
輕量級網路模型優化進化史總結——Inception V1-4,ResNet,Xception,ResNeXt,MobileNe,,ShuffleNet,DenseNet
摘要
網路從輕量級的LeNet到更深層結構的經典AlexNet、VGG等網路結構,對於無論是recognition還是classification的精確度都有了一個很好的提升,但隨之而來也帶來了許多問題。例如在訓練中常常會遇到的梯度彌散/爆炸、過擬合、欠擬合、泛華效能差、準確度退化等等,以及隨著網路變深帶來的運算時間、空間的代價劇增。儘管顯示卡的運算效能也在不斷提升,但是從根本演算法上解決才是最為行之有效的辦法;並且現在的一個研究方向是將深度學習的演算法應用於移動端,這就需要學界從網路block結構入手發生改變。網路壓縮優化的兩個方向主要是遷移學習(例如MobileID)和網路稀疏,事實上也創造出來了更多的優秀的網路,如ResNet、InceptionV2-4、Xception、ResNext、MobileNet、ShuffleNet、DenseNet,在正文中會對這些網路做一箇中心思想的介紹。
關鍵詞:Inception V1-4,ResNet,Xception,ResNeXt,MobileNe,,ShuffleNet,DenseNet
一、引言
LeNet5 誕生於 1994 年,是最早的卷積神經網路之一,並且推動了深度學習領域的發展。現在更多的網路結構從簡單的層堆砌更多的從根本結構上發生變化,模型簡化思路總體來說是基於Conv層內部的有大量冗餘而進行的模型壓縮,目前學界裡常用的方法主要是:引數稀疏、矩陣分解、Depthwise卷積、分組卷積等等。從ResNet開始,InceptionV4、Xception、ResNext、MobileNet、ShuffleNet,以及2017CVPR的best paper的DenseNet都是借用了ResNet的思想,是被稱之為“神來之筆”的一種思想。本篇文獻綜述即以ResNet為入手點,著手閱讀了一系列最近的關於網路結構優化的優秀論文,在正文部分對這些網路的主要貢獻、核心思路、體現在網路結構的變化這三個方面進行較為詳細的敘述,並且對它們的進化史做一個梳理。
二、優化模型進化史介紹:
(1)Inception V1:
即是我們熟知的GoogleNet,它的核心思想在於增加網路深度和寬度,來提高CNN網路效能,而這也就意味著巨量的引數容易產生過擬合也會大大增加計算量。
GoogleNet認為解決上述兩個缺點的根本方法就是將全連線甚至一般的卷積都轉化為稀疏連線。一方面現實生物神經系統的連線也是稀疏的,另一方面有文獻表明:對於大規模稀疏的神經網路,可以通過分析啟用值的統計特性和對高度相關的輸出進行聚類來逐層構建出一個最優網路。這點表明臃腫的稀疏網路可能被不失效能地簡化。 雖然數學證明有著嚴格的條件限制,但Hebbian準則有力地支援了這一點:fire together,wire together。
早些的時候,為了打破網路對稱性和提高學習能力,傳統的網路都使用了隨機稀疏連線。但是,計算機軟硬體對非均勻稀疏資料的計算效率很差,所以在AlexNet中又重新啟用了全連線層,目的是為了更好地優化並行運算。GoogleNet就是為了找到一種能保持網路結構的稀疏性,又能利用密集矩陣的高計算效能的方法。
