深度學習基礎系列 (二) 用 sklearn 實現 ID3 演算法
阿新 • • 發佈:2019-02-01
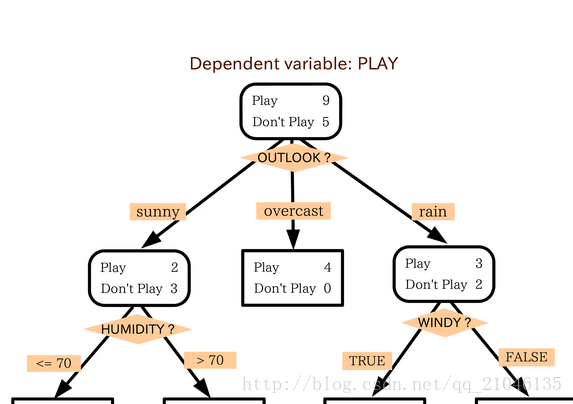
什麼是決策樹/判定樹(decision tree)
判定樹是一個類似於流程圖的樹結構:其中,每個內部結點表示在一屬性上的測試,
每個分支代表一個屬性輸出,而每個樹葉結點代表類或類分佈。樹的頂層是根結點。
熵(entropy)概念
1948年,夏農提出了 ”資訊熵(entropy)“的概念
一條資訊的資訊量大小和它的不確定性有直接的關係,要搞清楚一件非常非常不確定
的事情,或者是我們一無所知的事情,需要了解大量資訊==>資訊量的度量就等於不確
定性的多少
例子:猜世界盃冠軍,假如一無所知,猜多少次?
每個隊奪冠的機率不是相等的
位元(bit)來衡量資訊的多少,變數的不確定性越大,熵也就越大
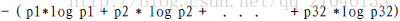
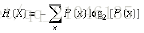
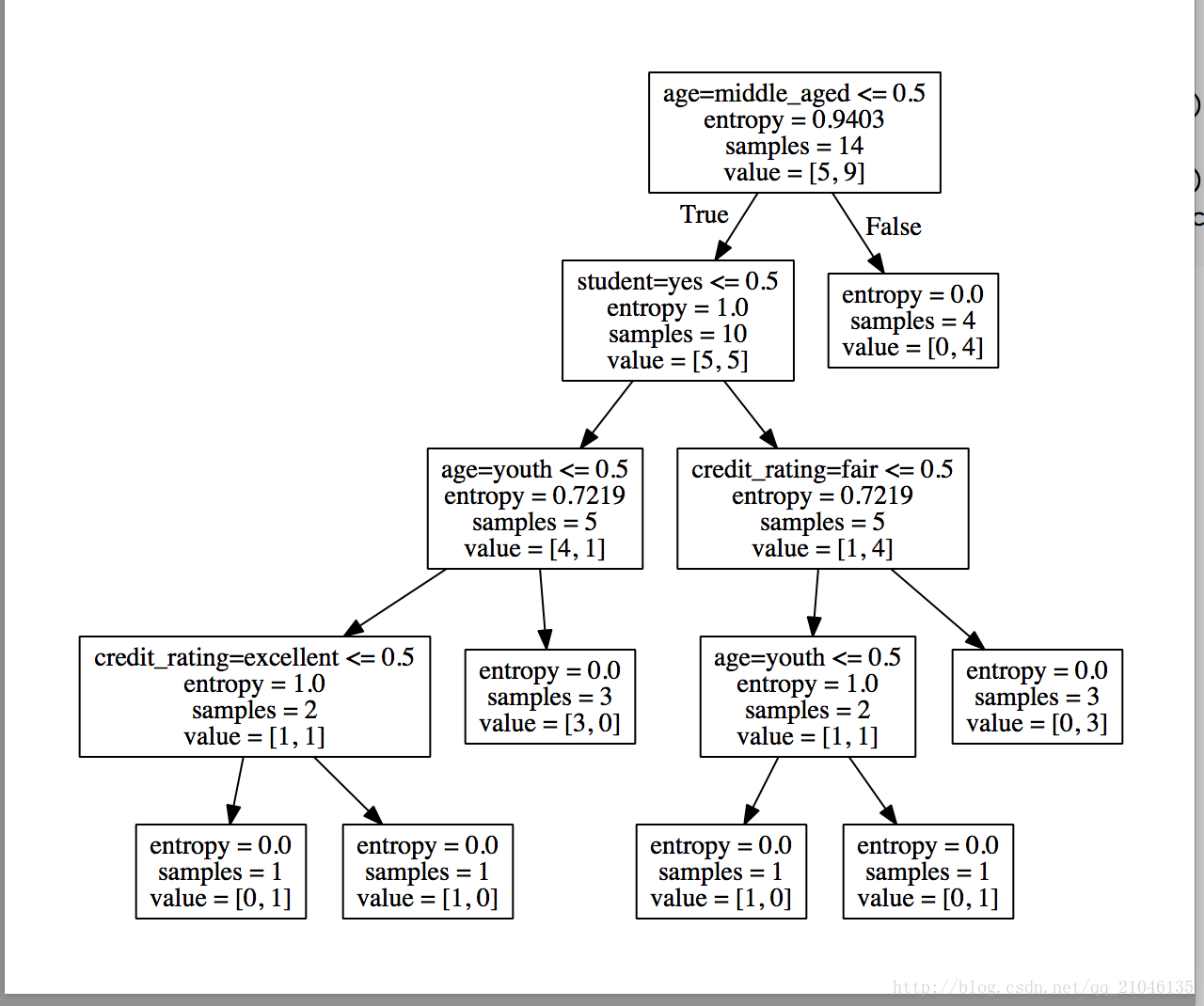
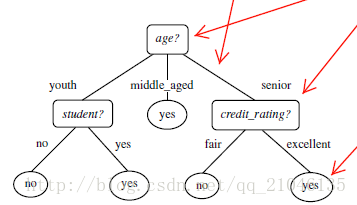
