
區域性加權線性迴歸(Locally weighted linear regression)
阿新 • • 發佈:2019-01-29
緊接著之前的問題,我們的目標函式定義為:
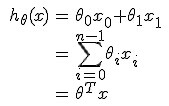
我們的目標是最小化cost function:
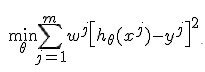
換成線性代數的表述方式:
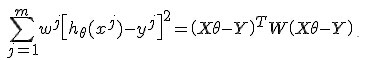

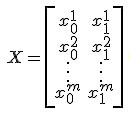
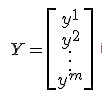


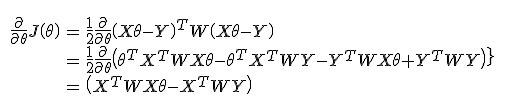
令

有
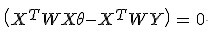
既
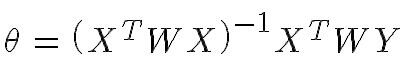
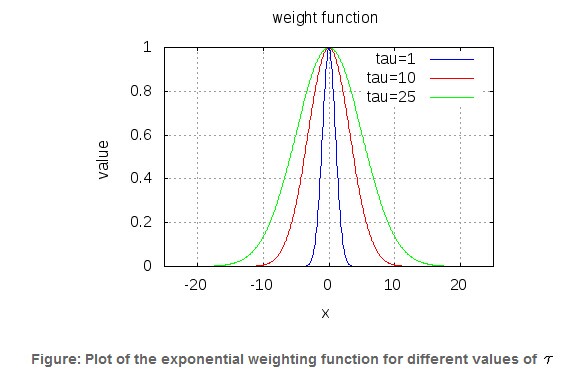
權重定義為:

引數τ控制權重函式的寬度,τ越大,權重函式越寬:
下面給出matlab程式碼
clear ; close all; x = [1:50].'; y = [4554 3014 2171 1891 1593 1532 1416 1326 1297 1266 ... 1248 1052 951 936 918 797 743 665 662 652 ... 629 609 596 590 582 547 486 471 462 435 ... 424 403 400 386 386 384 384 383 370 365 ... 360 358 354 347 320 319 318 311 307 290 ].'; m = length(y); % store the number of training examples x = [ ones(m,1) x]; % Add a column of ones to x n = size(x,2); % number of features theta_vec = inv(x'*x)*x'*y; tau = [1 10 25 ]; y_est = zeros(length(tau),length(x)); for kk = 1:length(tau) for ii = 1:length(x); w_ii = exp(-(x(ii,2) - x(:,2)).^2./(2*tau(kk)^2)); W = diag(w_ii); theta_vec = inv(x'*W*x)*x'*W*y; y_est(kk, ii) = x(ii,:)*theta_vec; end end figure; plot(x(:,2),y,'ks-'); hold on plot(x(:,2),y_est(1,:),'bp-'); plot(x(:,2),y_est(2,:),'rx-'); plot(x(:,2),y_est(3,:),'go-'); legend('measured', 'predicted, tau=1', 'predicted, tau=10','predicted, tau=25'); grid on; xlabel('Page index, x'); ylabel('Page views, y'); title('Measured and predicted page views with weighted least squares');

所以我們有這樣的更新方式:
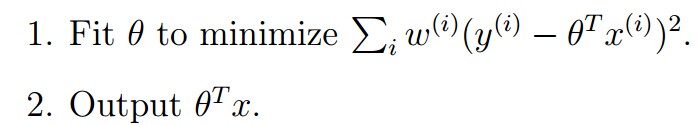
LWR演算法是一個non-parametric(非引數)學習演算法,而線性迴歸則是一個parametric(引數)學習演算法。所謂引數學習演算法它有固定的明確的引數,引數一旦確定,就不會改變了,我們不需要在保留訓練集中的訓練樣本。而非引數學習演算法,每進行一次預測,就需要重新學習一組,是變化的,所以需要一直保留訓練樣本。也就是說,當訓練集的容量較大時,非引數學習演算法需要佔用更多的儲存空間,計算速度也較慢。
區域性權重回歸與線性迴歸的區別可以通過下圖來展示:
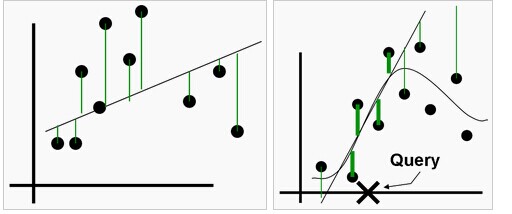
左邊是線性迴歸,右邊是區域性權重回歸