Inception module的中心思想,就是把稀疏結構近似成幾個密集的子矩陣,從而在減少引數的同時,更加有效地利用計算資源。
同一層網路結構裡面,有1*1,3*3,5*5不同的卷積模板,可以在不同size的感受野做卷積特徵提取,整個網路的計算量變大,但是層次又沒有變深。
具體操作是,在3*3、5*5卷積前面先做1*1的卷積,來降低input的channel的數量,,1*1的卷積核起到的就是降維的作用;並且由於網路到後面所提取的特徵變得更加抽象,所涉及的感受野也變得更大,kernel為3*3、5*5的卷積比例也要增加。
網路核心結構如下圖所示:
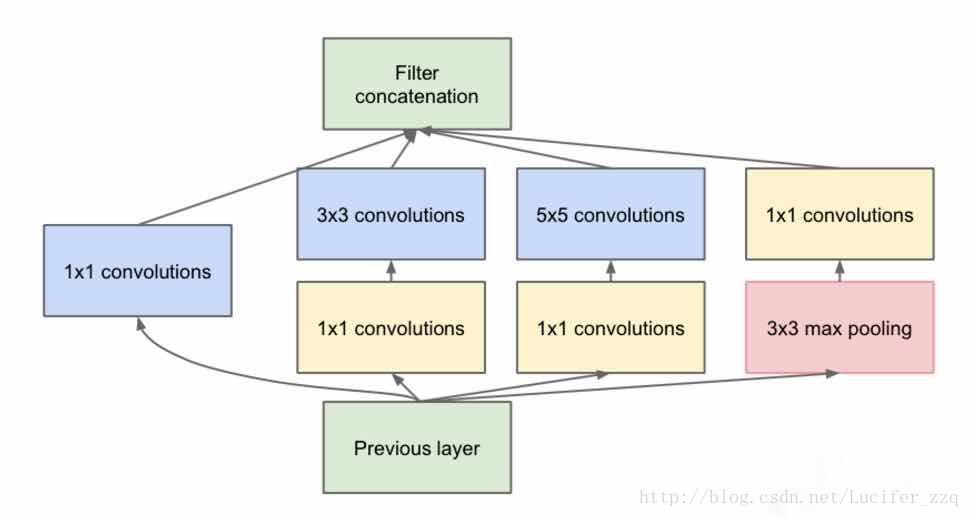
最終Google的引數相比於AlexNet少了12倍,相對於VGG-16少了3倍,在當時已經是非常優秀的網路了,但是研究遠不僅如此。
(2)Inception V2:
Inception V2最主要的貢獻就是提出了batch normalization,目的主要在於加快訓練速度。網路訓練過程中引數不斷改變導致後續每一層輸入的分佈也發生變化,而學習的過程又要使每一層適應輸入的分佈,因此我們不得不降低學習率、小心地初始化。作者將分佈發生變化稱之為internal covariate shift。
網路結構也發生了變化,用兩層堆疊3*3或者5*5,比起V1來說引數量少了,計算量少了,但層數增加,效果更好,如下:
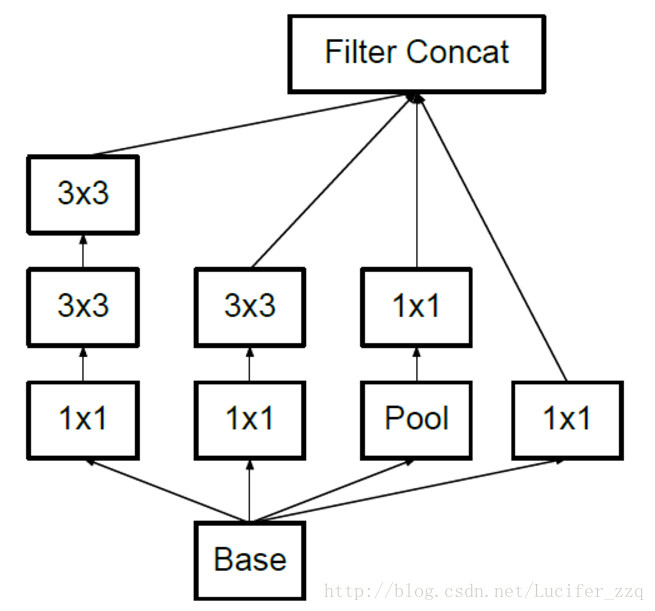
(3)Inception V3:
Inception V3的目的是研究如何在增加網路規模的同時保證計算高效率,這篇論文中還提出了一些CNN調參的經驗型規則。
1、避免特徵表徵的瓶頸,特徵表徵就是指影象在CNN某層的啟用值,特徵表徵的大小在CNN中應該是緩慢的減小的。
2、高維的特徵更容易處理,在高維特徵上訓練更快,更容易收斂
3、低維嵌入空間上進行空間匯聚,損失並不是很大。這個的解釋是相鄰的神經單元之間具有很強的相關性,資訊具有冗餘。
4、平衡的網路的深度和寬度。寬度和深度適宜的話可以讓網路應用到分散式上時具有比較平衡的computational budget。
網路結構最大的變化則是用了1*n結合n*1來代替n*n的卷積,結構如下:
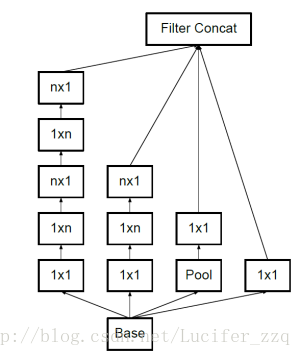
(4)ResNet:
ResNet主要解決的問題,就是在深度網路中的退化的問題。作者在論文中明確表明,在深度學習的領域中,常規網路的堆疊並不會是越深效果則越好,在超過一定深度以後,準確度開始下降,並且由於訓練集的準確度也在降低,證明了不是由於過擬合的原因。
在ResNet中增加一個identity mapping(恆等對映),將原始所需要學的函式H(x)轉換成F(x)+x,而作者認為這兩種表達的效果相同,但是優化的難度卻並不相同,作者假設F(x)的優化 會比H(x)簡單的多。這一想法也是源於影象處理中的殘差向量編碼,通過一個reformulation,將一個問題分解成多個尺度直接的殘差問題,能夠很好的起到優化訓練的效果。具體論文筆記在此部落格論文筆記中有詳細解釋。
核心block結構如下:
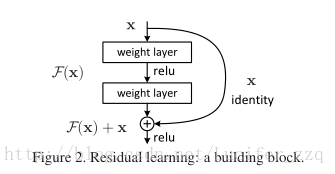
(5)Inception V4:
