
產品健康度模型(3) 指標關聯性分析
產品健康度模型之指標關聯性分析
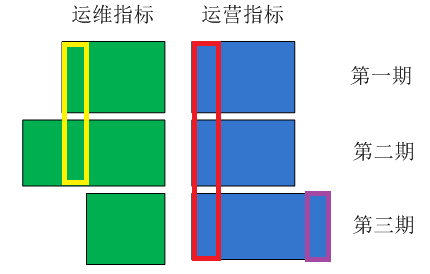
我們這裡做關聯性分析的目的就是找出運維指標和運營指標的相關程度。這裡重新貼一下指標的結構圖:
指標離散化
這裡需要說明的是,這些指標可能是連續的,也有可能是離散的,比如我們有運維指標
當然,我們完全可以分情況討論,對於離散VS離散、離散VS連續、連續VS連續指標分別採用不同的關聯性分析的方法,但是分別採用不同的方法,那麼關聯性數值之間的又不具備可比性,在後面我們發現,我們需要這些關聯性都是同質的特徵。
對於離散VS離散、離散VS連續、連續VS連續指標這三種情況,我們的處理就是將連續的指標離散化,這樣就將問題轉換成了衡量兩個離散指標的概率依賴的問題。
但是指標怎樣進行離散化呢,對於連續指標
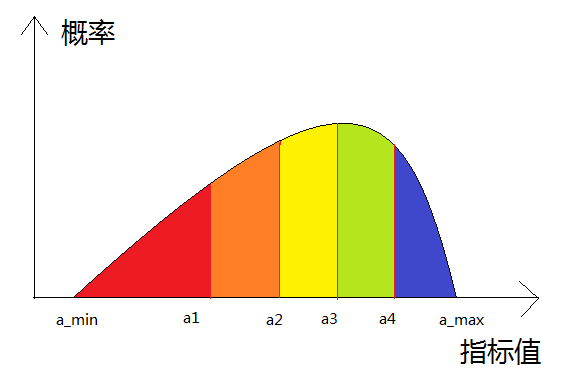
這裡我們保證每個區間的樣本量相等的原因在於,很多連續值的指標分佈很不均勻,或者存在很多異常值,而大部分樣本分佈在相對來說小的多的值區間內,用這種方法,我們可以保證每個離散值都代表等量的樣本數。
基於”互資訊”的關聯性分析
其實前面已經講過了皮爾森相關係數,這是一種衡量線性相關性的方法,但是我們這裡存在離散特徵,所以我們最終決定用概率依賴的方式來計算指標相關性。
這樣做的原因就是,在”樣本數量很大“的情況下,任何相關性都會表現出概率依賴的特點,反過來講,如果兩個變數不存在概率依賴,那麼這兩個變數之間就是獨立的,從而不會有任何相關關係(逆反命題)。
我們知道互資訊的計算公式為:
並且有
這裡涉及到熵,聯和熵、條件熵的概念,先關概念大家可以去維基百科一下。
互資訊經常在特徵選擇中用到,比如對於結果指標
接下來,我們需要記住根據每個運營指標所選出來的運維指標名單和相關程度{運營指標->{{運維指標a,0,6},{運維指標c,0,4},…}}。
也就是說每個運維指標可能在不只一個運營指標的名單中,以不同的權值出現,這個要留待後面用。