決策樹歸納演算法 (ID3)
選擇屬性判斷結點
資訊獲取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)
通過A來作為節點分類獲取了多少資訊
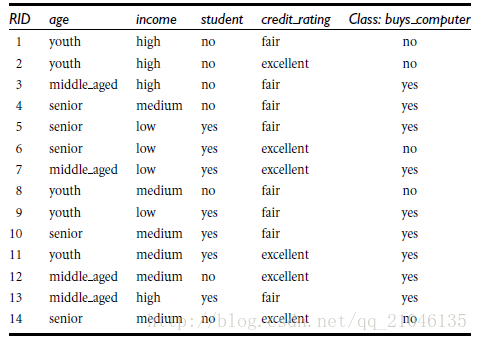
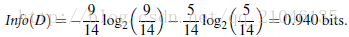
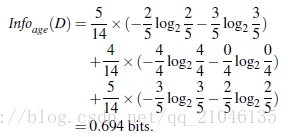
類似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
所以,選擇age作為第一個根節點
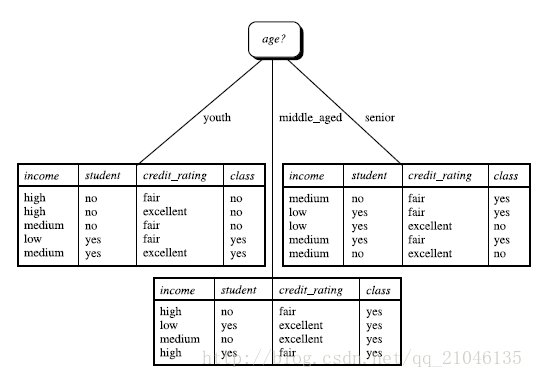
重複上述步驟
決策樹的優點:
直觀,便於理解,小規模資料集有效
決策樹的缺點:
處理連續變數不好
類別較多時,錯誤增加的比較快
可操作規模性一般
用 sklearn 實現
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'/Users/xiaolian/Documents/deeplearning_code/01DTree/AllElectronics.csv' 用 graphviz 開啟 dot 檔案