Inception V4主要利用殘差連線(Residual Connection),也就是ResNet的核心思想來改進V3結構。證明了Inception模組結合Residual Connection可以極大地加速訓練,同時效能也有提升,得到一個Inception-ResNet V2網路,同時還設計了一個更深更優化的Inception v4模型,能達到與Inception-ResNet V2相媲美的效能。
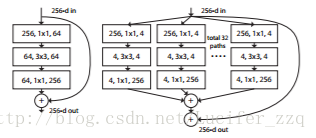
(6)ResNeXt:
ResNeXt是ResNet的極限版本,代表著the next dimension。ResNeXt的論文證明了增大Cardinality(即ResNeXt中module個數)比增大模型的width或者depth效果更好,與ResNet相比引數更少,效果也更好,結構簡單方便設計。
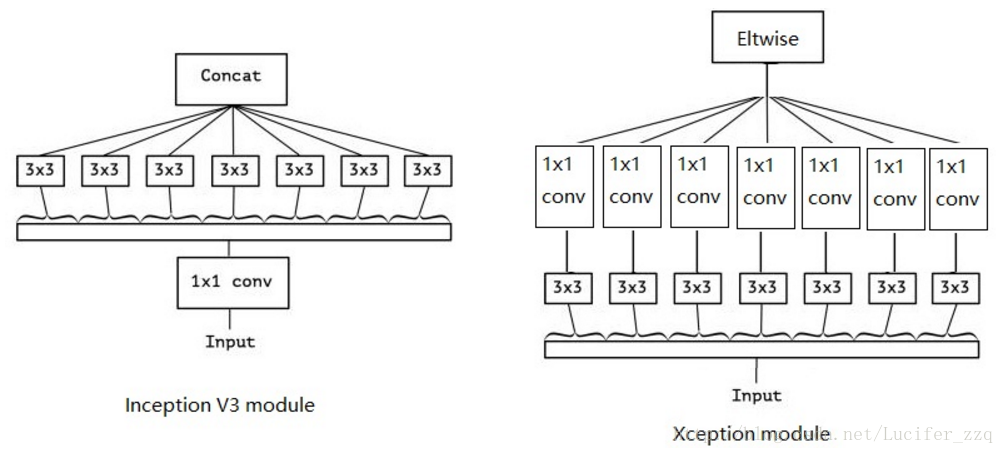
(7)Xception:
Xception是Inception系列網路的極限版本,作者提出來一個最為重要的方法是Depthwise Separable Convlution,這在後面的MobileNet中也有體現,核心思想在於空間變換、通道變換。和Inception V3不同是先做1*1的卷積,再做3*3的卷積,這樣就先將通道進行了合併,即通道卷積,然後再進行空間卷積,而Xception則正好相反,先進行空間的3*3卷積,再進行通道的1*1卷積,區別如下:
(8)MobileNet:
MobileNets其實就是Xception思想的應用。區別就是Exception文章重點在提高精度,而MobileNets重點在壓縮模型,同時保證精度。Depthwiseseparable convolutions的思想就是,分解一個標準的卷積為一個depthwise convolutions和一個pointwise convolution。簡單理解就是矩陣的因式分解,具體步驟如下圖左所示。
與傳統卷積的深度分離卷積的結構block的區別如下圖右所示:
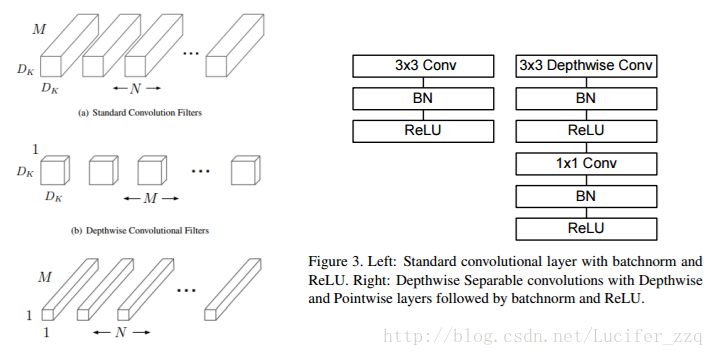
假設,輸入的feature map大小為DF * DF,維度為M,濾波器的大小為DK * DK,維度為N,並且假設padding為1,stride為1。則,原始的卷積操作,需要進行的矩陣運算次數為DK*DK*M*N*DF*DF,卷積核引數為DK *DK *N。
Depthwise separable convolutions需要進行的矩陣運算次數為DK*DK*M*DF*DF + M *N *DF*DF,卷積核引數為DK *DK *M+N。
由於卷積的過程,主要是一個spatial dimensions減少,channel dimension增加的過程,即N>M,所以,DK *DK *N> DK *DK *M+N。
因此,depthwiseseparable convolutions在模型大小上和模型計算量上都進行了大量的壓縮,使得模型速度快,計算開銷少,準確性好。
(9)ShuffleNet:
