
NOIP2016T4暨洛谷P2119解題報告+讀入輸出優化(原創+轉載)
阿新 • • 發佈:2019-01-22
Part 1: 解題報告(原創)
第一次
先來一波截圖:
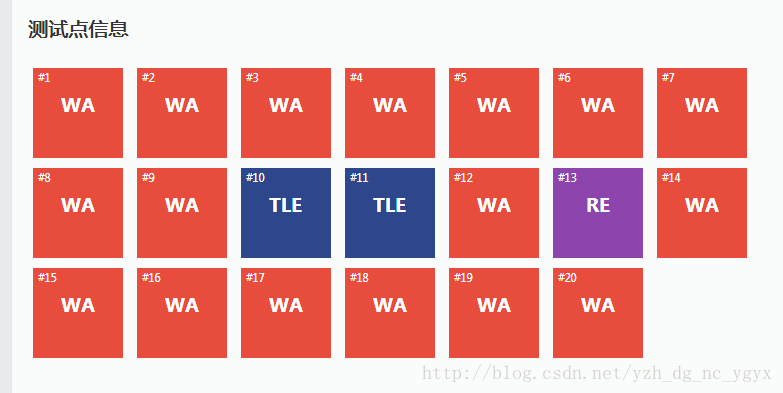
評測網站:洛谷
首先,先說一說我第一次個人的思想,只想著暴力列舉:
程式碼
#include<iostream>
#include<memory.h>
using namespace std;
int main(){
int px[15001],ans[15001][4],fore[40001];
int n,m,tmp;
//ios::sync_with_stdio(false);
cin>>n>>m;
memset(px,0,sizeof 五顏六色,有紅的,有紫的,有黑的,就是沒有一個綠的。
原因
奇葩的在樣例的第二個24輸出了比第一個24多一倍的答案。
輸入樣例:
30 8
1
24
7
28
5
29
26
24
程式輸出:
4 0 0 0
0 0 1 0
0 2 0 0
0 0 1 1
1 3 0 0
0 0 0 2
0 0 2 2
0 0 2 0
說好的一輩子平等呢?
於是,和老師一起鑽研了幾個中午。
第二次
成果:
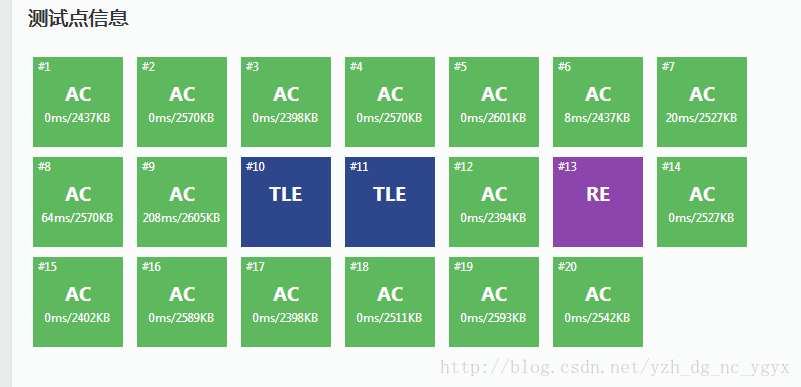
不得不說,老師還是厲害。
一眼發現了錯誤。
程式碼:
#include<iostream>
#include<memory.h>
using namespace std;
int main(){
int px[15001],ans[15001][4],fore[40001];
int n,m,tmp;
ios::sync_with_stdio(false);
cin>>n>>m;
memset(px,0,sizeof(px));
memset(ans,0,sizeof(ans));
memset(fore,0,sizeof(fore));
for(int i=1;i<=m;i++){
cin>>fore[i];
px[fore[i]]++;
}
for(int i=1;i<=n-3;i++){
if(px[i]>0){
for(int j=i+1;j<=n-2;j++){
if(px[j]>0&&(j-i)%2==0){
for(int k=j+(j-i)*3+1;k<=n-1;k++){
if(px[k]>0){
int p=k+(j-i)/2;
if(px[p]>0){
tmp=px[i]*px[j]*px[k]*px[p];
ans[i][0]+=tmp;
ans[j][1]+=tmp;
ans[k][2]+=tmp;
ans[p][3]+=tmp;
}
}
}
}
}
}
}
for(int i=1;i<=m;i++){
for(int j=0;j<4;j++)
cout<<ans[fore[i]][j]/px[fore[i]]<<" ";
cout<<endl;
}
return 0;
}大家來找茬。
是的,就在第19,20行。
優化:
19行加了一個判斷,這樣才不會出現小數的情況(是2的倍數再除以2呀!)
