
論文閱讀:Deep Relative Distance Learning: Tell the Difference Between Similar Vehicles
Preface
這是我參加今年智慧城市比賽的任務:車輛精確檢索,看的論文。
Abstract
這篇文章所提出的,網路整體架構為:
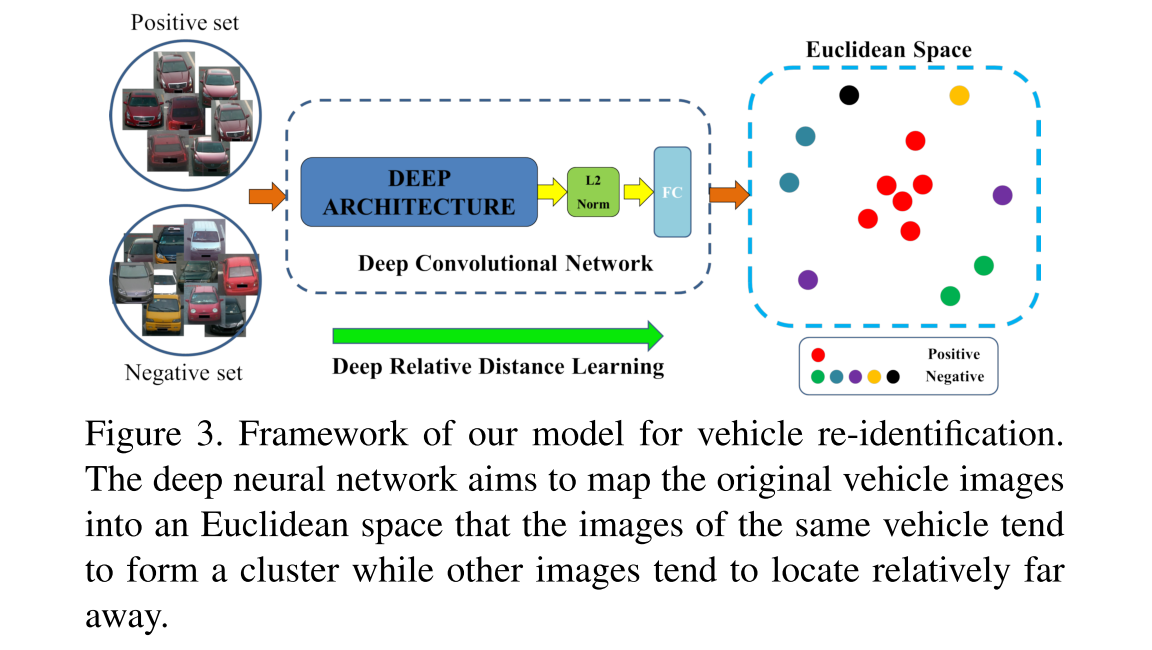
Deep Relative Distance Learning
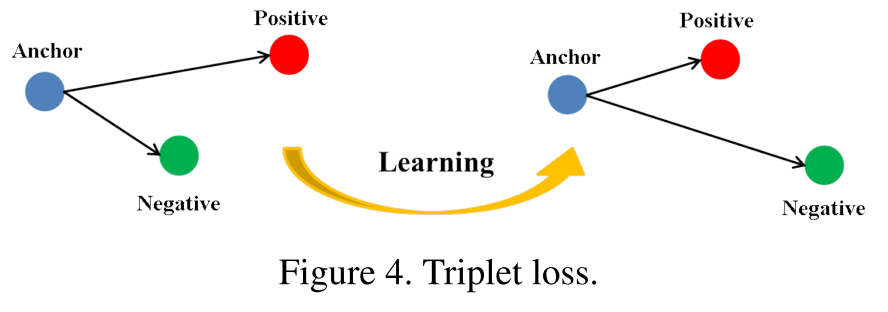
Triplet Loss
在標準的 Triplet Loss 中,輸入為一批三元組:
用
或者等同於:
其中,
同時,為了防止損失函式太容易超過
上面的話,用圖表示為:
所以,定義的損失函式為:
但是,存在一種“極端”的情況,給定
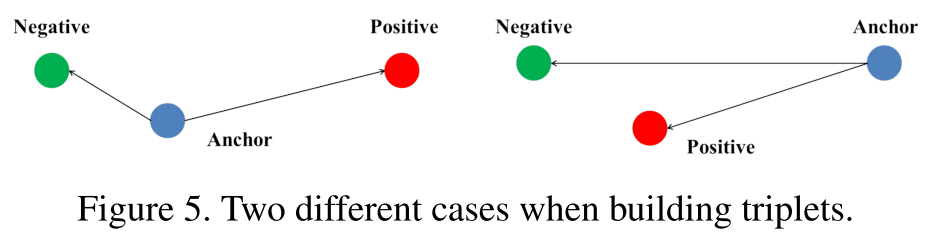
當對於左邊的情況,三元組損失函式很容易檢測出反常的距離關係。因為左圖中,類內距離(
在圖中反應為,藍色點 “Anchor” 與同標籤的紅色點 “Positive”,之間的距離大於 Anchor 與 Negative 之間的距離。所以損失函式可以較容易的去學習。
而上一幅圖的右邊的情況就不同了。
三元損失函式為
此外,由於三元組損失函式在反向傳播中,實際上是要將同標籤的越“拉”越近(Anchor 與 Positive),不同標籤的越“推”越遠(Anchor 與 Negative),所以損失函式對於 Anchor 點的選擇是相當敏感的。所以,Anchor 點選擇不好的話,在訓練階段會造成極大的干擾,使得網路收斂的很慢。需要很多個正確的三元組樣本點去糾正它。
Coupled Clusters Loss
為了使得訓練階段更加穩定,網路收斂的更加快。作者想上面的這種定義損失函式的方式,應該有些欠缺妥當。因此,作者提出了一個新的損失函式,以取代這裡的三元組損失函式:Coupled Cluster Loss 。
作者也用深度卷積網路去提取影象的特徵,不過原先網路是以“三元組樣本點”作為輸入資料的,這裡由兩組影象集取代:一組是正樣本集,另一組是負樣本集。
一組資料集:
如下圖所示:

在計算的時候,先求出正樣本“平均中心點”:
相關推薦
論文閱讀:Deep Relative Distance Learning: Tell the Difference Between Similar Vehicles
Preface 這是我參加今年智慧城市比賽的任務:車輛精確檢索,看的論文。 Abstract 這篇文章所提出的,網路整體架構為: Deep Relative Distance Learning Triplet Loss 在
論文閱讀:Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis
這篇論文是在2017年3月22日發表在CVPR上的,作者在這篇論文中提出了一個叫做深度從粗糙到精細化的多工卷積神經網路(Deep MANTA),該模型可以用於對一張圖片中的車輛進行多工的分析。該網路同時執行的多工包括:車輛檢測、部件定位、可見性描述和三維形
論文筆記:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇論文地主要創新是在將注意機制引入到目標跟蹤 摘要:源自認知神經科學地視覺注意促進人類對相關的內
論文閱讀:Disentangled Representation Learning GAN for Pose-Invariant Face Recognition
ICCV2017的文章,主要使用multi-task的GAN網路來提取pose-invariant特徵,同時生成指定pose的人臉。 下載連結: 作者: Motivation: 對於大pose的人臉識別,現在大家都是兩種方案:1 先轉正再人臉識別。2 直接學習