這篇文章在mobileNet的基礎上主要做了1點改進:mobileNet只做了3*3卷積的deepwiseconvolution,而1*1的卷積還是傳統的卷積方式,還存在大量冗餘,ShuffleNet則在此基礎上,將1*1卷積做了shuffle和group操作,實現了channel shuffle 和pointwise group convolution操作,最終使得速度和精度都比mobileNet有提升。
具體結構如下圖所示:
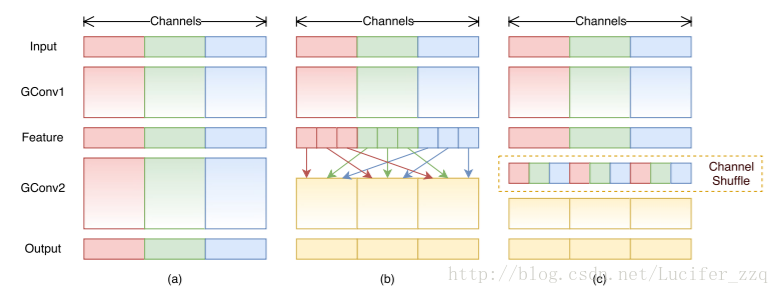
(a)是原始的mobileNet的框架,各個group之間相互沒有資訊的交流。
(b)將feature map做了shuffle操作
(c)是經過channel shuffle之後的結果。
shufflenet中也採用了分組卷積的思想,效果非常顯著,間接說明了,實際上一種高效的神經網路結構設計就是應該是分組的,而不是和一般的Conv或者InnerProduct那樣全部連線在一起——類似資訊應該被共享,不需要重複提取;不同的分組會承擔不同的功能,並且這些功能是可以被訓練的。這能夠告訴我們,資訊是需要濃縮的。
(10)DenseNet:
DenseNet是最近的2017CVPR的best paper,儘管是基於ResNet,但是不同的是為了最大化網路中所有層之間的資訊流,作者將網路中的所有層兩兩都進行了連線,使得網路中每一層都接受它前面所有層的特徵作為輸入。由於網路中存在著大量密集的連線,作者將這種網路結構稱為 DenseNet,結構如下圖左所示:
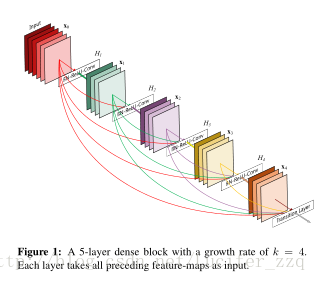
它主要擁有以下兩個特性:
1、一定程度上減輕在訓練過程中梯度消散的問題。因為從上左圖我們可以看出,在反傳時每一層都會接受其後所有層的梯度訊號,所以不會隨著網路深度的增加,靠近輸入層的梯度會變得越來越小。
2、由於大量的特徵被複用,使得使用少量的卷積核就可以生成大量的特徵,最終模型的尺寸也比較小。
一個完整的DesNet結構如下圖:
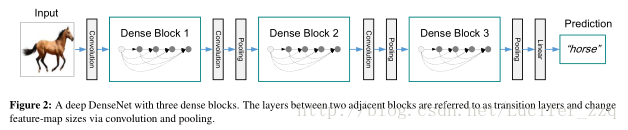
論文對網路進行設計的幾個要點也進行了說明如下:
1、為了進行特徵複用,在跨層連線時使用的是在特徵維度上的 Concatenate 操作,而不是 Element-wise Addition操作。
2、由於不需要進行 Elewise-wise 操作,所以在每個單元模組的最後不需要一個 1X1 的卷積來將特徵層數升維到和輸入的特徵維度一致。
3、採用 Pre-activation 的策略來設計單元,將 BN 操作從主支上移到分支之前。(BN->ReLU->1x1Conv->BN->ReLU->3x3Conv)。
4、由於網路中每層都接受前面所有層的特徵作為輸入,為了避免隨著網路層數的增加,後面層的特徵維度增長過快,在每個階段之後進行下采樣的時候,首先通過一個卷積層將特徵維度壓縮至當前輸入的一半,然後再進行 Pooling 的操作。
5、增長率的設定。增長率指的是每個單元模組最後那個 3x3 的卷積核的數量,記為 k。由於每個單元模組最後是以 Concatenate 的方式來進行連線的,所以每經過一個單元模組,下一層的特徵維度就會增長 k。它的值越大意味著在網路中流通的資訊也越大,相應地網路的能力也越強,但是整個模型的尺寸和計算量也會變大。作者在本文中使用了 k=32 和 k=48 兩種設定。
三、總結與展望:
