
偏差(Bias)與方差(Variance)
目錄
1. 問題背景
NFL(No Free Lunch Theorem)告訴我們選擇演算法應當與具體問題相匹配,通常我們看一個演算法的好壞就是看其泛化效能,但是對於一個演算法為什麼好為什麼壞,我們缺乏一些認識。“Bias-Variance Decomposition”就是從偏差和方差的角度來解釋一個演算法的泛化效能。
2. 一點點數學
“Bias-Variance Decomposition” 是以測試集上的平方錯誤為基礎的,假設我們的預測值為,真實值為,則均方誤差為。
為了讓世界更加美好,我們在這裡不考慮樣本的噪聲。
“The noise term is unaviodable no matter what we do, so the terms we are interested in are really the bias and variance”(from “Learning From Data” Page 64)
(噪聲的存在是學習演算法所無法解決的問題,資料的質量決定了學習的上限。而假設在資料已經給定的情況下,此時上限已定,我們要做的就是儘可能的接近這個上限)
並且使用來代表預測值(這裡我們把它看成是隨機變數,即不同資料學習得到的模型), 代表真實值, 代表演算法的期望預測(如:可以用不同的資料集來得到),則有:
3. 偏差與方差
由上面的公式可知,偏差描述的是演算法的預測的平均值和真實值的關係(可以想象成演算法的擬合能力如何),而方差描述的是同一個演算法在不同資料集上的預測值和所有資料集上的平均預測值之間的關係(可以想象成演算法的穩定性如何)。
(ps:個人認為可以把偏差認為是單個模型的學習能力,而方差則描述的是同一個學習演算法在不同資料集的不穩定性)
偏差和方差的形象展示如下圖所示(圖片引自Understanding the Bias-Variance Tradeoff )

圖中的紅色位置就是真實值所在位置,藍色的點是演算法每次預測的值。
可以看出,偏差越高則離紅色部分越遠,而方差越大則演算法每次的預測之間的波動會比較大。
4. 偏差方差窘境
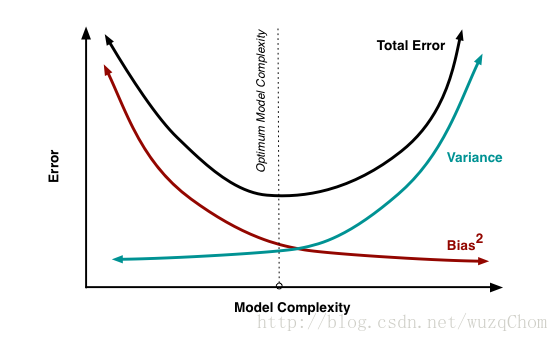
從圖中我們可以看出,偏差和方差兩者是有衝突的,稱之為變差方差窘境(bias-variance dilemma)。
假如學習演算法訓練不足時,此時學習器的擬合能力不夠強,此時資料的擾動不會對結果產生很大的影響(可以想象成由於訓練的程度不夠,此時學習器指學習到了一些所有的資料都有的一些特徵),這個時候偏差主導了演算法的泛化能力。隨著訓練的進行,學習器的擬合能力逐漸增強,變差逐漸減小,但此時不同通過資料學習得到的學習器就可能會有較大的偏差,即此時的方差會主導模型的泛化能力。若學習進一步進行,學習器就可能學到資料集所獨有的特徵,而這些特徵對於其它的資料是不適用的,這個時候就是發生了過擬合的想象。
5. Bagging和Boosting
Bagging和Boosting是整合學習當中比較常用的兩種方法,剛好分別對應了降低模型方差和偏差。
Bagging是通過重取樣的方法來得到不同的模型,假設模型獨立則有: