
Caffe中卷積層的實現
作者:xg123321123
宣告:版權所有,轉載請聯絡作者並註明出處
1 簡述
- 使用im2col分別將featrue maps和filter轉換成矩陣;
- 呼叫GEMM(GEneralized Matrix Multiplication)對兩矩陣內積,這樣一來卷積操作就被轉化為了矩陣乘法運算。
- 原理圖如下
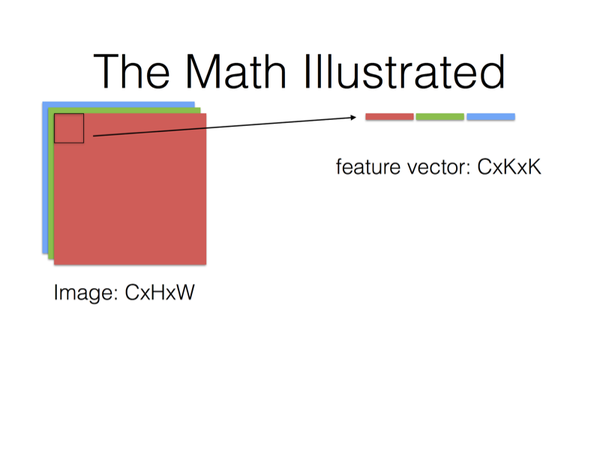
將尺寸為K×K的卷積核在某個位置對應的feature map區域表示為K×K的一維向量;
將feature map各個通道對應的向量之間,串聯起來;
那麼尺寸K×K的卷積核在某個位置對應的各個通道的feature map,組合起來就是長度為C×K×K的一維向量。
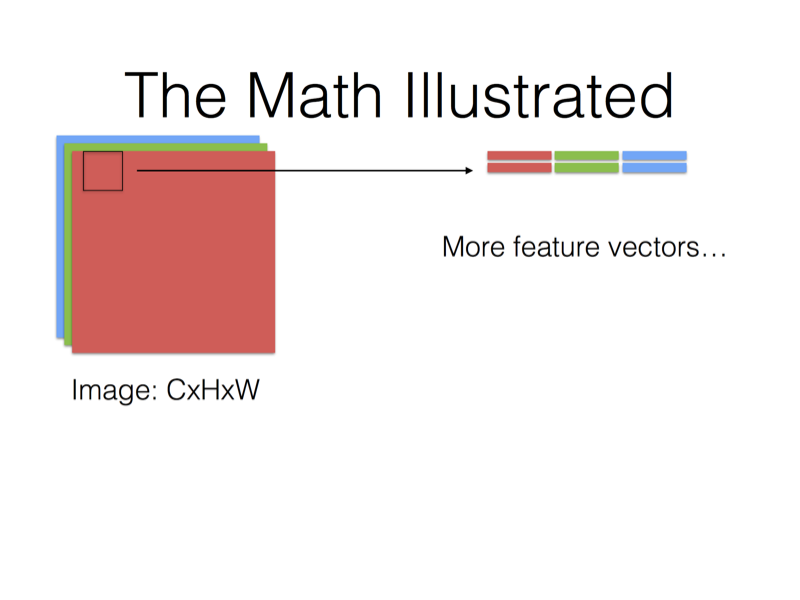
當卷積核對應到新的位置上,又得到新的一維向量。
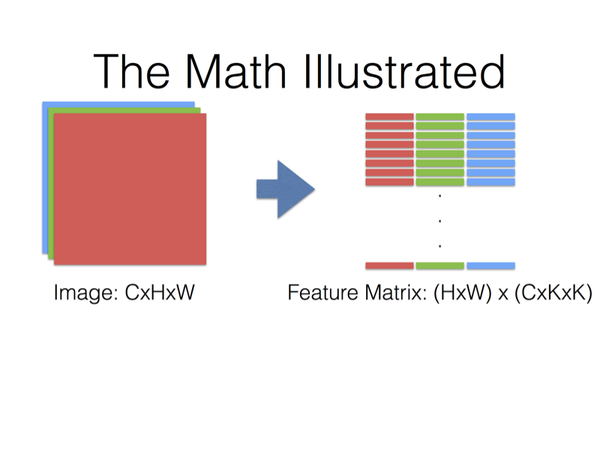
那麼卷積核對應整張圖片的所有位置,就得到一個(H×W)×(C×K×K)的矩陣(假設卷積核每次移動的步數為1)。
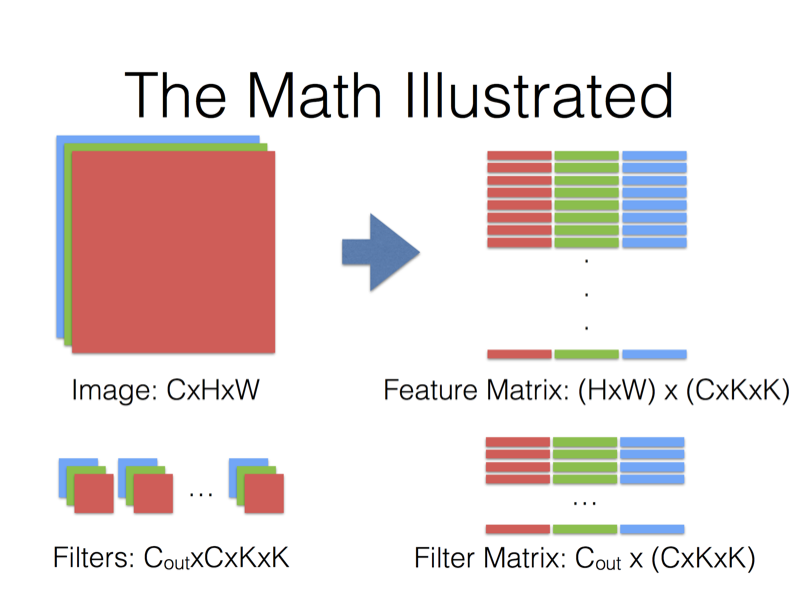
同樣地,將卷積核也表示為一維向量;
用於輸出一個特徵圖的卷積核對應一個C×K×K的一維向量(因為用於輸出同一個特徵圖的卷積核是共享權值的,所以在整張圖的各個位置進行卷積的都是同一個卷積核);
假設要輸出
最後,特徵圖對應矩陣乘以卷積核對應矩陣的轉置,得到輸出矩陣
2 例圖
用下圖舉個例子,請對號入座。
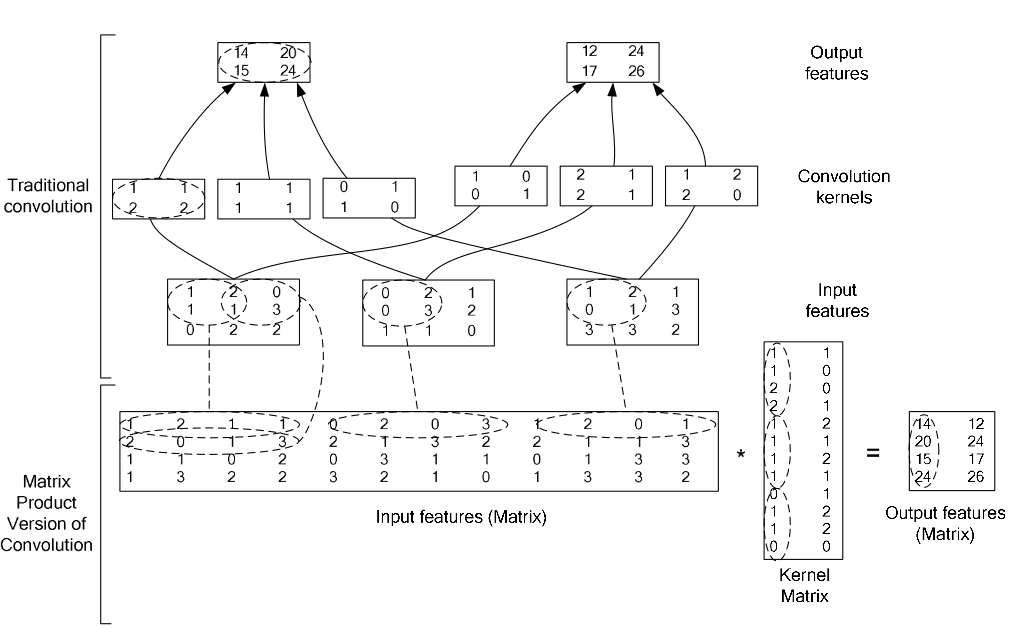
3 靈感來源
之所以要將卷積運算用im2col操作實現,是因為優化CNN中的卷積不是一件簡單的事。
由於時間、成本上的種種原因,caffe作者作用了這樣一種lazy but temporary的方案。
這種方案取得的效果還是比較好的。
詳情見caffe作者吐槽Caffe卷積演算法的連結:Convolution in Caffe: a memo · Yangqing/caffe Wiki · GitHub
4 程式碼實現
ConvolutionLayer 是 BaseConvolutionLayer的子類,BaseConvolutionLayer 是 Layer 的子類。
ConvolutionLayer 除了繼承了相應的成員變數和函式以外,自己的成員函式主要有:compute_output_shape,Forward_cpu 和 Backward_cpu。
compute_output_shape
template <typename Dtype>
void ConvolutionLayer<Dtype>::compute_output_shape() {
this->height_out_ = (this->height_ + 2 * this->pad_h_ - this->kernel_h_)
/ this->stride_h_ + 1; //輸出feature map 的 height
this->width_out_ = (this->width_ + 2 * this->pad_w_ - this->kernel_w_)
/ this->stride_w_ + 1; //輸出 feature map 的 width
}Forward_cpu
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
