
感知機3 -- 梯度下降與隨機梯度下降的對比
宣告:
1,本篇為個人對《2012.李航.統計學習方法.pdf》的學習總結,不得用作商用,歡迎轉載,但請註明出處(即:本帖地址)。
2,由於本人在學習初始時有很多數學知識都已忘記,所以為了弄懂其中的內容查閱了很多資料,所以裡面應該會有引用其他帖子的小部分內容,如果原作者看到可以私信我,我會將您的帖子的地址付到下面。
3,如果有內容錯誤或不準確歡迎大家指正。
4,如果能幫到你,那真是太好了。
時間複雜度
1, 這兩個均為線性迴歸問題,於是,線性方程如下:
hθ = θ0 + θ1x1 + θ2
為了方便,上式寫成:
h(x) = θixi = θTx
即:求出θT就求出了h(x)
2, 在看完“隨機梯度下降演算法”和“感知機模型”的總結後我們知道:
為了評估h(x)函式(即:分離超平面)的好壞,我們會使用損失函式來 判斷,而損失函式如下:(下面的n代表秩)
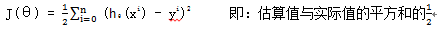
於是,我們需要求出min J(θ)來獲取一個最好的函式h(x)
3, 對於梯度下降演算法:
θj = θj – α(a/aθj
即:下一個更靠近分離超平面的函式 = 上個函式 – 學習速率() * 導數(梯度方向)
為了算出上式,我們先算(a/aθj)J(θ)
(a/aθj)J(θ) = (a/aθj)(hθ(x)- y)2
∵ 對於f(x) = x2,x = g(x) 的導數為 f`(x)g`(x)
∴ 上式繼續等於:
= 2 * (1/2)(hθ(x)- y)(a/aθj)(hθ(x)- y)
= (hθ(x)- y)(a/aθj)(θixi
= (hθ(x)- y)xj
所以:
θj =θj – α(hθ(x)- y)xj
於是當樣本數量為m時:
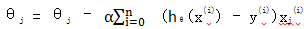
可見,對於n維的向量,其標準梯度下降演算法時間複雜度為 O(mn)
4,隨機梯度下降演算法
還是上面的推導過程,然後在利用之前的總結我們知道:
對於隨機梯度下降演算法,每次僅處理一個數據,演算法如下所示:
Loop {
for i = 1 to m {
θj =θj – α(hθ(x(i))- y(i))xj(i)
}
}
即:每讀取一次樣本,就迭代對θT進行更新,然後判斷其是否收斂,若未收斂,則繼續讀取樣本進行處理,若樣本讀取完畢,則從頭再次迴圈讀取樣本進行處理。
所以,其時間複雜度為O(n).
其他對比
1,由上面的時間複雜度可知:隨機梯度下降演算法趨近最小值的速度更快,不過,它有可能永遠收斂不到最小值,即:在最小值周圍震盪(當然在實踐中大部分無此問題,效果還不錯 ---- 將已知點代入感知機模型後,總會有一些點的值 > 0,一些 < 0 )
2,在標準梯度下降演算法中,權值更新的每一步需對多個樣例求和,需進行更多的計算,而由於其使用真正的梯度,所以其權值的更新進場使用比隨機梯度下降演算法更大的步長。
在隨機梯度下降演算法中,若標準誤差曲面中有多個區域性最小值,那它有可能會陷入這些區域性最小值中。
總結
標準(批量)梯度下降演算法:最小化所有訓練樣本的損失函式,使得最終求得的解為全域性最優解。
即:求解的引數為使風險函式最小。
隨機梯度下降演算法:最小化每條樣本的損失函式,雖然不是每次迭代的方向均向著全域性最優方向,但大的整體方向是全域性最優解的方向,最終結果往往在全域性最優解附近(所以結果可能有多個 ---- Ps:線性支援向量機可解決上例有多個解的問題)。