20行將次數又縮小了,完成了從全爆0到85的突破。
第三次
後來呢:

我承認我無恥地參考了一下cenbinbin大佬的題解,在這我就直接把他的程式碼放上來吧。
程式碼:
var
data,num:array[0..40001] of longint;
v:array[0..40001,0..5] of longint;
a,b,c,w,d,sum,n,m,i:longint;
begin
readln(n,m);
for i:=1 to m do
begin read(data[i]);inc(num[data[i]]);end;
for w:=1 to n div 9 do
begin
sum:=0;
for d:=w*9+2 to n do
begin
a:=d-9*w-1;
b:=d-7*w-1;
c:=d-w;
sum:=sum+num[b]*num[a];
v[c,3]:=v[c,3]+num[d]*sum;
v[d,4]:=v[d,4]+num[c]*sum;
end;
sum:=0;
for a:=n-w*9-1 downto 1 do
begin
b:=a+w*2;
c:=a+w*8+1;
d:=a+w*9+1;
sum:=sum+num[d]*num[c];
v[a,1]:=v[a,1]+num[b]*sum;
v[b,2]:=v[b,2]+num[a]*sum;
end;
end;
for i:=1 to m do
writeln(v[data[i],1],' ',v[data[i],2],' ',v[data[i],3],' ',v[data[i],4]);
end.思想:
分類列舉,分別列舉a和d,進而求出b和c。
(還用說嗎?)
通過列舉d,我們求出了c,知道了a,b的最小值;
通過列舉a,我們求出了b,知道了c,d的最小值。
所以到最後,我們就得知了a,b,c,d分別的大小。
而通過加乘原理,我們得知了有多少種情況。
最後輸出即可。
優點:內容簡潔,程式碼清晰,容易理解。
缺點:記憶體較大,速度一般,暴力列舉畢竟不是最好的演算法。
Part 2:讀入輸出優化(轉載)
附錄:哎,寫太多了,太枯燥,附上讀入輸出優化的程式碼吧。
以下是轉載內容:注意了注意了注意了,重要的事情說3遍,這個東西是騙分神器,騙分神器,騙分神器!!!
眾所周知:scanf比cin快得多,printf比cout快得多,如果你不知道就……就現在知道了
那有沒有更快的呢?當然。 
請看:

我懵逼了,至於慢近100ms嗎?
好吧,這就是讀入優化的效果,在資料很恐怖的情況下能比scanf多過1-5個點……
比如說這種:這裡寫圖片描述
都說了要讀入優化你還不讀入優化,那不是找死嗎……
前面都是廢話,現在開始說正事
讀入優化
首先,讀入優化這裡是只是針對整數,getchar讀字元是非常快的,所以我們就用getchar了。(下面都假設輸入的數為x)
負數處理
很簡單,用一個標誌變數f,開始時為1,當讀入了’-’時,f變為-1,最後x*=f即可
絕對值部分處理
顯然getchar每次只能讀一位,所以,每當讀了一位時x*=10,為這一位“留位置”。
舉個例子:現在讀入了123,x為123,再讀入了一個4,x\*=10,變為了1230,現在它的最後一位空出來了,正好留給4,x+=4,x就變為了1234,當然,這裡的’4’是char型別,需要減去’0’才是4,即:x=x*10+s-'0'(s為當前輸入的字元)
關於細節
很多時候是有多餘空格或者其他的亂碼字元輸入,為了防止bug,我們要嚴謹~詳見程式碼。
程式碼void read(int &x)//'&'表示引用,也就是說x是一個實參,在函式中改變了x的值就意味著在外面x的值也會被改變
{
int f=1;//標記正負
x=0;//歸零(這就是潛在bug,有可能傳進來時x沒有歸零)
char s=getchar();//讀入第一個字元
while(s<'0'||s>'9')//不是數字字元
{
if(s=='-')//不能直接把f=-1,有可能輸入的不是'-'而是其他亂七八糟的東西
f=-1;
s=getchar();//繼續讀
}
while(s>='0'&&s<='9')//是字元(一旦不是字元就意味著輸入結束了)
{
x=x*10+s-'0';
s=getchar();
}
x*=f;//改變正負
}簡潔一些:void read(int &x)
{
int f=1;x=0;char s=getchar();
while(s<'0'||s>'9'){if(s=='-')f=-1;s=getchar();}
while(s>='0'&&s<='9'){x=x*10+s-'0';s=getchar();}
x*=f;
}這就是完整的讀入優化了,你可以直接這樣用:int N;
read(N);當然還有更裝逼的程式碼:#define num ch-'0'
void get(int &res){
char ch;bool flag=0;
while(!isdigit(ch=getchar()))
(ch=='-')&&(flag=true);
for(res=num;isdigit(ch=getchar());res=res*10+num);
(flag)&&(res=-res);
}這個就真的很跳了。
首先:isdigit是判斷一個字元是否為數字字元,需要標頭檔案#include<cctype>,剛剛忘了說,getchar需要cstdio。
然後,那個詭異的(ch=='-')&&(flag=true)和(flag)&&(res=-res);是個什麼玩意?我們發揮聰明才智,想起&&是“短路運算子”,短路運算子是啥?就是看到第一個條件錯誤就不會執行第二個條件,直接跳過了,所以這兩句程式碼就不難理解了,唯一顛覆寶寶們的認知的是&&可以脫離if和return什麼的直接用……
輸出優化
如果有50%的人知道輸入優化,那知道輸出優化的最多不過20%,輸出還能怎麼優化?putchar啊!putchar是比printf快的。(下面都假設輸出的數為x)
ps:居然還有putchar這種東西?!