//blobs_ 用來儲存可學習的引數
//其中blobs_[0]是weight,blobs_[1]是bias
for (int i = 0; i < bottom.size(); ++i) {
//這裡的i為輸入bottom的個數,輸入多少個bottom就產生相應個數的輸出top
const Dtype* bottom_data = bottom[i]->cpu_data();
//這裡cpu_data()一般是指不可改的資料
Dtype* top_data = top[i]->mutable_cpu_data();
//對應地,mutable_cpu_data()一般是指可改的資料
for (int n = 0; n < this->num_; ++n) {
//這裡的n為輸入feature map的個數
this->forward_cpu_gemm(bottom_data + bottom[i]->offset(n), weight,
top_data + top[i]->offset(n));//計算卷積操作之後的輸出
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + top[i]->offset(n), bias);
}//加上bias
}
}
}forward_cpu_gemm
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
// 如果沒有1x1卷積,也沒有skip_im2col
// 則使用conv_im2col_cpu對使用卷積核滑動過程中的每一個kernel大小的影象塊
// 變成一個列向量,其中height=kernel_dim_
// width = 卷積後圖像heght*卷積後圖像width
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
// 使用caffe的cpu_gemm來進行計算
for (int g = 0; g < group_; ++g) {
// 分組分別進行計算
// conv_out_channels_ / group_是每個卷積組的輸出的channel
// kernel_dim_ = input channels per-group x kernel height x kernel width
// 計算的是output[output_offset_ * g] =
// weights[weight_offset_ * g] X col_buff[col_offset_ * g]
// weights的形狀是 [conv_out_channel x kernel_dim_]
// col_buff的形狀是[kernel_dim_ x (卷積後圖像高度乘以卷積後圖像寬度)]
// 所以output的形狀自然就是conv_out_channel X (卷積後圖像高度乘以卷積後圖像寬度)
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ / group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
} forward_cpu_bias
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::forward_cpu_bias(Dtype* output,
const Dtype* bias) {
