
產品健康度模型(4) 打分I
產品健康度模型之打分I
在這個專案上,大家可能會發現,很多做法比較主觀,但是原因我認為”健康度“本身就是一個主觀概念,哪裡去找真正的”產品健康度“呢?這和離網使用者分析就形成了鮮明的對比,離網使用者預測準確率就是一個客觀數值,而健康度打分,什麼是好,什麼是不好,很難界定(如果真的需要所謂實際值,那就需要大量的調研反饋,那對企業來說又是不可接受的),所以說問題本身很難形式化成一個典型的機器學習問題——這也是我在這個專案中最困擾的地方。
但是,在處理的時候,我們在經驗範圍內不做蠢事,這就是最好的結果啦——但求問心無愧唄!
根據指標記錄打分
按照對方的要求,我們還是需要根據每個指標給出一個打分(也就是說對於新來的指標值,要給出其打分)。
這裡舉一個實際的例子,比如對於簡訊接收延時這個指標(現在我們僅僅考慮只有一個使用者),比如第一期指標有三個值
首先一點,技術人員告訴我們(不告訴也可以想見)簡訊接收的延時是越小越好,也就是說這個指標和健康度在大小上是負相關的。
然後我們怎麼根據一系列的歷史值來給出現在的打分呢?接下來我們要明確兩個要點和一個觀察。
打分的要點和觀察
要點一,利用歷史記錄進行打分,也就是說從指標值到分數的打分對映要從歷史記錄中算出來。
要點二,不能存在滿分和零分的情況,因為如果出現了比滿分值更好或者更壞的情況,分數豈不是要溢位?也就是說,對於“極好”的指標值,我們可以給一個接近滿分的打分,但是不能打滿分。並且要交代的是,這邊的模型不是“線上”的,也就是,實時產生的指標並不參與打分對映的建模,我們用來建立打分對映的只能是庫中的
觀察:使用者對指標變化造成的感知不是均勻變化的,這裡我們用一張表來闡述這個問題:
