
邏輯迴歸模型的評估方法
從Weka工具跑回歸模型可以看到評估的輸出,怎麼解讀自行腦補過,大概明白了些。
翠花,上截圖!
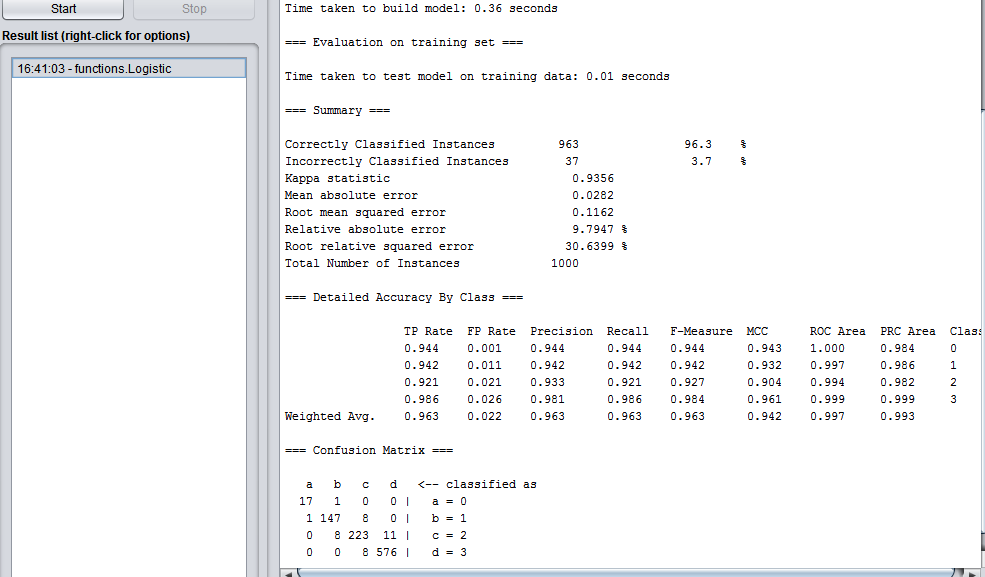
我們普通人最直接的理解是正確率吧。應該對應到Correctly Classified Instances比例(正確分類了的例項)。
在上圖中,總例項數1000,正確分類了963,*正確率*96.3% 。
TP、FP、FN、TN
但一兩個數往往說明不了問題,專業人士們,會看真的、被分對、真的、被分錯、假的、被分錯、假的、被分對各是什麼情況。
專業人士說用TP、FN、FP、TN來表示……
- TP:True Positive,“真陽性”。
- FP:False Positive,“假陽性”。
- FN:False Negative,“假陰性”。
- TN:True Negative,“真陰性”。
老外發明的標記法,跟我們東方人思維不一樣,太混淆了,對比了N篇部落格和翻譯之後,我覺得可以這樣理解:
“T”表示判定對了,“F”表示判定錯了
“P”表示有事(即“命中”、“對應上”),“N”表示沒事
於是:
- TP:正確地判定了“命中”
- FP:錯誤地判定了“命中”
- TN:正確地判定了“不命中”
- FN:錯誤地判定了“不命中”
有幾個術語:
- 誤檢率: fp rate = sum(fp) / (sum(fp) + sum(tn))
- 查準率: precision rate = sum(tp) / (sum(tp) + sum(fp))
- 查全率: recall rate = sum(tp) / (sum(tp) + sum(fn))
- 漏檢率:miss rate = sum(fn) / (sum(tp) + sum(fn))
能再專業一點?
唉,我盜個圖吧……

ROC曲線、AUC
ROC曲線的橫座標為false positive rate(FPR),縱座標為 true positive rate(TPR)
當測試集中的正負樣本的分佈變化的時候,ROC曲線能夠保持不變。根據每個測試樣本屬於正樣本的概率值從大到小排序,依次將 “Score”值作為閾值threshold,當測試樣本屬於正樣本的概率 大於或等於這個threshold時,認為它為正樣本
一個典型的ROC曲線如下圖:
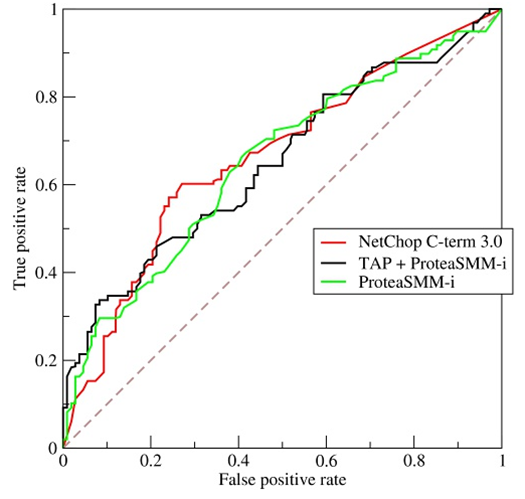
計算出ROC曲線下面的面積,就是AUC的值。 介於0.5和1.0之間,越大越好。
Kappa statics
Kappa值,即內部一致性係數(inter-rater,coefficient of internal consistency),是作為評價判斷的一致性程度的重要指標。取值在0~1之間。Kappa≥0.75兩者一致性較好;0.75>Kappa≥0.4兩者一致性一般;Kappa<0.4兩者一致性較差。
第一個圖上,所顯示的Kappa值有0.9356,那就算很好了。
Mean absolute error 和 Root mean squared error
平均絕對誤差和均方根誤差,用來衡量分類器預測值和實際結果的差異,越小越好。
Relative absolute error 和 Root relative squared error
相對絕對誤差和相對均方根誤差,有時絕對誤差不能體現誤差的真實大小,而相對誤差通過體現誤差佔真值的比重來反映誤差大小。