
歐氏距離和餘弦相似度
阿新 • • 發佈:2019-01-30
兩者相同的地方,就是在機器學習中都可以用來計算相似度,但是兩者的含義有很大差別,以我的理解就是:
前者是看成座標系中兩個點,來計算兩點之間的距離;
後者是看成座標系中兩個向量,來計算兩向量之間的夾角。
前者因為是點,所以一般指位置上的差別,即距離;
後者因為是向量,所以一般指方向上的差別,即所成夾角。
如下圖所示:
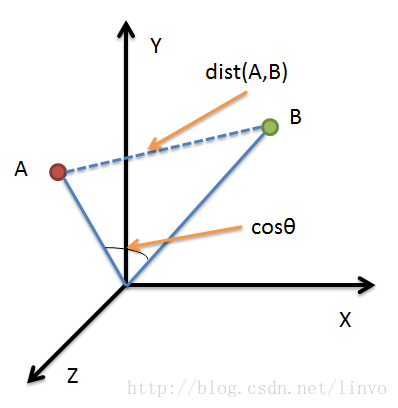
資料項A和B在座標圖中當做點時,兩者相似度為距離dist(A,B),可通過歐氏距離(也叫歐幾里得距離)公式計算:
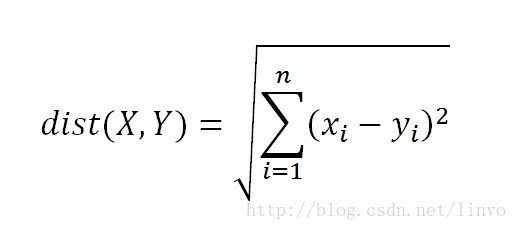
當做向量時,兩者相似度為cosθ,可通過餘弦公式計算:
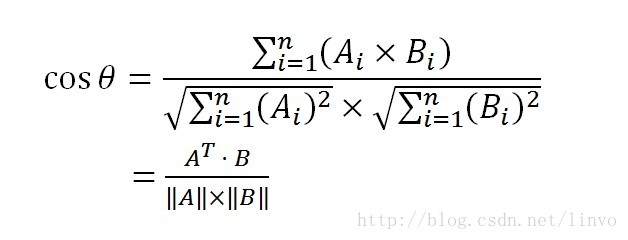
假設||A||、||B||表示向量A、B的2範數,例如向量[1,2,3]的2範數為:
√(1²+2²+3²) = √14
numpy中提供了範數的計算工具:linalg.norm()
所以計算cosθ起來非常方便(假定A、B均為列向量):
num = float(A.T * B) #若為行向量則 A * B.T
denom = linalg.norm(A) * linalg.norm(B)
cos = num / denom #餘弦值
sim = 0.5 + 0.5 * cos #歸一化因為有了linalg.norm(),歐氏距離公式實現起來更為方便:
dist = linalg.norm(A - B)
sim = 1.0 / (1.0 + dist) #歸一化關於歸一化:
因為餘弦值的範圍是 [-1,+1] ,相似度計算時一般需要把值歸一化到 [0,1],一般通過如下方式:
sim = 0.5 + 0.5 * cosθ
若在歐氏距離公式中,取值範圍會很大,一般通過如下方式歸一化:
sim = 1 / (1 + dist(X,Y))
說完了原理,簡單扯下實際意義,舉個栗子吧:
例如某T恤從100塊降到了50塊(A(100,50)),某西裝從1000塊降到了500塊(B(1000,500))
那麼T恤和西裝都是降價了50%,兩者的價格變動趨勢一致,餘弦相似度為最大值,即兩者有很高的變化趨勢相似度
但是從商品價格本身的角度來說,兩者相差了好幾百塊的差距,歐氏距離較大,即兩者有較低的價格相似度
-- EOF --