| 延時(s) | 0.2 | 0.5 | 0.9 | 1.2 | 3.0 | 5.7 | 8.5 | 10.2 | 15.6 | 23.8 | 38.9 | 78.0 | 126.9 | 230.2 | 328.7 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 打分 | 4.8 | 4.8 | 4.6 | 4.3 | 3.9 | 3.6 | 3.2 | 2.8 | 2.8 | 2.7 | 2.7 | 2.6 | 2.5 | 2.5 | 2.2 |
從表中我們可以看出,延時的變化導致打分的變化並不是均勻的,1s——10s這一段區間是“敏感區”,不管是從1s變化到3s,還是6s變化到8s,使用者對延時的變化都很敏感,而到了10秒往後,使用者的體驗變化就不那麼敏感了,即使是幾十秒的延時差距,使用者的打分變化不大。如下圖:
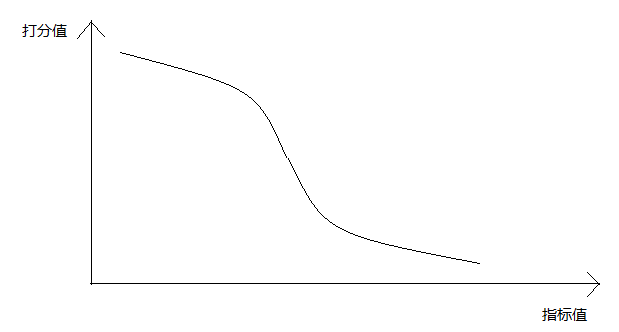
從使用者的角度分析,我們可以這樣理解:當延時在10秒以內的時候,使用者對延時的感知比較敏感,而過了這個區間,使用者的感覺反正是延時太大,幾十秒到幾分鐘的時差對使用者來說反而不重要了:
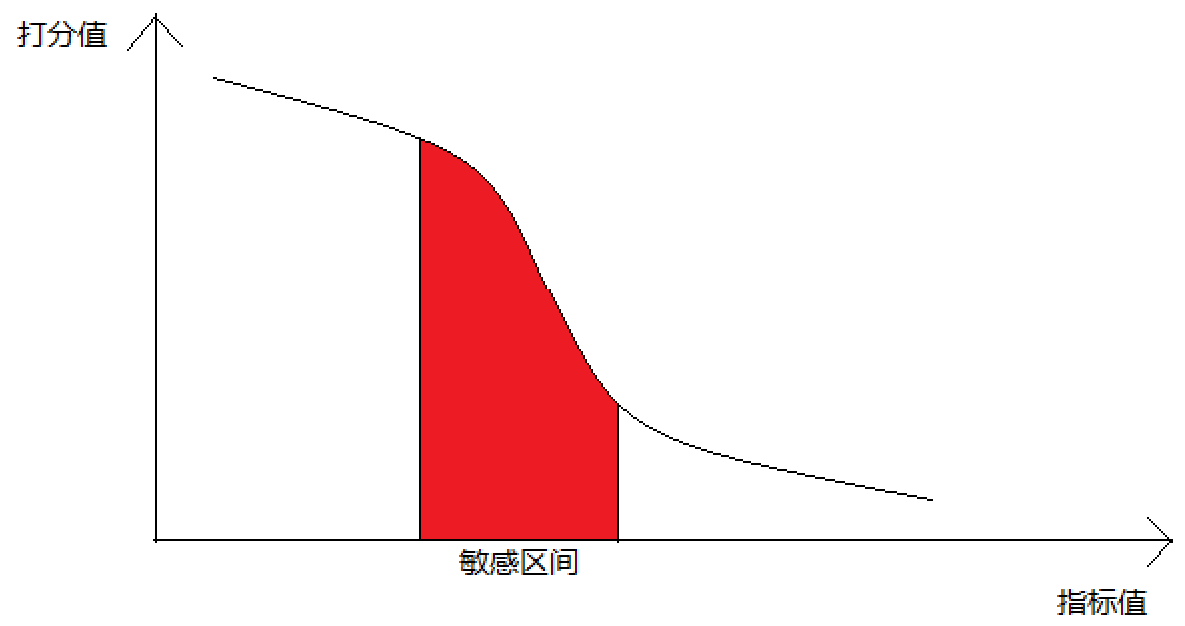
這裡我們為什麼要從使用者體驗的角度去分析呢,因為唯一可能和使用者的營銷指標(使用量,消費量)相關的就是使用者的使用體驗,當然,其他因素一是不可控,而是在運維指標中也無從反映。
不難看出,指標值和打分分值的曲線類似於一個三次曲線,但是如果我們真的用三次曲線去模擬存在兩個缺陷:1. 沒有打分樣本進行建模,2. 並不是所有的指標都存在這種模式。
我們考慮的做法是擬合樣本的分佈來打分:分值就是樣本的積分值,這樣做滿足了要點一和要點二了,但是怎麼滿足我們對使用者指標敏感度的觀察呢?