影象隱寫術分析論文筆記:Deep learning for steganalysis via convolutional neural networks
好久沒有寫論文筆記了,這裡開始一個新任務,即影象的steganalysis任務的深度網路模型。現在是論文閱讀階段,會陸續分享一些相關論文,以及基礎知識,以及傳統方法的思路,以資借鑑。 這一篇是Media Watermarking, Security, and Forensi
論文筆記:Deep Learning [nature review by Lecun, Bengio, & Hinton]
假設我們需要訓練一個深度神經網路來預測一段文字序列的下一個單詞。我們用一個one-of-N的0-1向量來表示上下文中出現的單詞。神經網路將首先通過一個embedding層為每一個輸入的0-1向量生成一個word vector,並通過剩下的隱藏層將這些word vector轉化為目標單詞的word vector
論文閱讀:A Survey on Transfer Learning
本文主要內容為論文《A Survey on Transfer Learning》的閱讀筆記,內容和圖片主要參考 該論文 。其中部分內容引用與部落格《遷移學習綜述a survey on transfer learning的整理下載》,感謝博主xf__ma
論文閱讀《End-to-End Learning of Geometry and Context for Deep Stereo Regression》
註意 4.3 匹配算法 argmin hang 立體聲 移動 數據集 聚集 端到端學習幾何和背景的深度立體回歸 摘要 本文提出一種新型的深度學習網絡,用於從一對矯正過的立體圖像回歸得到其對應的視差圖。我們利用問題(對象)的幾何知識,形成一個使
論文閱讀:Memory Networks
users 方式 article div local 網絡 ava auto data- 一、論文所解決的問題 實現長期記憶(大量的記憶),而且實現怎樣從長期記憶中讀取和寫入,此外還增加了推理功能 為什麽長期記憶非常重要:由於傳統的RNN連復制任務都不行,LST
論文閱讀:A Primer on Neural Network Models for Natural Language Processing(1)
選擇 works embed 負責 距離 feature 結構 tran put 前言 2017.10.2博客園的第一篇文章,Mark。 由於實驗室做的是NLP和醫療相關的內容,因此開始啃NLP這個硬骨頭,希望能學有所成。後續將關註知識圖譜,深度強化學習等內
論文閱讀 | A Deep Relevance Matching Model for Ad-hoc Retrieval
A Deep Relevance Matching Model for Ad-hoc Retrieval (2016 CIKM) 模型細節 1.對於query中的每個詞建立mapping直方圖 輸入:query中的每個詞和doc所有詞產生term pair,
深度學習論文筆記:Deep Residual Networks with Dynamically Weighted Wavelet Coefficients for Fault Diagnosis of Planetary Gearboxes
這篇文章將深度學習演算法應用於機械故障診斷,採用了“小波包分解+深度殘差網路(ResNet)”的思路,將機械振動訊號按照故障型別進行分類。 文章的核心創新點:複雜旋轉機械系統的振動訊號包含著很多不同頻率的衝擊和振盪成分,而且不同頻帶內的振動成分在故障診斷中的重要程度經常是不同的,因此可以按照如下步驟設計深度