本文基於ResNet入手,將ResNet前後優秀的網路結構設計進行了梳理和核心點的概括。總的來看,近年來在會議上有越來越多的手工設計網路的出現,一步步取代傳統的網路單純變深的思路,學界也越來越關注於尋找模型壓縮和優化的方法用於處理recognition與classification這兩個計算機視覺方面最為重要的問題。不要是要讓accuracy更小、mAP更高、收斂曲線更好,同時還要減少計算的空間和成本。從MobileNet我們也可以看出,由於更多框架的搭建,更少的減少卷積層的內部冗餘,提高運算效能和網路效能,在業界這也為深度學習向移動端發展提供了可能。
手動設計網路結構的不斷演進,噴井式的網路結構優化論文的髮辮,我們目前談論的手工設計的神經網路結構將會被很快淘汰。但從前人的論文中我們應該吸收他們的創意和思路,並且尋找到新的方法。對未來的設想是隨著網路的不斷進化,以後甚至可以自動根據訓練資料學習得到的“更適合”的網路結構所代替,只是固定網路的基本結構,而整個神經網路的拓撲結構可以在訓練中被自動發現、設計,而不再是手動設計,這樣的網路可以不斷在場景中升級演化。
四、參考文獻(對應正文第二部分的順序):
[1] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2015:1-9.
[2] Ioffe S, Szegedy C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[J]. 2015:448-456.
[3] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the Inception Architecture for Computer Vision[J]. 2015:2818-2826.
[4] He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[J]. 2015:770-778.
[5] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning[J]. 2016.
[6] Xie S, Girshick R, Dollar P, et al. Aggregated Residual Transformations for Deep Neural Networks[J]. 2016.
[7] Chollet F. Xception: Deep Learning with Depthwise Separable Convolutions[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2017:1800-1807.
[8] Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. 2017.
[9] Zhang X, Zhou X, Lin M, et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices[J]. 2017.
[10] Huang G, Liu Z, Maaten L V D, et al. Densely Connected Convolutional Networks[J]. 2016.