5 sklearn的資料集-datasets
阿新 • • 發佈:2019-01-26
sklearn的資料集-datasets
1 sklearn 強大資料庫
data sets,有很多有用的,可以用來學習演算法模型的資料庫。
eg: boston 房價, 糖尿病, 數字, Iris 花。
主要有兩種:
- 封裝好的經典資料。eg: boston 房價, 糖尿病, 數字, Iris 花。在程式碼中以“load”開頭。
- 自己設計引數,然後生成的資料,例如用來訓練線性迴歸模型的資料(強大)。在程式碼中以“make”開頭
2 文件介紹
2.1 經典資料
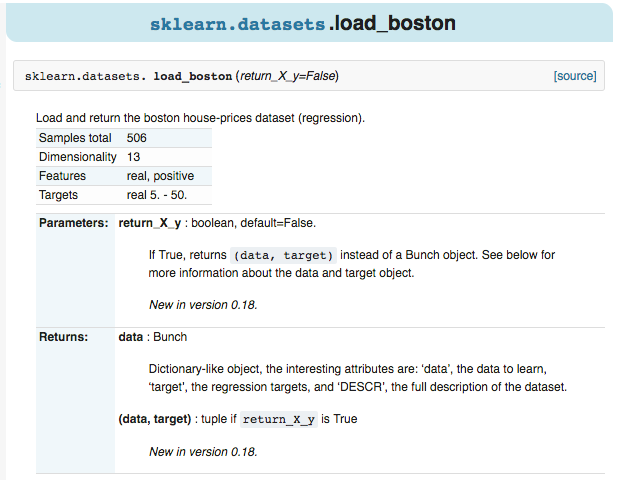
例如,點選進入 boston 房價的資料,可以看到 sample 的總數,屬性,以及 label 等資訊。
2.2 構造資料
如果是自己生成資料,按照函式的形式,輸入 sample,feature,target 的個數等等。
sklearn.datasets.make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)[source]3 例子1,房價
# 匯入滿滿的資料庫
from sklearn import 4 例子2:建立虛擬資料並可視化
# 匯入滿滿的資料庫,這裡用它的第二個方面:構造資料
from sklearn import datasets
# 匯入 線性迴歸 方法
from sklearn.linear_model import LinearRegression
# 畫圖工具
import matplotlib.pyplot as plt
# 構造用於迴歸的資料make_regression
# 引數的意思:100個例子,1種特徵,1種輸出,噪聲的大小為5
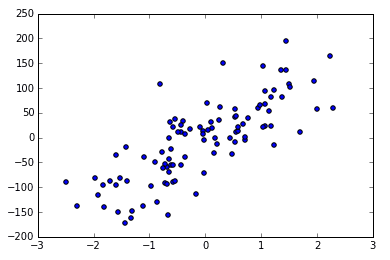
X,y = datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=2)
# 影象化我們剛剛建立的資料
plt.plot(X,y,'o')
plt.show()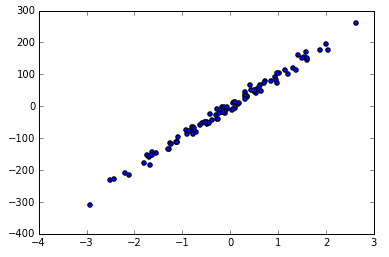
可以看到用函式生成的 Linear Regression 用的資料。
noise 越大的話,點就會越來越離散,例如 noise 由 10 變為 50.