// output = bias * bias_multiplier_
// num_output 與 conv_out_channel是一樣的
// num_output_ X out_spatial_dim_ = num_output_ X 1 1 X out_spatial_dim_
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num_output_,
out_spatial_dim_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(),
(Dtype)1., output);
} Backward_cpu
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {//propagate_down指是否反傳
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();
if (this->param_propagate_down_[0]) {//param_propagate_down_[0]指weight是否更新
caffe_set(this->blobs_[0]->count(), Dtype(0), weight_diff);
}
if (this->bias_term_ && this->param_propagate_down_[1]) {//param_propagate_down_[1]指bias是否更新
caffe_set(this->blobs_[1]->count(), Dtype(0),
this->blobs_[1]->mutable_cpu_diff());
}
for (int i = 0; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff();//上一層傳下來的導數
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff();//傳給下一層的導數
if (this->bias_term_ && this->param_propagate_down_[1]) {
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff();
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_bias(bias_diff, top_diff + top[i]->offset(n));
}
}
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
if (this->param_propagate_down_[0]) {
this->weight_cpu_gemm(bottom_data + bottom[i]->offset(n),
top_diff + top[i]->offset(n), weight_diff);
}//對weight 計算導數(用來更新weight)
if (propagate_down[i]) {
this->backward_cpu_gemm(top_diff + top[i]->offset(n), weight,
bottom_diff + bottom[i]->offset(n));
}//對bottom資料計算導數(傳給下一層)
}
}
}
}