在指標分析的過程中我們發現一個規律:使用者對指標敏感的區域,往往也是使用者指標分佈比較密集的區域。
比如對於簡訊延時指標,其概率分佈如下圖:
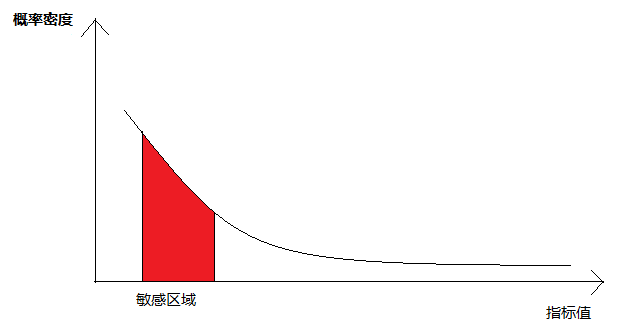
更多的指標分佈滿足這樣的分佈:
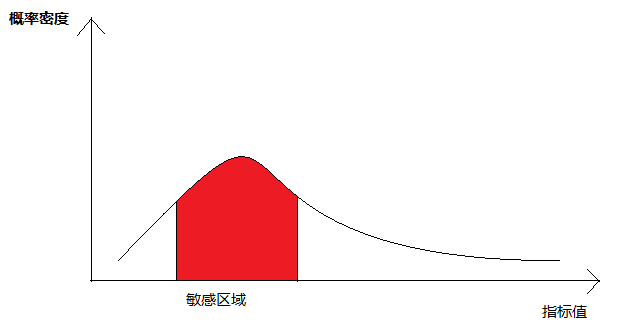
對概率密度進行積分,我們可以返現其大概的形狀都是:
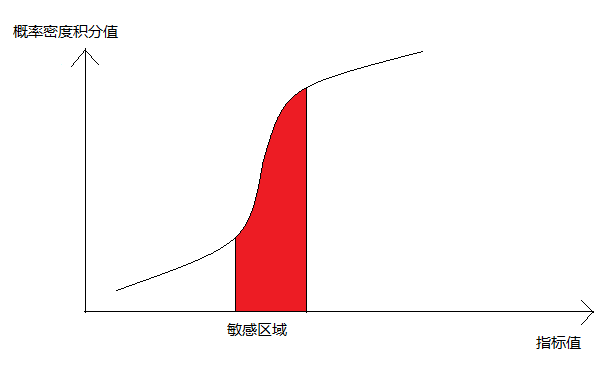
上面的圖和我們的打分圖的形狀已經很相似了,如果考慮到指標和使用者滿意度的負相關關係,把圖做一下左右手的映象,就是一樣的曲線了。
這裡之所以說“大概的形狀”,是因為對於我們的簡訊時間延時的例子,指標值較小時對應的平坦的部分就是不存在的,其概率密度積分函式如下圖:
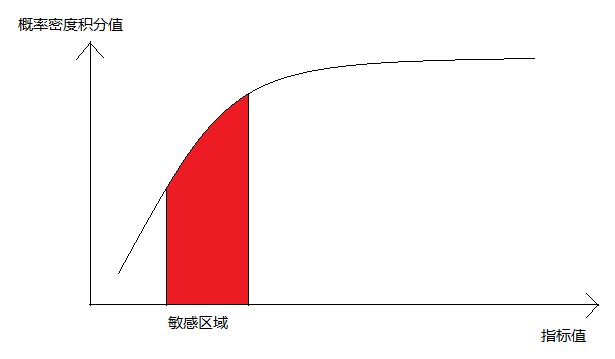
但是該圖作為打分函式的近似也是可以的,為什麼呢?——還是敏感區域的問題,因為真正會影響健康度的就是敏感區域的指標變化,那麼如果我們的模型對敏感區域足夠敏感就行(而敏感區域的樣本密度大這一特性保證了這一性質的成立),至於其他區域的打分,只要滿足正負的相關關係以及不要讓模型打分溢位就行了。
核密度估計
我們的思想已經明確,擬合樣本的分佈,然後計算概率密度的積分,然後用積分作為打分(當然要配合正負相關的知識)。
當然,還不能出現滿分的情況,這裡我們選擇的方法是“核密度估計”(kernel density estimation),也叫Parzen窗方法。其具體內容可以參照維基百科。
為了說明問題,我們還是把公式放上來:
其中
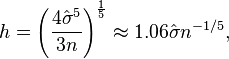
這裡需要說明的是,為了防止分數溢位,我們選擇的是高斯核函式,至於頻寬,我們選擇是相對來說較小的頻寬(理想值的1/8)——因為太大的頻寬將會使我們損失更多的樣本分佈的資訊,而由於樣本量很大,我們並不怕模型產生多大的variance。
總結
利用基於高斯核函式的核密度估計,我們就滿足了所有打分的要點和觀察。
相關推薦
產品健康度模型(4) 打分I
產品健康度模型之打分I 在這個專案上,大家可能會發現,很多做法比較主觀,但是原因我認為”健康度“本身就是一個主觀概念,哪裡去找真正的”產品健康度“呢?這和離網使用者分析就形成了鮮明的對比,離網使用者預測準確率就是一個客觀數值,而健康度打分,什麼是好,什麼是
產品健康度模型(2) KPI、KQI
產品健康度模型之KPI、KQI 這一節我們介紹運營商面對這些指標通常的做法,我們健康度模型的可行性,以及我們預備怎麼做。 原來他們怎麼做? 原來運營商怎麼解決這個問題呢?說白了兩個字——人工。 對於一眾運維指標,首先每個指標就是一個KPI
產品健康度模型(3) 指標關聯性分析
產品健康度模型之指標關聯性分析 我們這裡做關聯性分析的目的就是找出運維指標和運營指標的相關程度。這裡重新貼一下指標的結構圖: 指標離散化 這裡需要說明的是,這些指標可能是連續的,也有可能是離散的,比如我們有運維指標a,b,c,以
Reading_演算法_灰度模型(GM)
