工程協會)754,任意一個二進位制浮點數V可以
深入理解計算機系統(2.8)---浮點數的舍入,Java中的舍入例子以及浮點數運算(重要)
https://www.cnblogs.com/zuoxiaolong/p/computer12.html 前言 上一章我們簡單介紹了IEEE浮點標準,本次我們主要講解一下浮點運算舍入的問題,以及簡單的介紹浮點數的運算。 之前我們已經提到過,有很多小數是二進位制
計算機中浮點數的表示,IEEE 754標準
IEEE Standard for Floating-Point Arithmetic(IEEE 754,Institute of Electrical and Electronics Engineers)是1985年建立的浮點數計算的技術標準。解決了原來浮點數實現不一致的問題,許多硬體
整數,浮點數在記憶體中的儲存形式
一 整數在記憶體中的儲存形式 整數在記憶體中以補碼形式儲存,詳細原因見原碼,反碼,補碼。 主要原因是使用補碼可以將符號位與數值域統一處理,同時,加法和減法也可以統一處理 (cpu只有加法器),此外,補碼與原碼的轉化,其運算過程是相同的,不需要額外的硬體電路。 如上