負數處理
輸出就簡單了,如果是負數,直接putchar('-');x=-x;即可,不解釋。
絕對值部分處理
這裡是不是還是用迴圈呢?答案是——否定的,為了極致的速度,我們用遞迴!遞迴什麼?遞迴下一位啊,即x/10,然後,注意邊界,x要>9才能繼續遞迴,否則要輸出x%10(因為還有最後一位)。
關於細節
無……
程式碼void print(int x)//這裡當然不用實參
{
if(x<0)//負數
{
putchar('-');
x=-x;
}
if(x>9)//只要x還是2位數或更多就繼續分解
print(x/10);//這裡遞迴完後棧裡面x的每一位是倒過來的(關於遞迴,我也實在解釋不清楚,各位去看看神犇們的遞迴解釋吧)
putchar(x%10+'0');//輸出(要把int型變為char型,加'0'即可)
至於輸出優化,目前還沒發現什麼太跳的,畢竟寫輸出優化的就少。對比
為了能看出優勢,我做了一個對比:
Test.cpp:#include<cstdio>
#include<ctime>
#include<windows.h>
using namespace std;
#define TIMES 1000000
double A[5];
void print(int x)
{
if(x<0)putchar('-'),x=-x;
if(x>9)print(x/10);
putchar(x%10+'0');
}
void read(int &x)
{
int f=1;x=0;char s=getchar();
while(s<'0'||s>'9'){if(s=='-')f=-1;s=getchar();}
while(s>='0'&&s<='9'){x=x*10+s-'0';s=getchar();}
x*=f;
}
int main()
{
freopen("in.txt","r",stdin);
freopen("111.txt","w",stdout);
int a;
double t1,t2;
t1=clock();
for(int i=1;i<=TIMES;i++)
scanf("%d",&a);
t2=clock();
A[1]=(t2-t1)/1000;
t1=clock();
for(int i=1;i<=TIMES;i++)
read(a);
t2=clock();
A[2]=(t2-t1)/1000;
t1=clock();
for(int i=1;i<=TIMES;i++)
printf("%d",a);
t2=clock();
A[3]=(t2-t1)/1000;
t1=clock();
for(int i=1;i<=TIMES;i++)
print(a);
t2=clock();
A[4]=(t2-t1)/1000;
fclose(stdout);//為了不輸出前面一堆東西
freopen("out.txt","w",stdout);
printf("Scanf: %.4lf S\n",A[1]);
printf("Read: %.4lf S\n",A[2]);
printf("Printf: %.4lf S\n",A[3]);
printf("Print: %.4lf S",A[4]);
}Data.cpp:#include<cstdio>
#include<ctime>
#include<cstdlib>
#define TIMES 1000000
#define MAXN 100000
int main()
{
srand(time(NULL));
freopen("in.txt","w",stdout);
for(int i=1;i<=TIMES*2;i++)
{
if(rand()%2)
printf("-");
printf("%d\n",rand()%MAXN);
}
}如果你想測cin,cout,自己試試吧……
以下是我的測試結果(測5次,資料一模一樣):
次數 scanf耗時 read耗時 printf耗時 print耗時
1 0.2960 S 0.0790 S 0.1870 S 0.0630 S
2 0.2960 S 0.0940 S 0.1720 S 0.0630 S
3 0.2810 S 0.0780 S 0.1870 S 0.0630 S
4 0.2960 S 0.0790 S 0.1870 S 0.0470 S
5 0.2970 S 0.0780 S 0.1720 S 0.0630 S
這裡用了1000000組資料,輸入優化比scanf快了約0.2秒,也就是說,每50萬組資料讀入優化要快0.1秒(100ms),剛好符合了最開始的資料範圍。