灰度系統理論及其應用 問:為什麼要用灰度系統理論,其主要分析方法是什麼 答:灰度系統就是白箱和黑箱之間的系統,現有的系統分析的量化方法,大都是數理統計法如迴歸分析、方差分析、主成分分析等,迴歸分析是應用最廣泛的一種辦法。但迴歸分析要求大樣本,只有通過大量的資料才能得到化的規律,
序列模型(4)----門控迴圈單元(GRU)
一、GRU 其中, rt表示重置門,zt表示更新門。 重置門決定是否將之前的狀態忘記。(作用相當於合併了 LSTM 中的遺忘門和傳入門) 當rt趨於0的時候,前一個時刻的狀態資訊ht−1會被忘掉,隱藏狀態h^t會被重置為當前輸入的資訊。 更新門決定是否要將隱藏狀態更新為新的狀態h^
深度探索C++物件模型(4)——物件(4)——拷貝建構函式語義
傳統認識認為:如果我們沒有定義一個自己的拷貝建構函式,編譯器會幫助我們合成 一個拷貝建構函式。 結論:這個合成的拷貝建構函式,也是在 必要的時候才會被編譯器合成出來。 示例程式碼 class A { public
HotSpot的類模型(4)
我們繼續接著上一篇 HotSpot的類模型(3)分析,這次主要分析表示java陣列的C++類。 4、ArrayKlass類 ArrayKlass繼承自Klass,是所有陣列類的抽象基類,類及重要屬性的定義如下: class ArrayKlass: public Klass
Java Web 深入分析(4) Java I/O 深入分析
lock 異步 瓶頸 系統 基本結構 java 同步異步 nio -i I/O問題可以說是現在大部分web系統的瓶頸。我們要了解的java I/O(後面簡稱為(io)) io類庫的基本結構 -磁盤io的工作機制 -網絡io的工作機制 -NIO的工作方式 -同步異步、阻
基於Qt的OpenGL可編程管線學習(4)- 使用Subroutine繪制不同光照的模型
qt opengl shader subroutine 使用Subroutine在shader中封裝不同的函數,在CPU端選擇調用那個函數效果如下圖所示左側:環境光中間:環境光 + 漫反射右側:環境光 + 漫反射 + 高光1、Subroutine 在shader中的內容subroutine v
4.前端基於react,後端基於.net core2.0的開發之路(4) 前端打包,編譯,路由,模型,服務
hub 解決 路徑 export routes run 部署 service 後端 1.簡要的介紹 學習react,首先學習的就是javascript,然後ES6,接著是jsx,通常來說如果有javascript的基礎,上手非常快,但是真正要搭建一個前端工程化項目,還是有很
產品方法論總結(4)——痛點、癢點、爽點
發送 比較 電影 社交 提高 bsp 需求 畫像 照片 產品的抓手,主要在於痛點和爽點。前面也提到了痛點即為恐懼,對於用戶而言是剛需,爽點為即時滿足,對用戶而言是興奮點,能讓用戶達到體驗值的高潮,而這裏也提到的癢點是滿足虛擬自我,例如,網紅產品,靠的就不是痛點和爽
目標檢測之模型篇(4)【EAST】
文章目錄 1. 前言 2. 實現 2.1 Pipeline 2.2 網路設計 2.3 標籤生成 2.4 損失函式 2.5 訓練 2.6 位置感知的NMS 3. 結果 4. 總結 5.
