
seq2seq裡的 attention機制 的 原理 及 程式碼 及 個人理解
阿新 • • 發佈:2019-01-30
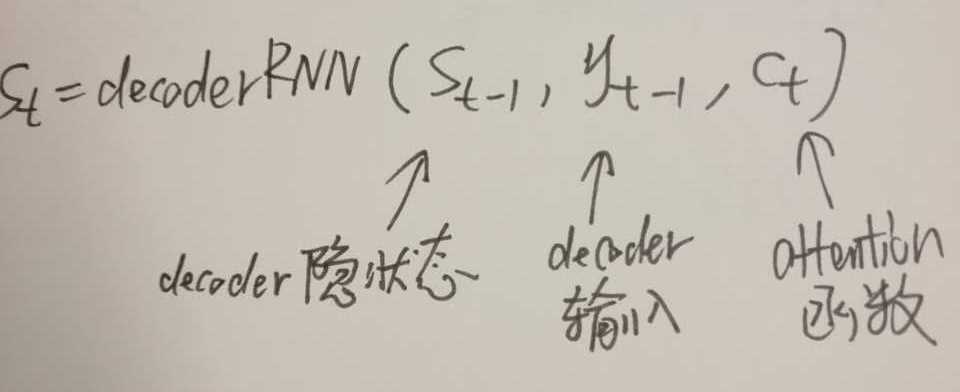
其中

其中
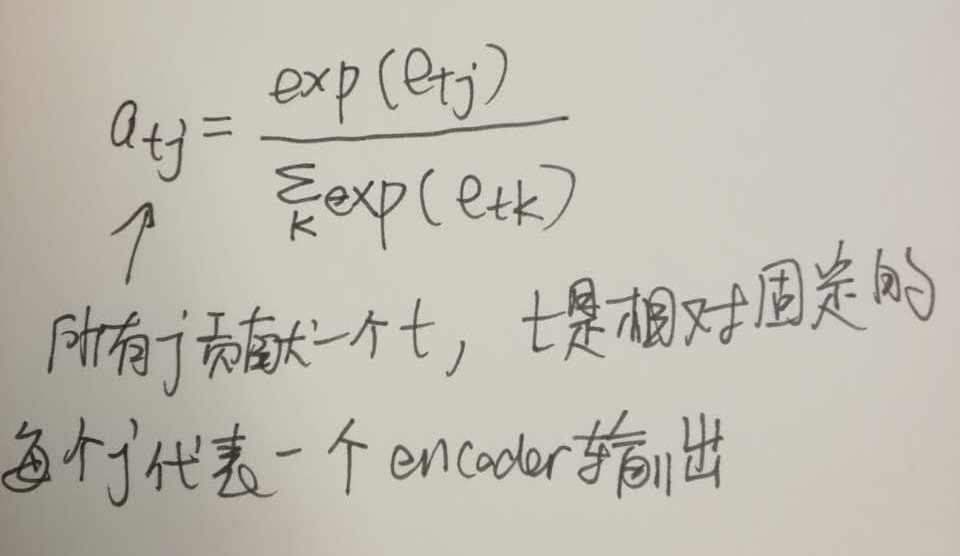
其中

綜合
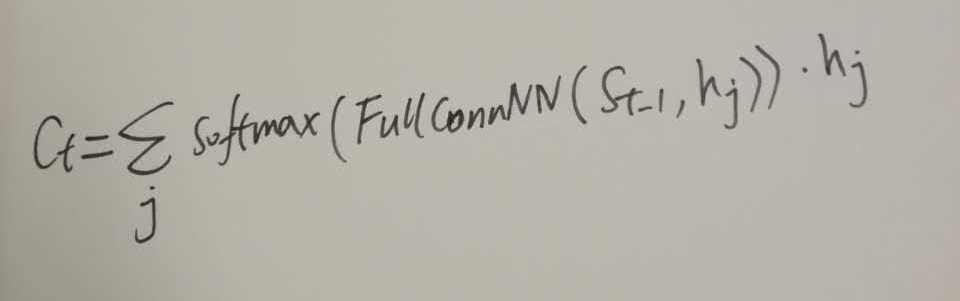
觀察所有輸入的東西,可見是 所有encoder的輸出 和 decoder的每個state 一起作為輸入,攪和在一起,然後target/output就是一個類似score的東西
def attention(self, prev_state, enc_outputs):
"""
Attention model for Neural Machine Translation
:param prev_state: the decoder hidden state at time i-1
:param enc_outputs: the encoder outputs, a length 'T' list.
"""