【論文閱讀】Sequence to Sequence Learning with Neural Networks
看論文時查的知識點 前饋神經網路就是一層的節點只有前面一層作為輸入,並輸出到後面一層,自身之間、與其它層之間都沒有聯絡,由於資料是一層層向前傳播的,因此稱為前饋網路。 BP網路是最常見的一種前饋網路,BP體現在運作機制上,資料輸入後,一層層向前傳播,然後計算損失函式,得到損失函式的殘差
[原創·論文閱讀]QGesture: Quantifying Gesture Distance and Direction with WiFi Signals
[原創·論文閱讀]QGesture: Quantifying Gesture Distance and Direction with WiFi Signals 前言 本文推出了一個叫做QGesture的系統,在一維和二維部署場景下,它能對人的手勢的運動距離和方向進行測量。部署場景:
【論文閱讀】Deep Adversarial Subspace Clustering
導讀: 本文為CVPR2018論文《Deep Adversarial Subspace Clustering》的閱讀總結。目的是做聚類,方法是DASC=DSC(Deep Subspace Clustering)+GAN(Generative Adversarial Networks)。本文從以下四個方面來
【論文閱讀】Deep Mixture of Diverse Experts for Large-Scale Visual Recognition
導讀: 本文為論文《Deep Mixture of Diverse Experts for Large-Scale Visual Recognition》的閱讀總結。目的是做大規模影象分類(>1000類),方法是混合多個小深度網路實現更多類的分類。本文從以下五個方面來對論文做個簡要整理: 背
論文翻譯:Deep SORT: Simple Online and Realtime Tracking with a Deep Association Metric
相關部落格詳解一:https://blog.csdn.net/cdknight_happy/article/details/79731981 DeepSort論文學習 cdknight_happy 相關部落格詳解二:https://www.cnblogs.com/YiXiao
論文閱讀:You Only Look Once: Unified, Real-Time Object Detection
Preface 注:這篇今年 CVPR 2016 年的檢測文章 YOLO,我之前寫過這篇文章的解讀。但因為不小心在 Markdown 編輯器中編輯時刪除了。幸好同組的夥伴轉載了我的,我就直
論文筆記:Deep neural networks for YouTube recommendations
https://blog.csdn.net/xiongjiezk/article/details/73445835 Download [1] Covington P, Adams J, Sargin E. Deep neural networks for youtube recommen
(論文閱讀筆記1)Collaborative Metric Learning(一)(WWW2017)
一、摘要 度量學習演算法產生的距離度量捕獲資料之間的重要關係。這裡,我們將度量學習和協同過濾聯絡起來,提出了協同度量學習(CML),它可以學習出一個共同的度量空間來編碼使用者偏好和user-user 和 item-item的相似度。 二、背景