模糊控制——(4)Sugeno模糊模型
1、Sugeno模糊模型 傳統的模糊系統為Mamdani模糊模型,輸出為模糊量。 Sugeno模糊模型輸出隸屬函式為constant或linear,其函式形式為:
Android studio3.0對於百度地圖api開發(4)——百度地圖地圖覆蓋物製作
承接上文未完的繼續介紹,上文內容:https://blog.csdn.net/qq_41562408/article/details/82810484主要實現百度地圖的定位以及對於地圖覆蓋物進行簡單介紹,這篇文章便是對於地圖覆蓋物進行,經過閱讀開發文件,我們會發
深度學習模型壓縮方法(4)-----模型蒸餾(Distilling)與精細模型網路
前言 在前兩章,我們介紹了一些在已有的深度學習模型的基礎上,直接對其進行壓縮的方法,包括核的稀疏化,和模型的裁剪兩個方面的內容,其中核的稀疏化可能需要一些稀疏計算庫的支援,其加速的效果可能受到頻寬、稀疏度等很多因素的制約;而模型的裁剪方法則比較簡單明瞭,直接在原有的模型上剔
pytorch基礎(4)-----搭建模型網路的方法
方法一:採用torch.nn.Module模組 import torch import torch.nn.functional as F #法1 class Net(torch.nn.Module): def __init__(self,n_feature,n_hidden,n_o
資料結構和演算法(4)-----演算法的時間複雜度和空間複雜度
1.演算法的時間複雜度定義 在進行演算法分析時,語句總的執行次數T(n)是關於問題規模n的函式,進而分析T(n)隨n的變化情況並確定T(n)的數量級。演算法的時間複雜度,也就是演算法的時間量度。記作:T(n)=O(f(n))。它表示隨問題n的增大,演算法執行時間的增長率和f(n)的增
Asp.Net MVC4入門指南(4):新增一個模型
在本節中,您將新增一些類,這些類用於管理資料庫中的電影。這些類是ASP.NET MVC 應用程式中的"模型(Model)"。 您將使用.NET Framework 資料訪問技術Entity Framework,來定義和使用這些模型類。Entity Framework(通常稱為 EF) 是支援程式碼優先的開發
【機器學習-斯坦福】學習筆記4 ——牛頓方法;指數分佈族; 廣義線性模型(GLM)
牛頓方法 本次課程大綱: 1、 牛頓方法:對Logistic模型進行擬合 2、 指數分佈族 3、 廣義線性模型(GLM):聯絡Logistic迴歸和最小二乘模型 複習: Logistic迴歸:分類演算法 假設給定x以為引數的y=1和y=0的概率:
深度學習tensorflow實戰筆記(4)利用儲存的VGG-16CNN網路模型提取特徵
前幾篇部落格寫了如何處理資料,如何把用自己的資料訓練VGG-16,如何把訓練好的模型儲存。而在實際應用中,並不是所有的操作都是為了分類的,有時候需要提取影象的特徵,那麼怎麼利用已經儲存的模型提取特徵呢? “桃葉兒尖上尖,柳葉兒就遮滿了天” 測試資料轉換成tf